


皆さん、こんにちは。NVIDIA GPU コンピューティング エキスパート チームの Tao Li です。今日は、同僚の Chen Yu と私が Swin Transformer で行ったことを皆さんと共有する機会を得ることができて、とても嬉しく思います。ビジュアル モデル: 型トレーニングと推論の最適化に取り組んでいる人もいます。これらの方法と戦略の一部は、他のモデルのトレーニングや推論の最適化に使用して、モデルのスループットを向上させ、GPU の使用効率を向上させ、モデルの反復を高速化することができます。
#Swin Transformer モデルのトレーニング部分の最適化について紹介します。推論最適化部分の作業については同僚によって詳細に紹介されます
#本日共有したディレクトリは主に4つの部分に分かれており、特定のモデルに最適化されているため、まず、Swin Transformer モデルについて簡単に紹介します。次に、プロファイリング ツール、つまり nsight システムを組み合わせて、トレーニング プロセスを分析し、最適化します。推論の部分では、同僚が、より詳細な CUDA レベルの最適化を含む、推論の最適化のための戦略と方法を提供します。最後に、本日の最適化内容をまとめます。

1. Swin Transformer の紹介
名前からわかるように、モデル、これはトランスをベースにしたモデルです。最初にトランスについて簡単に説明します。
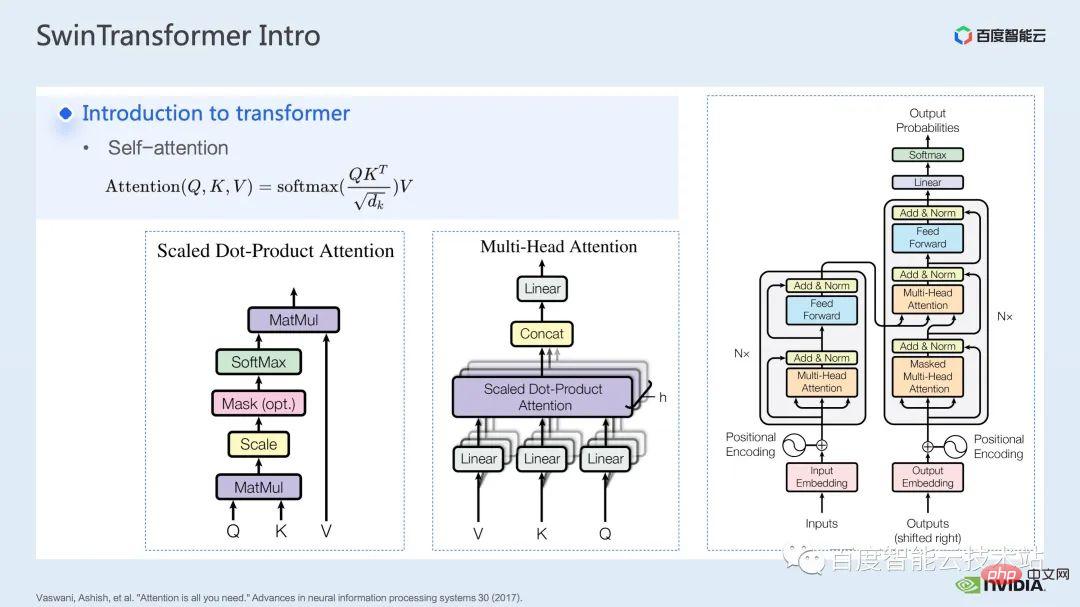
記事で Transformer モデルが提案されて以来、必要なのは注目だけであり、自然言語処理の分野の多くのタスクにそのモデルが当てられてきました。
