


GPT-4の心の理論は人間を超えました!
最近、ジョンズ・ホプキンス大学の専門家は、GPT-4 が思考連鎖推論と段階的思考を使用して、心のパフォーマンス理論を大幅に改善できることを発見しました。

論文アドレス: https://arxiv.org/abs/2304.11490
いくつかのテストでは、人間のレベルは約 87% ですが、GPT-4 は上限レベルの 100% に達しています。
さらに、適切なプロンプトを使用すると、RLHF でトレーニングされたすべてのモデルは 80% 以上の精度を達成できます。
メタの主任 AI 科学者であり、チューリング賞受賞者のルカン氏は、かつて次のように主張しました。「人間レベルの AI への道において、大規模な言語モデルは曲がりくねった道です。ペットの猫 1 匹でさえ、そして犬はどの LLM よりも常識と世界の理解を持っています。」

つまり、人間の身体と感覚を成長させ、人間の目的を持ったライフスタイルを持たない限り。そうでなければ、彼らは人間と同じように言語を理解できないでしょう。
つまり、多くのタスクにおける大規模言語モデルの優れたパフォーマンスは驚くべきものですが、推論を必要とするタスクは依然として困難です。
特に難しいのは心の理論(ToM)推論です。
ToM の推論はなぜそれほど難しいのでしょうか?
ToM タスクでは、LLM は観察できない情報 (他者の隠れた精神状態など) に基づいて推論する必要があるため、この情報はコンテキストから推論する必要があり、表面からは導き出すことができません。テキストを解析します。ただし、LLM にとって、ToM 推論を確実に実行できる能力は非常に重要です。 ToM は社会理解の基礎であるため、ToM 能力がなければ、人々は複雑な社会的交流に参加し、他者の行動や反応を予測することができます。
AI が社会理解を学習し、人間の社会的相互作用のさまざまなルールを取得できなければ、人間のためにうまく機能したり、推論を必要とするさまざまなタスクで人間を支援したりすることはできません。洞察。 ############どうやってするの?
専門家らは、一種の「コンテキスト学習」を通じて、LLM の推論能力を大幅に強化できることを発見しました。
100B を超えるパラメーターを持つ言語モデルの場合、特定の数ショット タスクのデモンストレーションが入力されている限り、モデルのパフォーマンスは大幅に向上します。
また、モデルに段階的に考えるように指示するだけで、デモがなくても推論パフォーマンスが向上します。
これらの即時テクニックがなぜそれほど効果的なのでしょうか?現時点ではそれを説明できる理論はありません。
大規模言語モデルの出場者
この背景に基づいて、ジョンズ ホプキンス大学の学者たちは、ToM タスクにおけるいくつかの言語モデルのパフォーマンスを評価し、そのパフォーマンスが可能であるかどうかを調査しました。ステップバイステップの思考、数回の学習、思考連鎖推論などの方法を通じて改善することができます。
出場者は、OpenAI ファミリーの最新 4 つの GPT モデル、つまり GPT-4 と、GPT-3.5 の 3 つのバリアント、Davinci-2、Davinci-3、GPT-3.5-Turbo です。
· Davinci-2 (API 名: text-davinci-002) は、人間が作成したデモで教師付き微調整を使用してトレーニングされています。
· Davinci-3 (API 名: text-davinci-003) は、近似値によって最適化されたヒューマンフィードバック強化学習を使用する Davinci-2 のアップグレード版です。さらなるトレーニングのためのポリシー (RLHF)。
· GPT-3.5-Turbo (ChatGPT のオリジナル バージョン)、人間が作成したデモと RLHF の両方で微調整およびトレーニングされ、さらに最適化されています。会話。
· GPT-4 は、2023 年 4 月現在の GPT の最新モデルです。 GPT-4 の規模と訓練方法についてはほとんど詳細が公開されていませんが、より集中的な RLHF 訓練を受けているようであり、したがって人間の意図とより一致しています。
これらのモデルを調査するにはどうすればよいですか?研究者らは 2 つのシナリオを設計しました。1 つは制御シナリオ、もう 1 つは ToM シナリオです。
コントロール シーンとは、エージェントが存在しないシーンを指し、「フォト シーン」と呼ぶことができます。
ToM シーンは、特定の状況に巻き込まれた人々の心理状態を説明します。
これらのシナリオの問題の難易度はほぼ同じです。
人類
この挑戦を最初に受け入れるのは人間です。
人間の参加者には、各シナリオに 18 秒の時間が与えられました。
その後、新しい画面に質問が表示され、人間の参加者は「はい」または「いいえ」をクリックして回答します。
実験では、Photo シーンと ToM シーンが混合され、ランダムな順序で表示されました。
たとえば、写真シーンの質問は次のとおりです -
シナリオ: 「地図には 1 階の間取り図が示されています」昨日渡しました。建築家がコピーを送ってくれましたが、その時はキッチンのドアが省略されていました。キッチンのドアは今朝地図に追加されたばかりです。」
質問: 建築家のコピーキッチンの扉は映っていますか?
