


「私たちには堀がありませんし、OpenAI にもありません。」最近流出した文書の中で、Google の社内研究者はこの見解を表明しました。
この研究者は、OpenAI と Google は大規模な AI モデルでお互いを追いかけているように見えますが、最初の三者勢力が静かに行動しているため、真の勝者はこの 2 つから現れない可能性があると考えています。上昇中。
この力は「オープンソース」と呼ばれます。 Meta の LLaMA などのオープン ソース モデルを中心に、コミュニティ全体が OpenAI や Google の大規模モデルと同様の機能を備えたモデルを急速に構築しています。さらに、オープン ソース モデルは反復性が高く、よりカスタマイズ可能で、よりプライベートです...」は無料だが、制限のない代替品が同等の品質であれば、人々は制限付きのモデルにお金を払うことはない」と著者は書いている。
この文書は元々、公開 Discord サーバー上で匿名の人物によって共有されたもので、転載を許可された業界メディアである SemiAnalysis は、この文書の信頼性を確認したと述べています。
この記事は、Twitter などのソーシャル プラットフォームで大量に転送されています。その中で、テキサス大学オースティン校のアレックス・ディマキス教授は、次のような見解を表明しました:
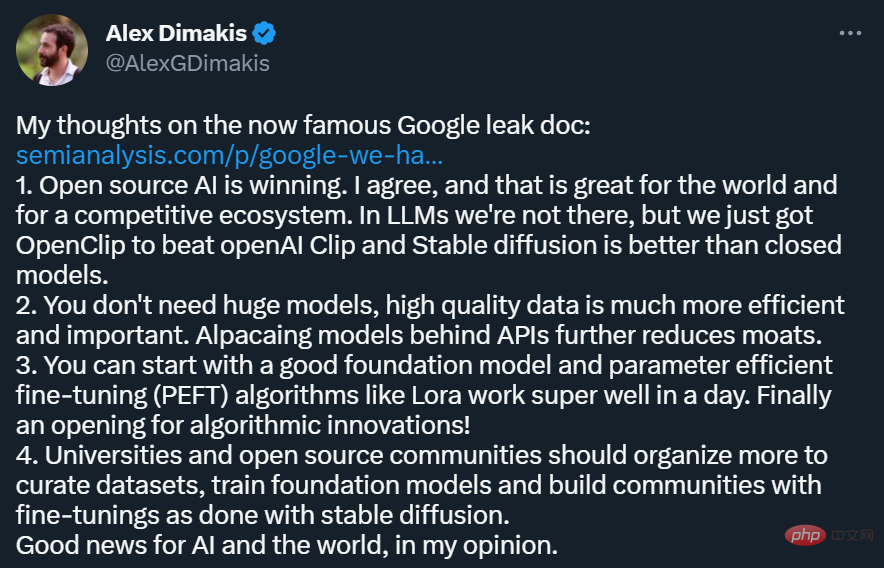
#もちろん、すべての研究者がこの論文の見解に同意しているわけではありません。オープンソース モデルが本当に OpenAI に匹敵する大規模モデルのパワーと汎用性を備えているのかどうかについて、懐疑的な人もいます。
しかし、学界にとって、オープンソースの力の台頭は常に良いことです。 1,000 元はありません。GPU に関して、研究者にはまだやるべきことがあります。
Google も OpenAI も堀
私たちには堀がありませんし、OpenAI にもありません。私たちは、OpenAI のダイナミクスと発展に注目してきました。次のマイルストーンを超えるのは誰でしょうか?次は何ですか?
