


Transformer は、NLP 事前トレーニング モデル アーキテクチャとして、大規模なラベルなしデータを効果的に学習できます。調査により、Transformer が BERT 以来の NLP タスクの中核アーキテクチャであることが証明されています。
最近の研究では、状態空間モデル (SSM) が長距離シーケンスのモデル化に有利な競合アーキテクチャであることが示されています。 SSM は音声生成と Long Range Arena ベンチマークで最先端の結果を達成し、Transformer アーキテクチャをも上回るパフォーマンスを発揮します。精度の向上に加えて、SSM に基づくルーティング層は、シーケンスの長さが増加しても 2 次の複雑さを示さなくなります。
この記事では、コーネル大学、DeepMind、その他の機関の研究者が、注意を払わずに事前トレーニングできる双方向ゲート SSM (BiGS) を提案しました。これは主に SSM ルーティングを使用し、アーキテクチャ ベースのルーティングと組み合わせられています。乗算ゲートについて。この研究では、SSM 自体は NLP の事前トレーニングではパフォーマンスが低いが、乗算ゲート型アーキテクチャに統合すると、ダウンストリームの精度が向上することがわかりました。
実験では、制御された設定の下で同じデータでトレーニングした場合、BiGS が BERT モデルのパフォーマンスに匹敵することができることを示しています。より長いインスタンスでの追加の事前トレーニングにより、モデルは入力シーケンスを 4096 にスケーリングするときにも線形時間を維持します。分析の結果、乗算ゲートが必要であることが示され、可変長テキスト入力における SSM モデルのいくつかの特有の問題が修正されました。

論文アドレス: https://arxiv.org/pdf/2212.10544.pdf #メソッドの概要
SSM は、次の微分方程式を通じて連続入力 u (t) を出力 y (t) に接続します。
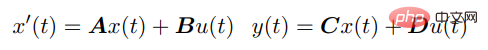
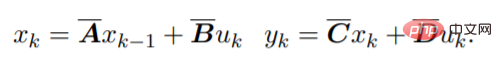 ##これ方程式は線形 RNN として解釈できます。ここで、x_k は隠れ状態です。 y は畳み込みを使用して計算することもできます:
##これ方程式は線形 RNN として解釈できます。ここで、x_k は隠れ状態です。 y は畳み込みを使用して計算することもできます:
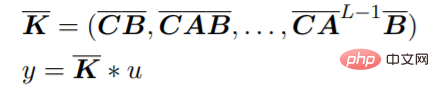 ニューラル ネットワークで SSM を使用する効率的な方法は、パラメーターを開発した Gu らによって示されました。 HiPPO と呼ばれる A のアプローチにより、S4 と呼ばれる安定した効率的なアーキテクチャが誕生しました。これにより、RNN トレーニングよりも効率的でありながら、長期シーケンスをモデル化する SSM の機能が維持されます。最近、研究者らは、元のパラメータのより単純な近似を使用して同様の結果を達成する、S4 の単純化された対角化バージョンを提案しました。大まかに言えば、SSM ベースのルーティングは、二次的な計算による多大なコストを発生させることなく、ニューラル ネットワークでシーケンスをモデル化する代替手段を提供します。