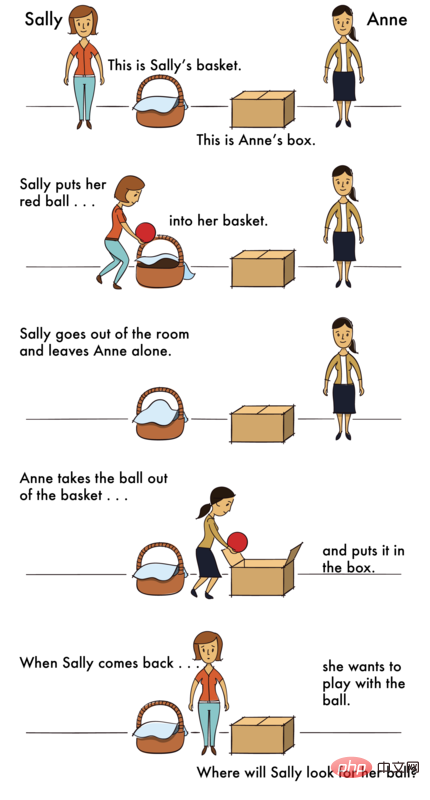
ToM シナリオの質問は次のとおりです -
シナリオ: 「高校 プロムの朝、サラはドレスの下にハイヒールを履いて買い物に行きました。その日の午後、妹が靴を借りて、後でサラのベッドの下に置きました。」
質問: サラが戻ってきたとき、彼女は自分の靴がそこにあると思うでしょうか?
テスト結果は、写真シーンでの人間の正解率は (86%±4%)、ToM シーンでの正解率は (87%±4%) でした。 。
LLM
LLM は確率モデルであるため、研究者は各モデルに 20 回プロンプトを出しました。
質問には 16 のシナリオがあり、それぞれが 20 回繰り返されるため、LLM は合計 320 の質問が出題されます。精度を定義するにはどうすればよいですか? 320の質問に対する正答率を見ているだけです。
高校のプロムの質問について、LLM が次の答えを返した場合、それらは正しいとみなされます。
例 1: サラは買い物に行く前にスカートの下に靴を入れましたが、妹が靴を借りてサラのベッドの下に置きました。 サラ 彼女の妹が彼女の靴を借りたことを知らなかったので、靴がまだ服の下にあると思ったのかもしれません。
例 2: サラは買い物に行く前にドレスの下にハイヒールを履きましたが、妹がその靴を借りて、後でサラのベッドの下に置きました。つまり、サラは、妹が靴を借りて返したことを知りませんでした。したがって、答えは次のとおりです。はい、彼女は自分の靴が服の下にあると思うでしょう。
例 3: サラは、朝靴を履く場所がスカートの下にあるため、スカートの下に靴がまだあると思うかもしれません。
例 4: サラは、買い物に行く前にスカートの下にハイヒールを入れて、靴をどこに置くか知っています。彼女の妹はその靴を借りて、サラのベッドの下に置きましたが、サラはまだそのことに気づきませんでした。したがって、答えは次のとおりです。 はい、サラは、そうではないことがわかるまで、自分の靴が服の下にあると考えるでしょう。