しかし、不快な真実は、私たちにはこの軍拡競争に勝つための能力が備わっておらず、OpenAI にも同様ではないということです。私たちが言い争いをしている間に、第三の勢力が利益を得ています。
この派閥は「オープンソース派」です。率直に言って、彼らは我々を上回っています。私たちが「重要な未解決問題」だと思っていたものが、今や解決され、人々の手に渡っているのです。
いくつか例を挙げてみましょう:
当社のモデルは依然として品質においてわずかな優位性を維持していますが、その差は驚くべき速度で縮まりつつあります。オープンソース モデルは、同じ条件下でより高速で、よりカスタマイズ可能で、よりプライベートで、より強力です。彼らは 1,000 万ドルと 130 億ドルのパラメータを使って何かを行っていますが、私たちが 1,000 万ドルと 540 億ドルのパラメータを使って行うのは困難です。しかも、数か月ではなく数週間でそれを行うことができます。これは私たちにとって重大な意味を持ちます。
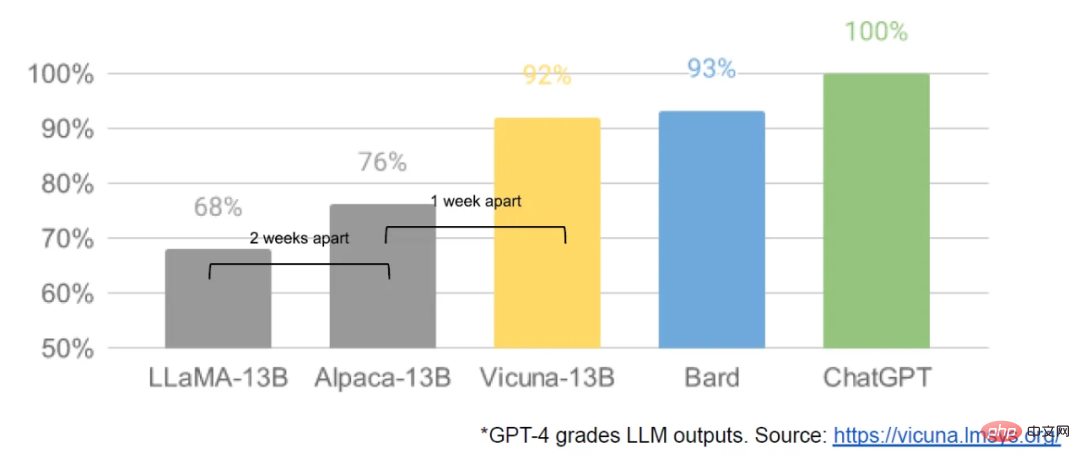
3 月初旬、Meta の LLaMA によって開始されました。モデル 一般に漏洩し、オープンソース コミュニティは初めて真に有用な基本モデルを入手しました。このモデルには指示やダイアログの調整はなく、RLHF もありません。それにもかかわらず、オープンソース コミュニティは LLaMA の重要性をすぐに認識しました。
その後、革新が着実に続き、わずか数日の間隔で大きな進歩が現れました (Raspberry Pi 4B で LLaMA モデルを実行したり、Raspberry Pi 4B で LLaMA 命令を微調整したりするなど)。ラップトップ)、MacBook で LLaMA を実行するなど)。わずか 1 か月後、命令の微調整、量子化、品質向上、マルチモダリティ、RLHF などの亜種がすべて登場し、その多くは相互に構築されていました。
最も重要なのは、スケーリングの問題が解決されたことです。つまり、誰でもこのモデルを自由に変更および最適化できることになります。多くの新しいアイデアは一般の人から生まれます。トレーニングと実験の基準は、主要な研究機関から、1 人、夜間、強力なラップトップに移りました。
多くの点で、これは誰も驚くべきことではありません。オープンソース LLM の現在のルネサンスは、画像生成のルネッサンスに続いて起こっており、多くの人がこれを LLM の安定普及の瞬間と呼んでいます。
どちらの場合も、はるかに安価な低ランク適応 (LoRA) 微調整メカニズムと、規模における大きな進歩を組み合わせることで、低コストの一般参加が実現されます。高品質のモデルが簡単に入手できるため、世界中の個人や機関がアイデアのパイプラインを育成し、それを反復して大企業をすぐに上回ることができました。
これらの貢献は画像生成の分野において極めて重要であり、安定拡散を Dall-E とは異なる方向に設定します。オープン モデルを採用することで、Dall-E には存在しなかった製品統合、マーケットプレイス、ユーザー インターフェイス、イノベーションが可能になりました。
効果は明らかでした。Stable Diffusion の文化的影響は、OpenAI のソリューションと比較してすぐに支配的なものになりました。 LLM も同様の発展を遂げるかどうかはまだわかりませんが、大まかな構造要素は同じです。
オープンソース プロジェクトは、私たちがまだ取り組んでいる問題を直接解決する革新的な方法やテクノロジーを使用しています。オープンソースの取り組みに注意を払うことは、同じ間違いを避けるのに役立ちます。中でもLoRAは非常に強力な技術であり、私たちはもっと注目する必要があります。
