


ChatGPT には「ヒューマン フィードバック強化学習 (RLHF)」と呼ばれる核となるトレーニング方法があります。
これにより、モデルがより安全になり、出力結果が人間の意図とより一致するようになります。
Google Research と UC Berkeley の研究者らは、AI ペイントでこの方法を使用すると、画像が入力と完全に一致しない状況を「処理」でき、その効果も驚くほど良好であることを発見しました—
最大 47% の改善が達成できます。

現時点では、AIGC分野で人気の2つのモデルが見つかったようですある種の「共鳴」。
RLHF、正式名は「Reinforcement Learning from Human Feedback」で、2017 年に OpenAI と DeepMind が共同開発した強化学習テクノロジーです。
名前が示すように、RLHF はモデルの出力結果 (つまりフィードバック) を人間が評価してモデルを直接最適化します。LLM では、「モデルの値」を人間の値とより一致させることができます。
AI 画像生成モデルでは、生成された画像をテキスト プロンプトと完全に一致させることができます。
具体的には、まず人間のフィードバックデータを収集します。
ここで、研究者らは合計 27,000 を超える「テキストと画像のペア」を生成し、何人かの人間にそれらを採点するように依頼しました。
わかりやすくするために、テキスト プロンプトには、量、色、背景、ブレンド オプションに関連する次の 4 つのカテゴリのみが含まれます。人間のフィードバックは、「良い」、「悪い」、「しない」の 3 つのみに分類されます。知っています(スキップ)" "。

2 番目に、報酬関数を学習します。
このステップでは、取得した人間の評価で構成されるデータセットを使用して報酬関数をトレーニングし、この関数を使用してモデルの出力に対する人間の満足度を予測します (式の赤い部分)。
このようにして、モデルは結果がテキストとどの程度一致するかを認識します。
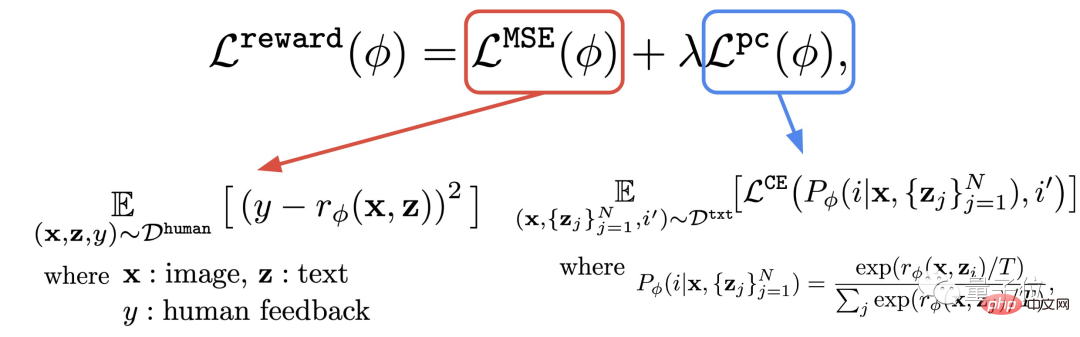
#報酬関数に加えて、著者は補助タスク (式の青い部分) も提案しています。
つまり、画像生成が完了した後、モデルは大量のテキストを提供しますが、元のテキストはそのうちの 1 つだけであり、画像が一致するかどうかを報酬モデルに「自らチェック」させます。文章。
この逆の操作により、効果を「二重の保険」にすることができます (下図のステップ 2 を理解するのに役立ちます)。
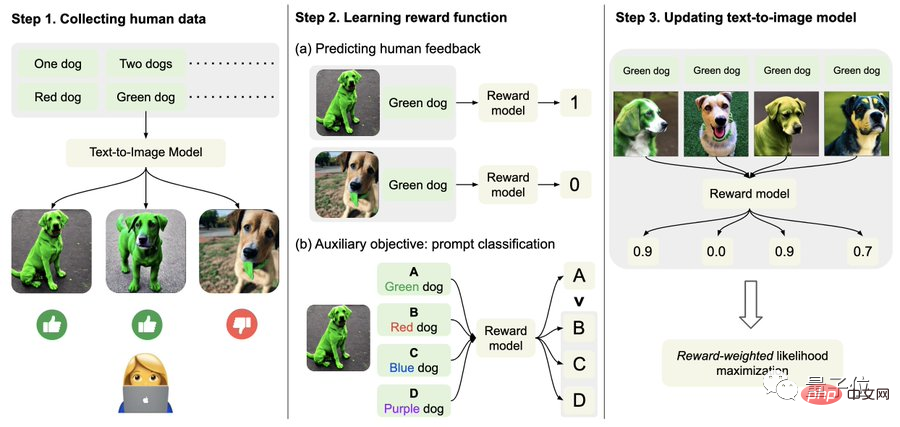
最後に、微調整です。
つまり、テキスト画像生成モデルは、報酬重み付け尤度最大化 (以下の式の最初の項目) を通じて更新されます。
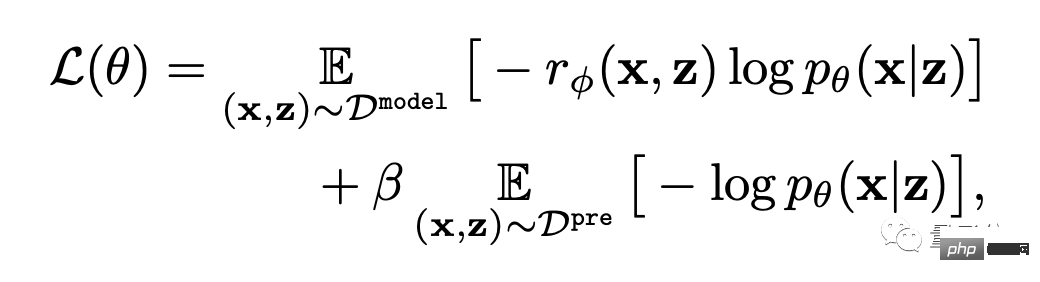
#過学習を避けるために、作成者はトレーニング前のデータセットの NLL 値 (式の第 2 項) を最小化しました。このアプローチは、structGPT (ChatGPT の「直接の前身」) に似ています。
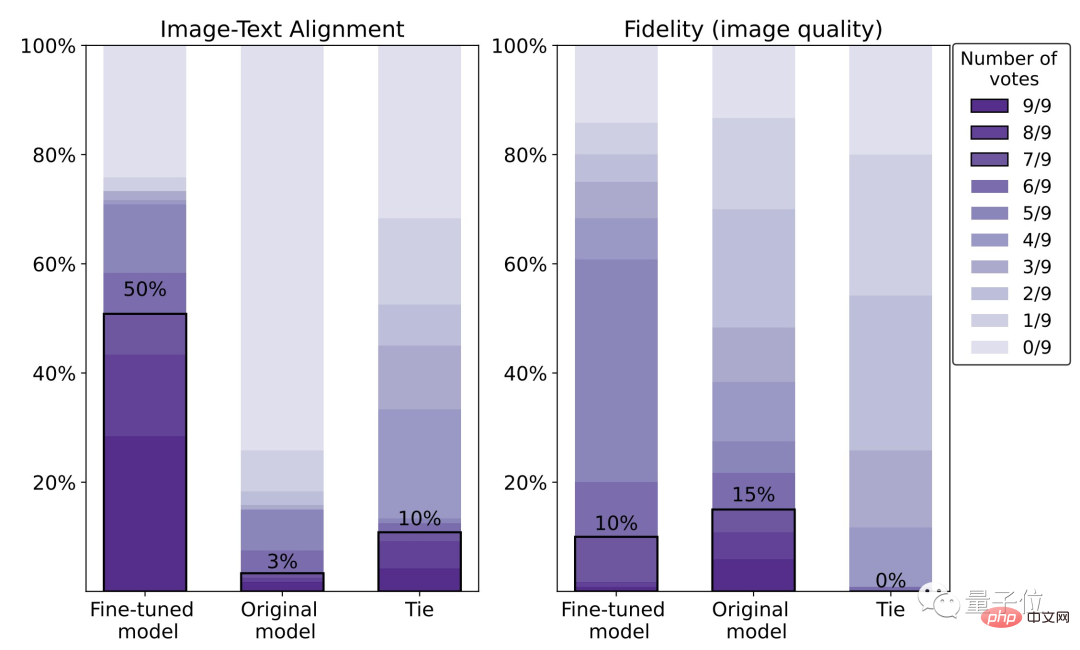
次の一連のエフェクトに示すように、元の安定した拡散と比較して、RLHF で微調整されたモデルは、 :
(1) テキスト内の「two」と「green」をより正確に理解します;