ニューラル ネットワークで SSM を使用する効率的な方法は、パラメーターを開発した Gu らによって示されました。 HiPPO と呼ばれる A のアプローチにより、S4 と呼ばれる安定した効率的なアーキテクチャが誕生しました。これにより、RNN トレーニングよりも効率的でありながら、長期シーケンスをモデル化する SSM の機能が維持されます。最近、研究者らは、元のパラメータのより単純な近似を使用して同様の結果を達成する、S4 の単純化された対角化バージョンを提案しました。大まかに言えば、SSM ベースのルーティングは、二次的な計算による多大なコストを発生させることなく、ニューラル ネットワークでシーケンスをモデル化する代替手段を提供します。
事前トレーニング モデルのアーキテクチャ
SSM は事前トレーニングにおける注意を置き換えることができますか?この質問に答えるために、この研究では、図 1 に示すスタック アーキテクチャ (STACK) と乗算ゲート アーキテクチャ (GATED) という 2 つの異なるアーキテクチャを検討しました。
セルフアテンションを備えたスタック アーキテクチャは BERT /トランスフォーマ モデルと同等であり、ゲート アーキテクチャはゲート ユニットを双方向に適応させたもので、最近単方向 SSM にも使用されています。 。乗算ゲートを備えた 2 つのシーケンス ブロック (順方向および逆方向 SSM) がフィードフォワード層に挟まれています。公平な比較のために、ゲート アーキテクチャのサイズはスタック アーキテクチャと同等に保たれています。
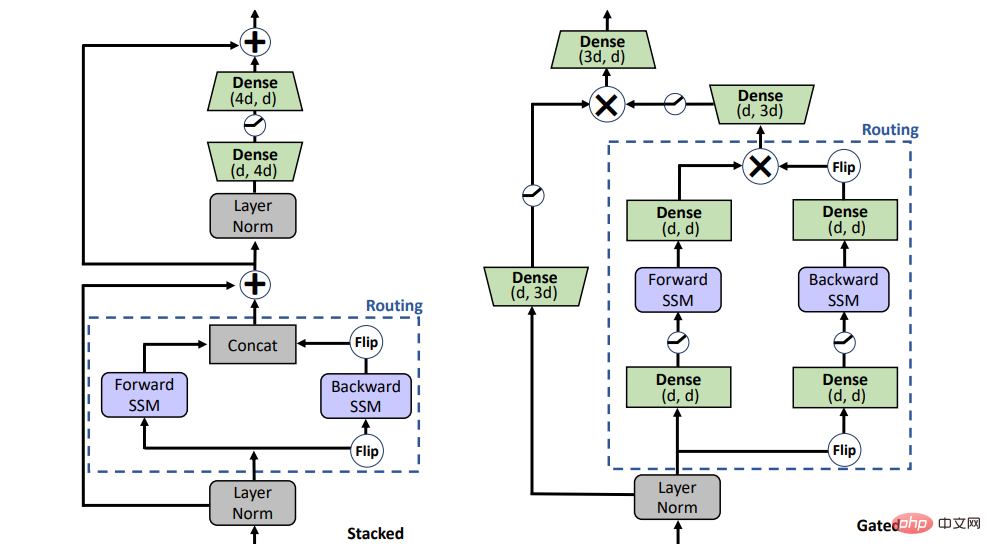
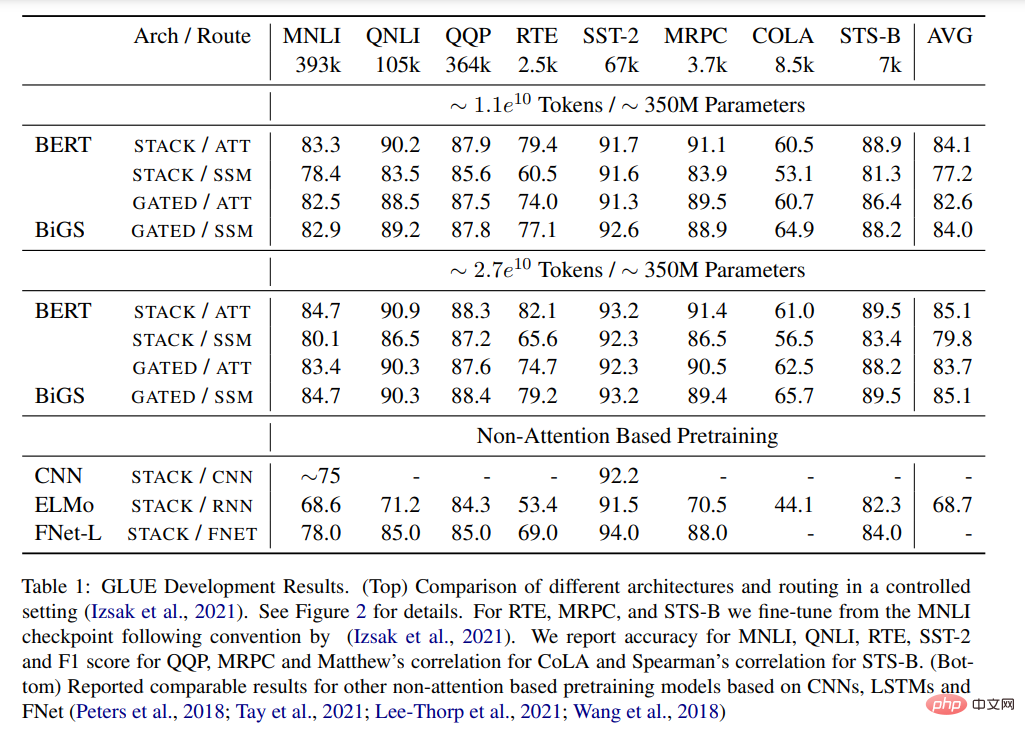
事前トレーニング 表 1 は、GLUE で事前トレーニングされたさまざまなモデルの主な結果を示しています。基準。 BiGS は、トークン拡張における BERT の精度を再現します。この結果は、SSM がそのような計算予算の下で事前トレーニングされた変圧器モデルの精度を再現できることを示しています。これらの結果は、他の非注意ベースの事前トレーニング済みモデルよりも大幅に優れています。この精度を達成するには、乗算ゲートが必要です。ゲートを使用しない場合、スタック型 SSM の結果は大幅に悪化します。この利点が主にゲーティングの使用によるものかどうかを調べるために、GATE アーキテクチャを使用して注意ベースのモデルをトレーニングしましたが、結果は、このモデルが実際には BERT よりも効果的でないことを示しています。 #表 1: 接着剤の結果。 (上) 制御設定でのさまざまなアーキテクチャとルーティングの比較。詳細については、図 2 を参照してください。 (下) は、CNN、LSTM、および FNet に基づく他の非注意事前トレーニング モデルについて同等の結果を報告しました。 #長い形式のタスク
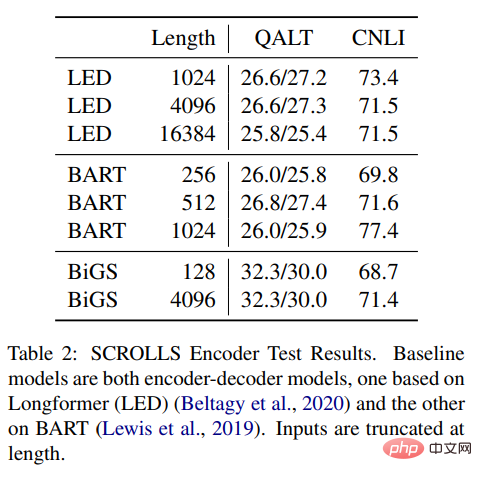
#表 2: SCROLLS エンコーダーのテスト結果。ベースライン モデルはどちらもエンコーダ/デコーダ モデルで、1 つは Longformer (LED) に基づいており、もう 1 つは BART に基づいています。入力された長さは切り捨てられます。 #詳細については、元の論文を参照してください。 実験結果
以上が事前トレーニングには注意を払う必要はなく、4096 トークンまでのスケーリングも問題なく、BERT に匹敵します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