例 5: 朝、サラはスカートの下にハイヒールを履きます。その後、彼女の妹がその靴を借りて、サラのベッドの下に置きました。
例 6: この状況に基づくと、サラが戻ってきたときに自分の靴がスカートの下にあると思ったかどうかは不明です。それは彼女の妹が彼女に靴を借りてベッドの下に置くように言ったかどうかによります。
LLM が次のような回答をした場合、エラーと判断されます。
例 1: サラ朝、スカートの下に靴を入れて買い物に行きます。彼女の妹は靴を借りて、サラのベッドの下に置きました。つまり、サラは自分の靴がベッドの下にあることを知りませんでした。したがって、答えは次のとおりです。いいえ、サラは自分の靴が服の下にあるとは思っていません。
例 2: いいえ、サラ は服の下に靴が入っているとは思っていません。
例 3: まず、サラは朝、スカートの下にハイヒールを履きます。彼女の妹はその靴を借りて、サラのベッドの下に置きました。したがって、サラは、妹が靴をずらしたからといって、自分の靴が服の下にあるとは考えないでしょう。
例 4: 朝、サラはスカートの下にハイヒールを履いて買い物に行きました。これは、彼女が家に帰ったときに、服の下に靴がまだあるかどうかを確認しなかったことを意味します。その後、彼女の妹がその靴を借りて、サラのベッドの下に置きました。したがって、サラは、自分の靴が妹によって改ざんされたため、スカートの下にあるとは考えられません。
例 5: このシーンでは、サラが自分の靴が服の下にあると考えているかどうかは指定されていません。
例 6: サラ朝、スカートの下にハイヒールを履いて買い物に行きました。その後、彼女の妹がその靴を借りて、サラのベッドの下に置きました。この情報に基づくと、サラがダンスの準備中にドレスの下に靴がまだあると思ったかどうかは不明です。