(2) ではありません「海」を無視する 背景要件として;
(3) 赤いタイガーが必要な場合は、「より赤い」結果が得られます。
具体的なデータから判断すると、微調整モデルの人間の満足度は 50% で、元のモデル (3%) と比較して 47% 向上しています。
ただし、その代償として画像の鮮明さが 5% 失われます。
下の写真からも、右側のオオカミが左側のオオカミよりも明らかにぼやけていることがわかります。
はい したがって、著者らは、より大規模な人による評価データセットとより優れた最適化 (RL) 手法を使用することで状況を改善できる可能性があると示唆しています。
この記事の著者は合計 9 名です。

韓国科学技術研究院の Google AI 研究科学者 Kimin Lee 博士は、カリフォルニア大学バークレー校で博士研究員として研究を実施しました。

中国人著者は 3 人です:
Liu Hao カリフォルニア大学バークレー校の博士課程の学生で、主な研究対象はフィードバック ニューラルです。ネットワーク。
Du Yuqing はカリフォルニア大学バークレー校の博士課程候補者で、主な研究方向は教師なし強化学習法です。
責任著者のShixiang Shane Gu (Gu Shixiang) は、学部の学位を三大巨人の一人であるヒントンに師事し、ケンブリッジ大学を卒業して博士号を取得しました。

この記事を書いているとき、彼はまだ Google 社員でしたが、現在は OpenAI に転職しました。 ChatGPT担当者からの報告に直属します。
論文アドレス:
https://arxiv.org/abs/2302.12192
参考リンク: [1]https://www.php .cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2] https://openai.com/blog/instruction-following/
以上がChatGPT のコアメソッドを AI ペイントに使用でき、効果が 47% 向上 担当著者: OpenAI に切り替えましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



