


安定拡散を使用すると、携帯電話の計算能力のみを使用して画像を生成するのにかかる時間はわずか 12 秒です。
そして、それは 20 回の繰り返しを完了した種類です。

現在の拡散モデルは基本的に 10 億パラメータを超えることを知っておく必要があります。画像を迅速に生成したい場合は、クラウド コンピューティングに依存するか、ローカル ハードウェアを使用する必要があります。十分強力です。
大規模なモデル アプリケーションが徐々に普及するにつれて、パーソナル コンピュータや携帯電話上で大規模なモデルを実行することが、将来的には新しいトレンドとなる可能性があります。
その結果、Google の研究者は、「必要なのは速度だけです: GPU 最適化を通じてデバイス上の大規模拡散モデルの推論速度を加速する」という新しい結果をもたらしました。

この方法は安定拡散用に最適化されていますが、他の拡散モデルにも適用できます。タスクはテキストから画像を生成することです。
具体的な最適化は 3 つの部分に分けることができます:
まず、グループ正規化関数と GELU アクティベーション関数を含む、特別に設計されたカーネルを見てみましょう。
グループ正規化は、UNet アーキテクチャ全体に実装されています。この正規化の動作原理は、特徴マッピングのチャネルを小さなグループに分割し、各グループを独立して正規化することで、グループ正規化がバッチ サイズにあまり依存せず、より広範囲のバッチ サイズとネットワーク アーキテクチャに適応します。
研究者らは、中間テンソルなしで単一の GPU コマンドですべてのカーネルを実行できる GPU シェーダーの形式で独自のカーネルを設計しました。
GELU 活性化関数には、ペナルティ、ガウス誤差関数など、多数の数値計算が含まれています。
専用のシェーダを使用して、これらの数値計算とそれに伴う除算および乗算の演算を統合することで、これらの計算を単純な描画呼び出しに含めることができます。
Draw 呼び出しは、CPU が画像プログラミング インターフェイスを呼び出し、GPU にレンダリングを指示する操作です。
次に、アテンション モデルの効率向上に関して、この論文では 2 つの最適化方法を紹介します。
1 つは、softmax 関数の部分融合です。
大きな行列 A に対してソフトマックス計算全体を実行することを避けるために、この研究では L ベクトルと S ベクトルを計算して計算を削減する GPU シェーダーを設計し、最終的にサイズ N×2 のテンソルが得られます。次に、ソフトマックス計算と行列 V の行列乗算がマージされます。
この方法により、中間プログラムのメモリ フットプリントと全体的なレイテンシが大幅に削減されます。
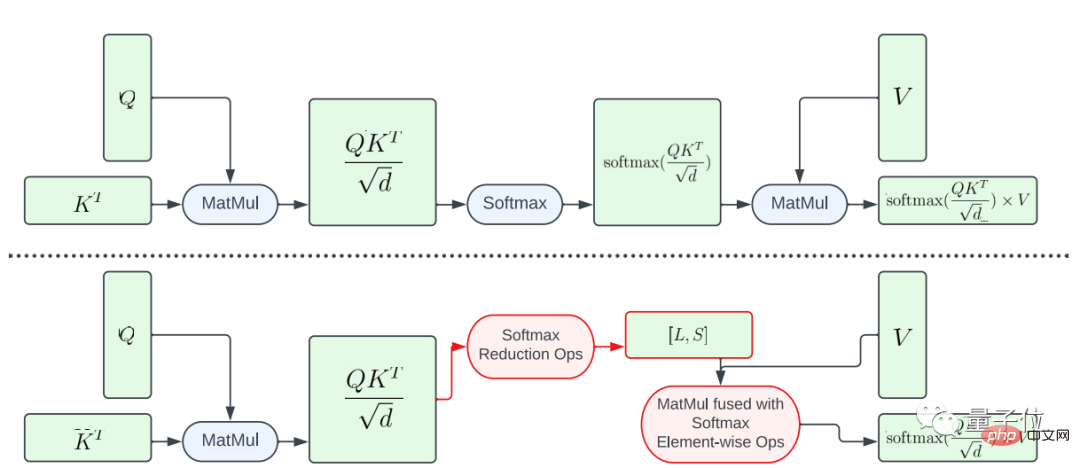
結果テンソルの要素数は要素数よりも小さいため、A から L および S への計算マッピングの並列処理が制限されることを強調する必要があります。入力テンソル A ではさらに多くのことが起こります。
