


ブルームフィルター(Bloom Filter)は、1970年にBloomによって提案されました。実際には、非常に長いバイナリ配列と一連のハッシュ アルゴリズム マッピング関数で構成されており、セット内に要素が存在するかどうかを判断するために使用されます。
ブルーム フィルターを使用して、要素がコレクション内にあるかどうかを取得できます。利点は、スペース効率とクエリ時間が通常のアルゴリズムよりも優れていることですが、欠点は、ある程度の誤認識率と削除が難しいことです。
携帯電話番号が 10 億あると仮定し、特定の携帯電話番号がリストに含まれているかどうかを判断しますか?
mysqlでは可能でしょうか?
通常の状況では、データの量が大きくない場合は、mysql ストレージの使用を検討できます。すべてのデータをデータベースに保存し、毎回データベースにクエリを実行して、データベースが存在するかどうかを確認します。ただし、データ量が大きすぎて数千万を超えると、MySQL のクエリ効率が非常に低くなり、特にパフォーマンスが消費されます。
HashSet は使用できますか?
データを HashSet に入れて、HashSet の自然な重複排除を使用できます。クエリでは contains メソッドを呼び出すだけで済みますが、ハッシュセットはメモリに保存されます。データの量が多すぎる場合は、大きい場合、メモリは直接 oom になります。
挿入とクエリは効率的で、占有スペースも少なくなりますが、返される結果は不確実です。
要素が存在すると判断された場合、実際には存在しない可能性があります。しかし、要素が存在しないと判断された場合、その要素は存在しないはずです。
ブルーム フィルターは要素 を追加できますが、要素 を削除してはなりません。これにより、誤検知率が増加します。
ブルーム フィルターは実際には BIT 配列であり、一連のハッシュ アルゴリズムを通じて対応するハッシュをマッピングし、次に、対応するハッシュをマッピングします。配列の添え字の位置が 1 に変更されます。クエリを実行すると、添字を取得するためにデータに対して一連のハッシュ アルゴリズムが実行されます。データは、 などの BIT 配列から取得されます。1 の場合は、データが存在する可能性があることを意味します。0 の場合は、
ブルーム フィルターが実際にデータをハッシュすることがわかっているため、どのようなアルゴリズムが使用されていても、エラー率は存在しません。 2 つの異なるデータによって生成されたハッシュが実際に同じである可能性があります。つまり、一般にハッシュの競合と呼ばれます。
最初にデータを挿入します: テクノロジーをよく学びましょう
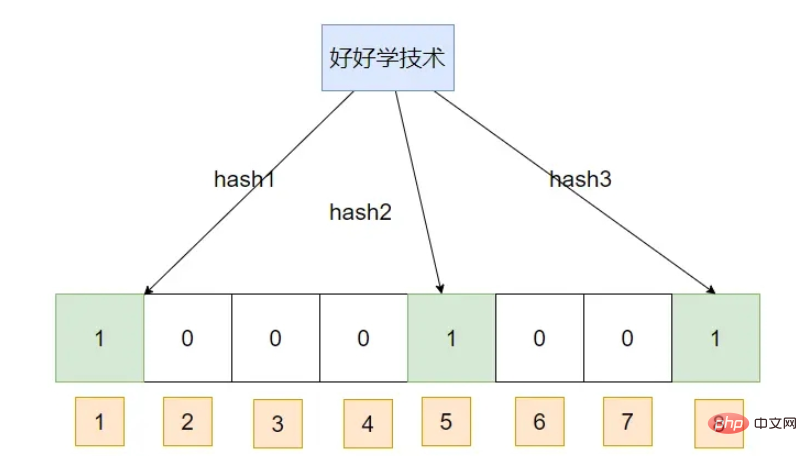
データを挿入します:
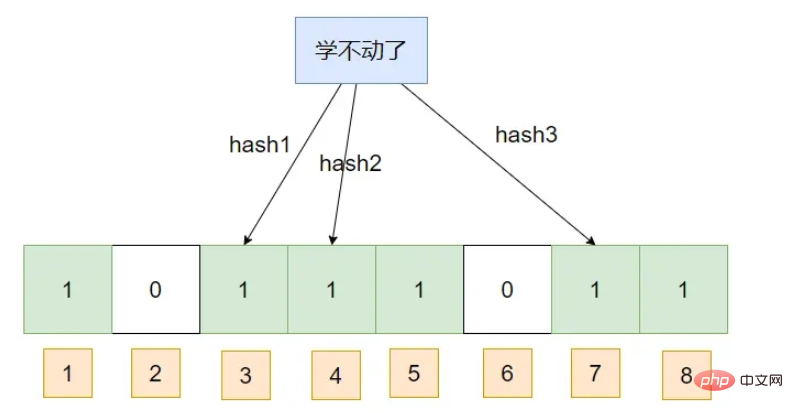
これ データの一部をクエリすると、そのハッシュ添え字が 1 としてマークされていると仮定すると、ブルーム フィルターはそのデータが存在すると認識します
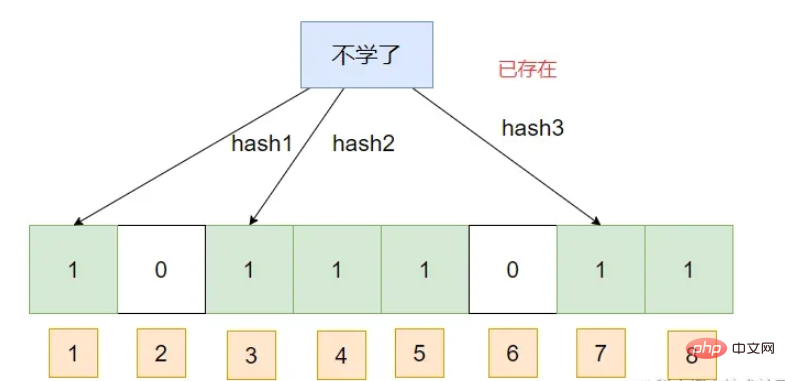
package com.fandf.test.redis;
import java.util.BitSet;
/**
* java布隆过滤器
*
* @author fandongfeng
*/
public class MyBloomFilter {
/**
* 位数组大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{4, 8, 16, 32, 64, 128, 256};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private final BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private final MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
public static void main(String[] args) {
String str = "好好学技术";
MyBloomFilter myBloomFilter = new MyBloomFilter();
System.out.println("str是否存在:" + myBloomFilter.contains(str));
myBloomFilter.add(str);
System.out.println("str是否存在:" + myBloomFilter.contains(str));
}
}<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>package com.fandf.test.redis;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @author fandongfeng
*/
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),100000,0.01);
bloomFilter.put("好好学技术");
System.out.println(bloomFilter.mightContain("不好好学技术"));
System.out.println(bloomFilter.mightContain("好好学技术"));
}
}<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.3</version>
</dependency>package com.fandf.test.redis;
import cn.hutool.bloomfilter.BitMapBloomFilter;
import cn.hutool.bloomfilter.BloomFilterUtil;
/**
* @author fandongfeng
*/
public class HutoolBloomFilter {
public static void main(String[] args) {
BitMapBloomFilter bloomFilter = BloomFilterUtil.createBitMap(1000);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
}<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.20.0</version>
</dependency>package com.fandf.test.redis;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
/**
* Redisson 实现布隆过滤器
* @author fandongfeng
*/
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("name");
//初始化布隆过滤器:预计元素为100000000L,误差率为1%
bloomFilter.tryInit(100000000L,0.01);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
}以上がJavaでブルームフィルターを実装するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