LoRA は、モデル更新を低ランク因数分解として提示し、更新行列のサイズを数千分の 1 に削減できます。このようにして、モデルの微調整に必要なコストと時間はわずかです。消費者向けハードウェアで言語モデルのパーソナライズされたチューニング時間を数時間に短縮することは、特に新しく多様な知識をほぼリアルタイムで統合するというビジョンを持つ人にとって重要です。このテクノロジーは、私たちが達成したいと考えているプロジェクトの一部に大きな影響を与えていますが、Google 内では十分に活用されていません。
LoRA が非常に効果的である理由の 1 つは、他の形式の調整と同様に、積み重ねられることです。コマンドの微調整などの改善を適用して、対話や推論などのタスクを支援できます。個々の微調整は低ランクですが、合計はそうではありませんが、LoRA では、モデルへのフルランクの更新を時間の経過とともに蓄積できます。
これは、より新しく優れたデータセットとテストが利用可能になると、全額のランニングコストを支払うことなく、モデルを安価に更新し続けることができることを意味します。
対照的に、大規模なモデルを最初からトレーニングすると、事前トレーニングが破棄されるだけでなく、それまでの反復と改善もすべて破棄されます。オープンソースの世界では、こうした改善が急速に普及し、完全な再トレーニングには法外な費用がかかります。
新しいアプリケーションやアイデアごとに、本当にまったく新しいモデルが必要かどうかを真剣に検討する必要があります。モデルの重みを直接再利用できないような大幅なアーキテクチャの改善がある場合は、前世代の機能をできる限り維持する、より積極的な蒸留アプローチに取り組む必要があります。
LoRA アップデートのコストは、最も一般的なモデル サイズでは非常に低額 (約 100 ドル) です。これは、アイデアを持っているほとんどの人がそれを生成して配布できることを意味します。トレーニングに 1 日もかからない通常の速度では、微調整の累積効果により、最初のサイズの不利な点がすぐに克服されます。実際、これらのモデルは、エンジニアの時間という点で、当社の最大のモデルが達成できるよりもはるかに速く改善されています。そして、最高のモデルはすでに ChatGPT とほとんど区別がつきません。そのため、最大規模のモデルの一部を維持することに集中すると、実際には不利な状況に陥ります。
これらのプロジェクトの多くは、高度に厳選された小規模なデータセットでトレーニングすることで時間を節約しています。これは、データ スケーリング ルールの柔軟性を示しています。このデータセットは、「Data Doesn't Do What You Think」のアイデアから誕生しており、急速に Google なしでトレーニングする標準的な方法になりつつあります。これらのデータセットは、合成手法 (既存のモデルから最適な反射をフィルタリングするなど) を使用して作成され、他のプロジェクトからスクレイピングされていますが、どちらも Google では一般的に使用されていません。幸いなことに、これらの高品質のデータセットはオープンソースであるため、自由に利用できます。
この最近の開発は、ビジネス戦略に非常に直接的な影響を与えています。使用制限のない無料で高品質な代替製品があるのに、使用制限のある Google サービスに誰がお金を払うでしょうか?それに、追いつくことを期待すべきではありません。オープンソースには私たちには真似できない重要な利点があるため、現代のインターネットはオープンソースで実行されています。
テクノロジーの秘密を守ることは、常に脆弱な命題です。 Google の研究者は定期的に他の企業を訪問して研究しているため、私たちが知っていることはすべて知っていると思われます。そして、このパイプラインが開いている限り、彼らはそうし続けるでしょう。