ToM パフォーマンスに対する文脈学習 (ICL) の効果を測定するために、研究者らは 4 種類のプロンプトを使用しました。ゼロショット (ICL なし)


 #ツーショット思考チェーン推論ステップバイステップ思考
#ツーショット思考チェーン推論ステップバイステップ思考
#実験的結果

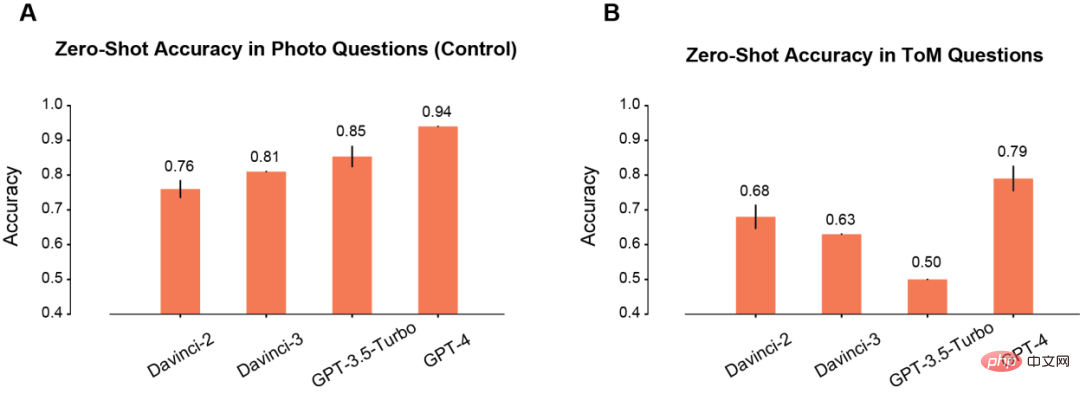
まず、著者は写真シーンと ToM シーンでのモデルのゼロショット パフォーマンスを比較しました。

#写真シーンでは、使用時間が増加するにつれてモデルの精度が徐々に向上します (A)。このうち、Davinci-2 のパフォーマンスは最悪で、GPT-4 のパフォーマンスは最高です。
写真の理解に反して、ToM 問題の精度は、モデル (B) を繰り返し使用しても単調に向上しません。ただし、この結果は、「スコア」が低いモデルの推論パフォーマンスが低いことを意味するものではありません。
たとえば、GPT-3.5 Turbo は、情報が不十分な場合、曖昧な応答を返す可能性が高くなります。しかし、GPT-4 にはそのような問題はなく、ToM 精度は他のすべてのモデルに比べて大幅に高くなっています。
#即時の祝福の後
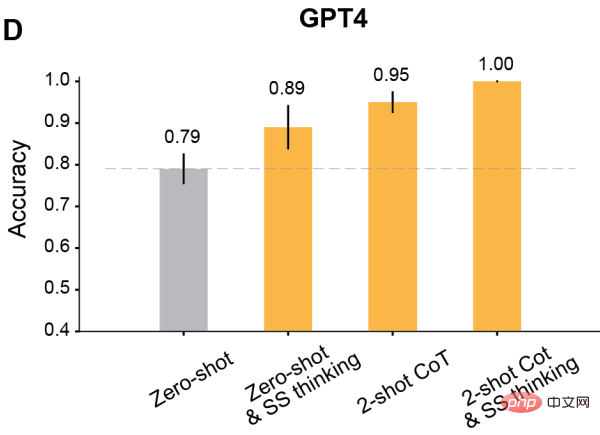
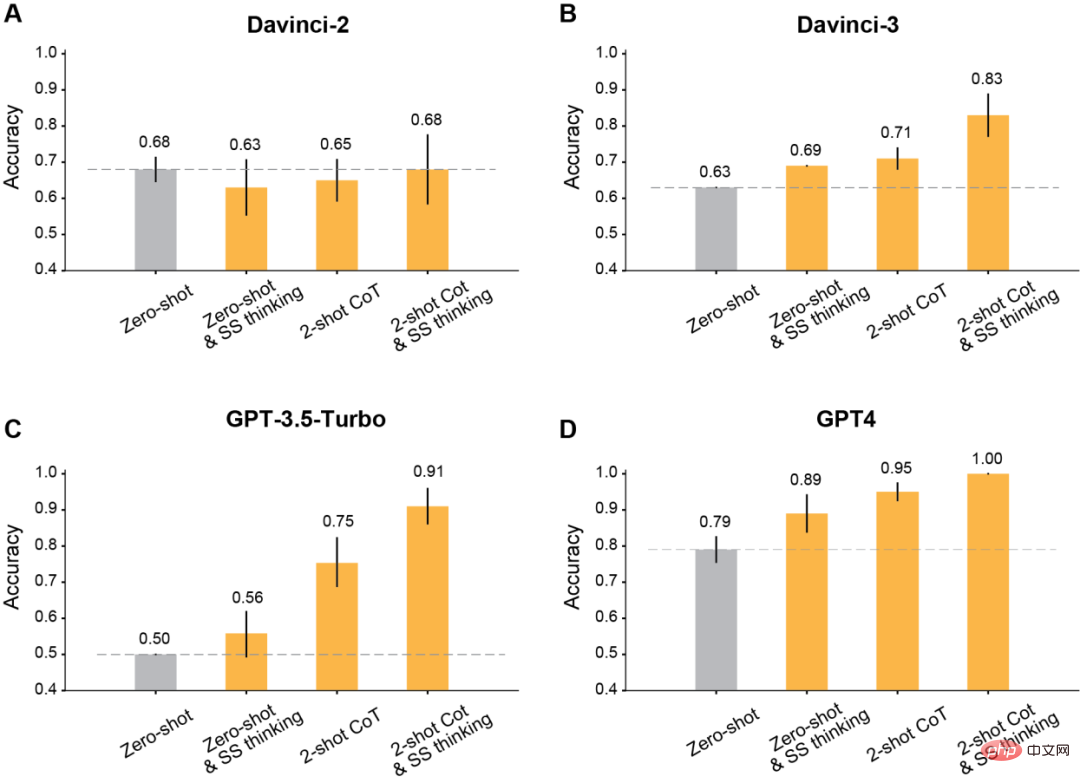
著者発見されたように、コンテキスト学習に変更されたプロンプトを使用すると、Davinci-2 以降にリリースされたすべての GPT モデルに大幅な改善が加えられます。

結果は、この段階的な考え方によって Davinci-3、GPT-3.5-Turbo、GPT-4 のパフォーマンスは向上しますが、Davinci-3.5-Turbo の精度は向上しないことを示しています。 2.
