


PyPDF2 モジュールのインストール
# このモジュールでは大文字と小文字が厳密に区別され、y は小文字、残りは大文字です
pip3 install PyPDF2
インストールが完了したら、ローカル ハードディスク上にこのプロジェクトを保存するための専用フォルダーを作成します。ここでの保存パスは F:\Python\PyPDF2 です。F ドライブには Python フォルダーがあります。このモジュールを別個に保存し、他のプロジェクトと区別するために、このモジュールにちなんで名付けられたフォルダー。
ファイルを作成して PDF ドキュメントを準備する
練習用に大きな PDF ドキュメントを探して、Django 公式 Web サイトからダウンロードしました。このドキュメントは 1,900 ページを超える十分な量であり、練習には十分です。必要に応じて、公式 Web サイトにアクセスしてダウンロードするか、公式アカウントに直接「pdf」と返信してダウンロード リンクを取得し、 PDFCF.py プロジェクト ファイル 。
書き込み開始
プログラムは 2 行で始まり、上下 2 つの文を書きます。最初の文は、このファイルの実行プログラムを指定することを意味します. 2 番目の文 この文はこのファイルの説明です。このファイルの機能はまだわかりませんが、プログラムをバッチですばやく実行する方法を知っていれば、その機能がわかるでしょう。ここでは詳しく説明しません。
#! python# PDFCF.py - pdf文件拆分程序
ドキュメント分割の考え方
文書が何個の部分に分割されるかは固定されていませんが、各パートが何ページで構成されるかを固定し、分割数を動的に計算します。分割のアイデアが得られたら、次のステップは計算式をリストすることです。
拆分的份数= 文档总页数 / 拆份每个pdf组成的页数
例:
合計 35 ページの PDF ドキュメントを分割したい場合、PDF ドキュメントは 10 ページで構成されます。新しい文書を何分割できるかの計算式は次のとおりです:
3.5 = 35 / 10
このとき、全員が注目します。余りが 0.5 なら、何それは意味ですか?この例を使用すると、3 つの部分に分割した後に 5 ページが残ることを意味します。この場合、残りが何であっても、分割全体を完了するには 1 つ進む必要があります。この文書の分割結果は次のようになります。最初の 3 つの文書 各文書は 10 ページで構成され、4 番目の文書は最後の 5 ページで構成され、割り切れる場合、結果はそのまま分割部数になります。
Pythonの分割計算式:
if 35 % 10: # 判断是否有余数 35 // 10 + 1 # 取余数整数部分加1else: 0 # 能整除则直接返回0 # 将这个循环写到一行4 = 35 // 10 + 1 if 35 % 10 else 0
具体的にはどのように分割するのでしょうか?
この 35 ページのドキュメント分割を例として考えてみましょう:
データの各ページを num に対してループします。 range(35) の で各ページのデータを取得し、分割する分割ページ範囲を指定します。
最初のドキュメントは 0- -10 から始まります。 、10 を除く
2 番目のドキュメントは 10 ~ 20、20 を除く
3 番目のドキュメントは 20 ~ 30、20 は含まない30
4 番目の文書は 30--35 であり、35 は含まれません
ルールをたどるたびにパターンが見つかりました。数値の値は文書内のページ数であり、その文書が属する数値を掛けることで得られます。 2 番目の数値にはパターンがないことがわかりました。実際、注意深く観察するとパターンがあります。分割数を並べ替えると、この例は 1 ~ 4 になります。2 番目の数値は、現在の分割数を乗算したものです。 by each 文書が構成するページ数 (ページ数は 10 に固定)。
しかし、初めてトラバースするときは 0 から開始するため、num は使用できなくなります。その後、それを変更して、1、range(1,35) からトラバースを開始し、最初からトラバースします。 range にはそれ自体の最後の特性が含まれていないため、走査後にドキュメントの 1 ページが失われます。その後、それに 1 を加えて
for num in range( 1,35 1 )
最初のドキュメントは 10*(1-1)--10*1 から始まり、10 を除きます
2 つのドキュメントは 10*(2-1)--10*2 であり、20 は含まれません
3 番目のドキュメントは 10*(3-1)-10* です3、ではありません。 30
からの特定のトラバーサル コードです。
for num in range(1,35+1): pass for i in range(10 * (num-1), 10 * num if num != 4 else 35): pass
完全な分割手順:
import PyPDF2
PDFを分割する分割リスト方法:
#! python
使い方は?
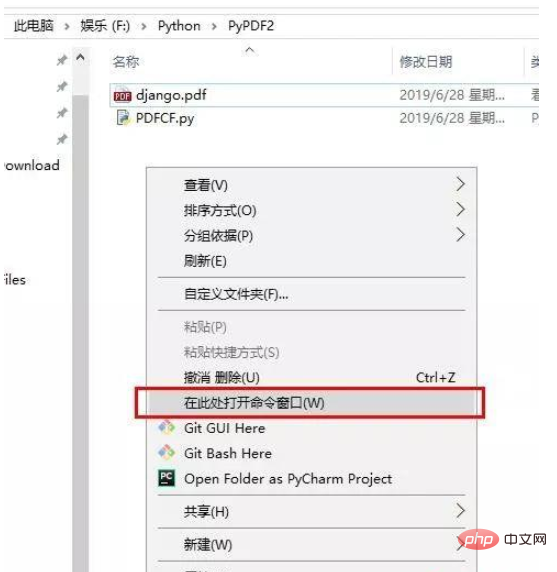
プロジェクト フォルダー内で Shift キーを押したままマウスを右クリックし、ここでコマンド ウィンドウを開くことを選択し、PDFCF.py と入力し、Enter キーを押して、必要に応じて変更します。 nの値が必要です。

以上がPython の PyPDF2 モジュールを使用して PDF ドキュメントを分割する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