並列性を高め、レイテンシをさらに短縮するために、この研究では A の要素をブロックに編成し、リダクション操作を複数の部分に分割しました。
計算は各ブロックに対して実行され、最終結果が求められます。
慎重に設計されたスレッドとメモリ キャッシュ管理を使用することで、単一の GPU コマンドを使用して複数の部分でレイテンシーの低減を実現できます。
もう 1 つの最適化方法は、FlashAttention です。
これは、昨年普及した IO 認識の正確なアテンション アルゴリズムです。具体的な高速化テクノロジには 2 つあります: ブロックでの増分計算、つまりタイリングと、すべてのアテンションを操作するためのバックワード パスでのアテンションの再計算です。 CUDA カーネルに統合されています。
標準のアテンションと比較して、この方法は HBM (高帯域幅メモリ) アクセスを削減し、全体的な効率を向上させることができます。
ただし、FlashAttendant コアはレジスターへの負荷が非常に高いため、チームはこの最適化方法を選択的に使用しています。
Adreno GPU と Apple GPU ではアテンション行列 d=40 で FlashAttend を使用し、その他の場合には部分融合ソフトマックス関数を使用します。
3 番目の部分は、Winograd 畳み込みアクセラレーションです。
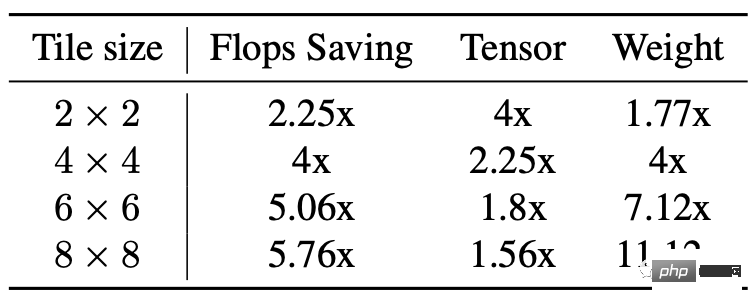
その原理は単純に、より多くの加算計算を使用して乗算計算を減らし、それによって計算量を削減することです。
しかし、欠点も明らかであり、特にタイルが比較的大きい場合、ビデオ メモリの消費量が増加し、数値エラーが発生します。
安定拡散のバックボーンは 3x3 畳み込み層に大きく依存しており、特に画像デコーダでは層の 90% が 3x3 畳み込み層で構成されています。
分析の結果、研究者らは、4×4 サイズのタイルを使用するときが、モデルの計算効率とビデオ メモリの使用率の最適なバランス ポイントであることを発見しました。
改善効果を評価するために、研究者らはまず携帯電話でベンチマークテストを実施しました。
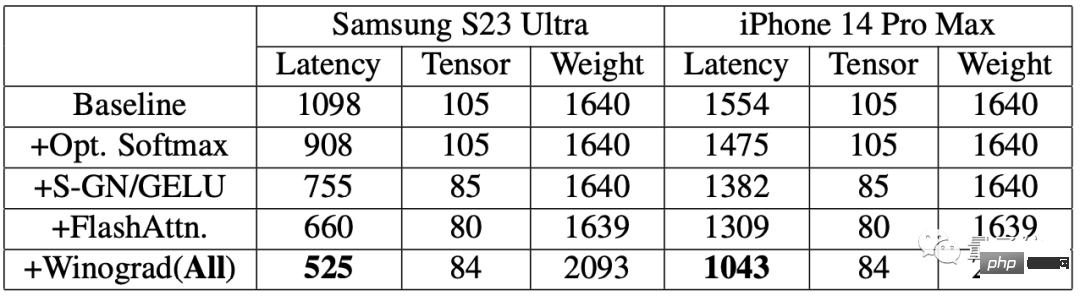
#結果は、加速アルゴリズムを使用した後、両方の携帯電話で画像生成の速度が大幅に向上したことを示しています。
その中で、Samsung S23 Ultra の遅延は 52.2% 減少し、iPhone 14 Pro Max の遅延は 32.9% 減少しました。
Samsung S23 Ultra でテキストから 512 × 512 ピクセルの画像をエンドツーエンドで生成します。反復回数は 20 回で、所要時間は 12 秒未満です。
紙のアドレス: //m.sbmmt.com/link/ba825ea8a40c385c33407ebe566fa1bc
以上がAIが携帯電話上で12秒以内にペイントを完了! Google、拡散モデル推論を高速化する新しい方法を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