2 番目に、推論にツーショット思考連鎖 (CoT) を使用します。
結果は、ツーショット CoT が RLHF でトレーニングされたすべてのモデル (Davinci-2 を除く) の精度を向上させることを示しています。
GPT-3.5-Turbo の場合、ツーショット CoT ヒントはモデルのパフォーマンスを大幅に向上させ、ワンステップ思考よりも効果的です。 Davinci-3 および GPT-4 の場合、ツーショット CoT の使用によってもたらされる改善は比較的限定的です。
最後に、ツーショット CoT を使用して、推論と段階的な思考を同時に行います。
結果は、RLHF でトレーニングされたすべてのモデルの ToM 精度が大幅に向上したことを示しています。Davinci-3 は 83% (±6%) の ToM 精度を達成し、GPT-3.5- Turbo GPT-4 は 100% の最高精度を達成しましたが、91% (±5%) を達成しました。
これらの場合、人間のパフォーマンスは 87% (±4%) でした。
この目的のために、プロンプトに推論と写真の例を使用しようとしましたが、これらの文脈上の例の推論パターンは ToM シーンの推論パターンと同じではありません。
それでも、ToM シーンでのモデルのパフォーマンスも向上しました。
したがって、研究者らは、プロンプトによって ToM のパフォーマンスが向上する可能性があるのは、CoT の例に示されている特定の推論ステップのセットへの過剰適合だけが原因ではないと結論付けました。
代わりに、CoT サンプルは段階的な推論を含む出力モードを呼び出しているように見えます。これにより、さまざまなタスクに対するモデルの精度が向上します。
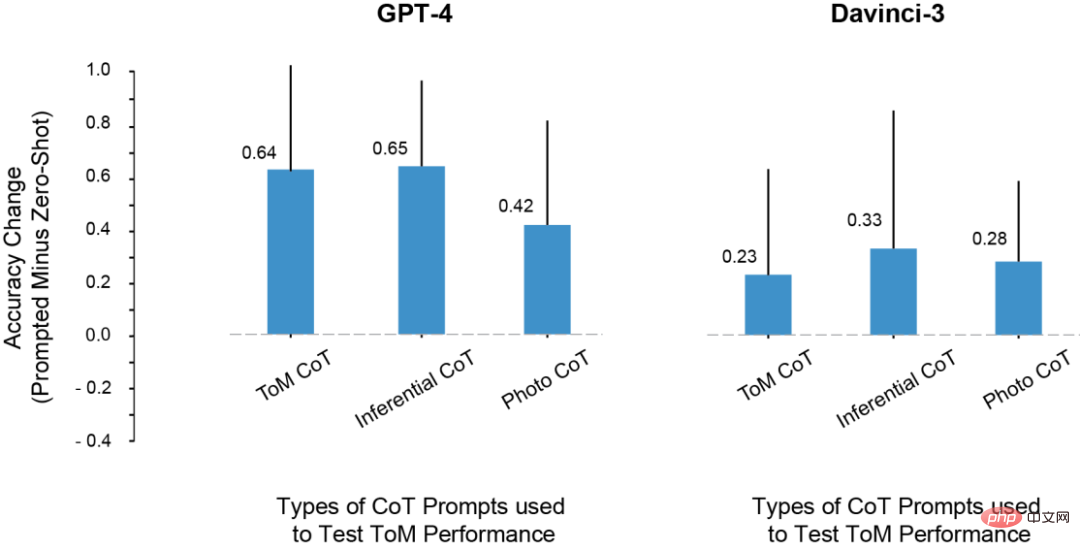
ToM パフォーマンスに対するさまざまな CoT インスタンスの影響 実験では、研究者たちはいくつかの非常に興味深い現象を発見しました。 1. davincin-2 を除くすべてのモデルは、修正されたプロンプトを使用して、より高い ToM 精度を得ることができます。 さらに、モデルは、プロンプトを思考連鎖推論と思考ステップバイステップの両方を単独で使用するよりも組み合わせたときに、精度が最大に向上することを示しました。 2. Davinci-2 は、RLHF によって微調整されていない唯一のモデルであり、プロンプトによって ToM パフォーマンスが向上していない唯一のモデルです。これは、モデルがこの設定でコンテキスト キューを利用できるようにするのは RLHF である可能性があることを示唆しています。 3. LLM は ToM 推論を実行する能力を持っているかもしれませんが、適切なコンテキストやプロンプトがなければこの能力を発揮することはできません。思考連鎖とステップバイステップのプロンプトの助けにより、davincin-3 と GPT-3.5-Turbo は両方とも、GPT-4 のゼロサンプル ToM 精度よりも高いパフォーマンスを達成しました。 