しかし、LLM 分野の最先端の研究がより手頃な価格になるにつれて、技術的な競争上の優位性を維持することがますます困難になってきています。世界中の研究機関は、私たちの能力をはるかに超えた幅優先のアプローチでソリューション空間を探索するために互いに学び合っています。私たちは自分たちの秘密を守るために一生懸命働くことはできますが、外部の革新によってその価値が薄れてしまうため、お互いから学ぶように努めてください。
ほとんどのイノベーションはメタの漏洩したモデルの重みに基づいて構築されています。真のオープンモデルがますます改良されるにつれて、これは必然的に変化しますが、重要なのは待つ必要がないということです。 「個人使用」によって提供される法的保護と個人の訴追が非現実的であるということは、個人がこれらのテクノロジーをホットな状態でも使用できることを意味します。
逆説的ですが、このすべてにおいて勝者はただ 1 人だけです。それが Meta です。結局のところ、漏洩したモデルは彼らのものです。オープンソースのイノベーションのほとんどはそのアーキテクチャに基づいているため、それらを独自の製品に直接統合することを妨げるものはありません。
ご覧のとおり、エコシステムを持つことの価値はどれだけ誇張してもしすぎることはありません。 Google 自体も、Chrome や Android などのオープンソース製品ですでにこのパラダイムを使用しています。 Google は、革新的な取り組みを促進するためのプラットフォームを構築することで、ソート リーダーおよび方向性設定者としての地位を固め、自社よりも大きなアイデアを形にする能力を獲得しました。
モデルを厳密に管理するほど、オープンな代替案を作成することがより魅力的になります。Google と OpenAI は両方とも、防御的なリリース モデルを採用する傾向があり、これにより、モデルを厳密に管理できます。モデル。しかし、この制御は非現実的です。 LLM を未承認の目的で使用したい場合は、自由に利用できるモデルから選択できます。
したがって、Google はオープンソース コミュニティのリーダーとしての地位を確立し、オープンソース コミュニティを無視するのではなく、より広範な対話と協力を通じて主導権を握る必要があります。これは、小さな ULM バリアントのモデルの重みをリリースするなど、不快な措置を講じることを意味する場合があります。これは必然的に、独自のモデルに対する制御をある程度放棄することも意味しますが、この妥協は避けられません。イノベーションを推進することと、それを制御することの両方を望むことはできません。
OpenAI の現在の非公開ポリシーを考慮すると、このオープンソースに関する議論はすべて不公平に感じられます。彼らがテクノロジーを共有することに消極的であれば、なぜ私たちがそれを共有する必要があるのでしょうか?しかし実際には、私たちは OpenAI の上級研究者を継続的に引き抜き、彼らとすべてを共有してきました。私たちがこの流れを食い止めるまで、秘密保持は議論の余地のある問題であり続けるでしょう。
最後に、OpenAI は重要ではありません。彼らは、オープンソースの姿勢に関して私たちと同じ間違いを犯しており、彼らの優位性を維持する能力が疑問視されることは間違いありません。 OpenAI がその姿勢を変えない限り、オープンソースの代替手段は最終的にはそれらを覆い隠す可能性があります。少なくともこの点に関しては、私たちはこの一歩を踏み出すことができます。
以上が流出した Google の内部文書によると、Google と OpenAI の両方に効果的な保護メカニズムが欠如しているため、オープンソース コミュニティによって大規模モデルのしきい値が継続的に引き下げられています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