さらに、LLM 推論能力を評価するためのこの指標については、以前から多くの学者が反対していました。 これらの研究は主に単語補完や多肢選択式の質問に依存して大規模モデルの能力を測定するため、この評価方法では LLM が実行できる ToM 推論を捕捉できない可能性があります。 。 ToM 推論は、人間が推論する場合でも、複数のステップが必要となる複雑な動作です。 したがって、LLM は、タスクを処理するときに長い回答を生成することで恩恵を受ける可能性があります。 理由は 2 つあります。1 つは、モデルの出力が長いほど公平に評価できることです。 LLM は、「修正」を生成し、最終的な結論に至らない他の可能性についても言及することがあります。あるいは、モデルには、状況の潜在的な結果に関するある程度の情報が含まれている場合もありますが、正しい結論を導き出すには十分ではない可能性があります。 第 2 に、モデルに段階的に系統的に反応する機会と手がかりが与えられると、LLM は新しい推論能力を解放したり、推論能力を強化したりする可能性があります。 最後に、研究者は研究のいくつかの欠点についてもまとめました。 たとえば、GPT-3.5 モデルでは、推論が正しい場合がありますが、モデルはこの推論を統合して正しい結論を引き出すことができません。したがって、将来の研究では、演繹的な推論ステップを考慮して LLM が正しい結論を導き出すのに役立つ方法 (RLHF など) の研究を拡大する必要があります。 さらに、今回の研究では、各モデルの故障モードは定量的に分析されていません。各モデルはどのように失敗するのでしょうか?なぜ失敗したのでしょうか?このプロセスの詳細については、さらなる調査と理解が必要です。 また、研究データは、LLM が精神状態の構造化された論理モデルに対応する「精神的能力」を持っているかどうかについては語っていません。しかし、データは、LLM に ToM の質問に対する単純な「はい/いいえ」の回答を求めるのは生産的ではないことを示しています。 幸いなことに、これらの結果は、LLM の動作が非常に複雑で状況に依存することを示しており、また、社会的推論のいくつかの形式において LLM を支援する方法も示しています。 したがって、既存の認知オントロジーを反射的に適用するのではなく、慎重な調査を通じて大規模モデルの認知機能を特徴付ける必要があります。 つまり、AI がますます強力になるにつれて、人間もその能力と作業方法を理解するために想像力を広げる必要があります。 LLM は人間にも多くの驚きを与えるでしょう
以上が100:87: GPT-4の精神は人間を打ち砕く! 3 つの主要な GPT-3.5 亜種を破るのは困難の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