Transformer モデルの中核は、いわゆるアテンション メカニズム、つまりアテンション メカニズムです。アテンション モジュールの場合、通常の入力はクエリ、キー、値テンソルです。クエリとキーの機能とソフトマックスの計算により、通常アテンション マップと呼ばれるアテンション結果を取得できます。アテンション マップの値に従って、モデルは値のどの領域にもっと注意を払う必要があるかを学習できます。モデルは、値のどの値が私たちのタスクに非常に役立つかを学習できると言われています。これは最も基本的な単頭注意モデルです。
このような単一ヘッド アテンション モジュールの数を増やすことで、共通のマルチヘッド アテンション モジュールを形成できます。一般的なエンコーダとデコーダは、このようなマルチヘッド アテンション モジュールに基づいて構築されます。
多くのモデルには、通常、自己注意と交差注意、または 1 つ以上のモジュールのスタックという 2 種類の注意モジュールが含まれています。たとえば、有名な BERT は複数のエンコーダ モジュールで構成されており、一般的な拡散モデルには通常、セルフ アテンションとクロス アテンションの両方が含まれています。
Swin Transformer では、ウィンドウ アテンションの概念が導入されています。画像全体に注意を払う ViT とは異なり、Swin Transformer は最初に画像を分割します。複数のウィンドウを分割し、ウィンドウ内のパッチのみに注目することで計算量を削減します。
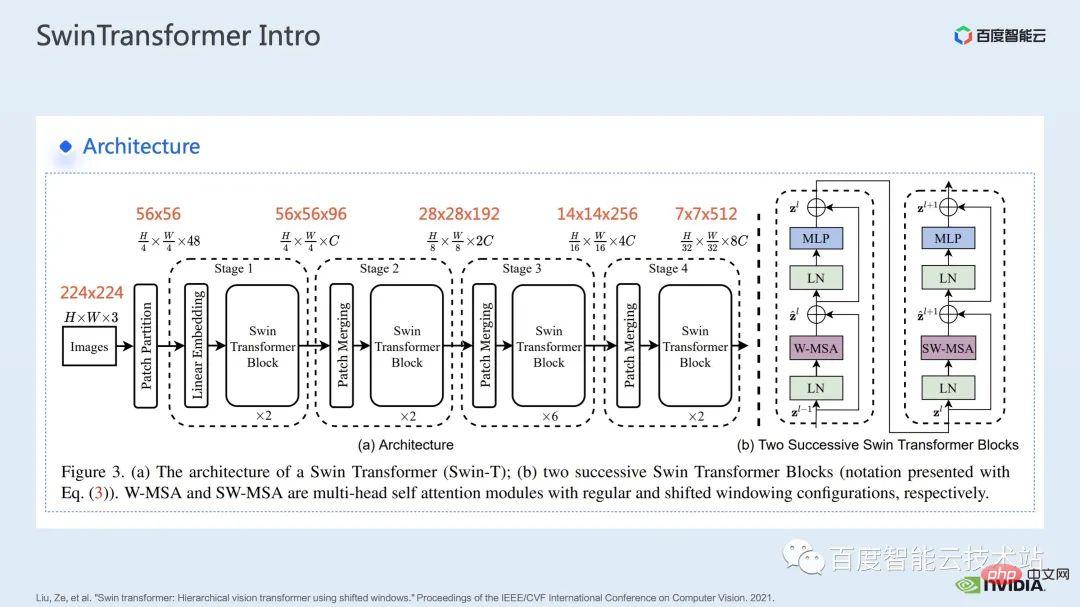
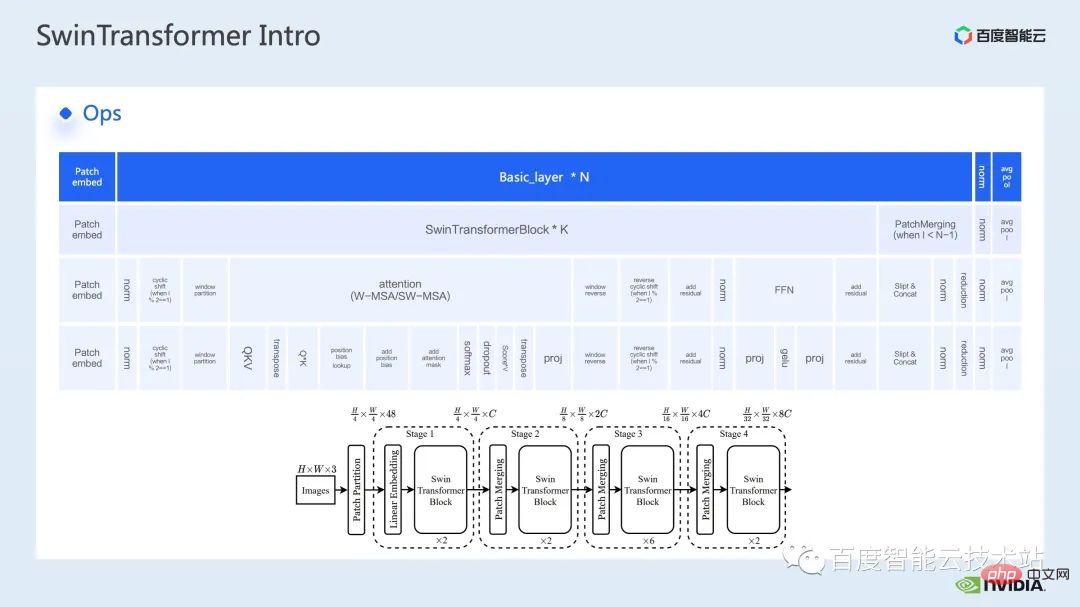
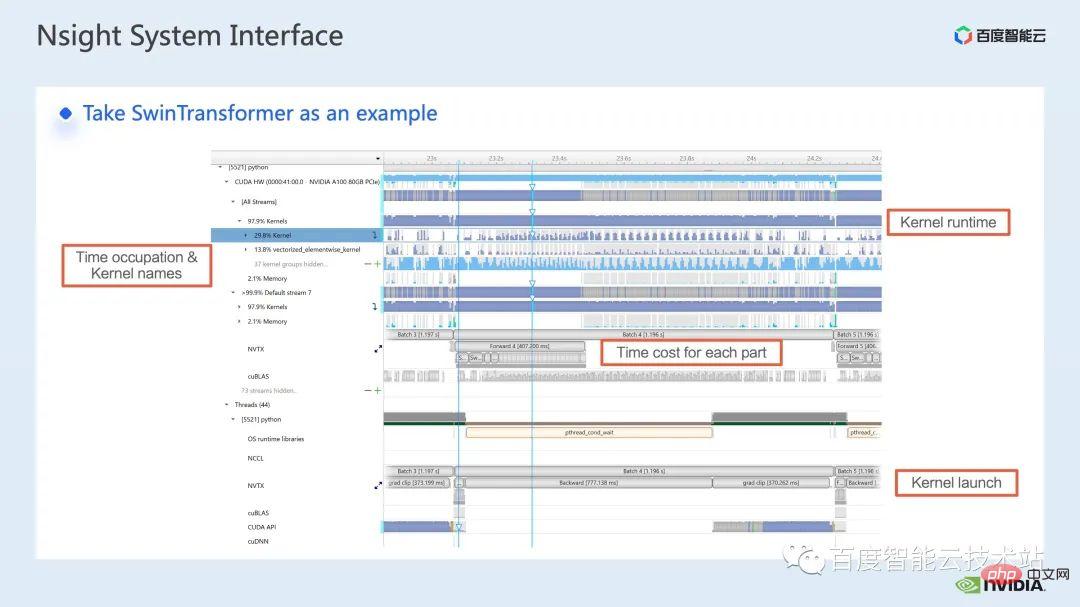
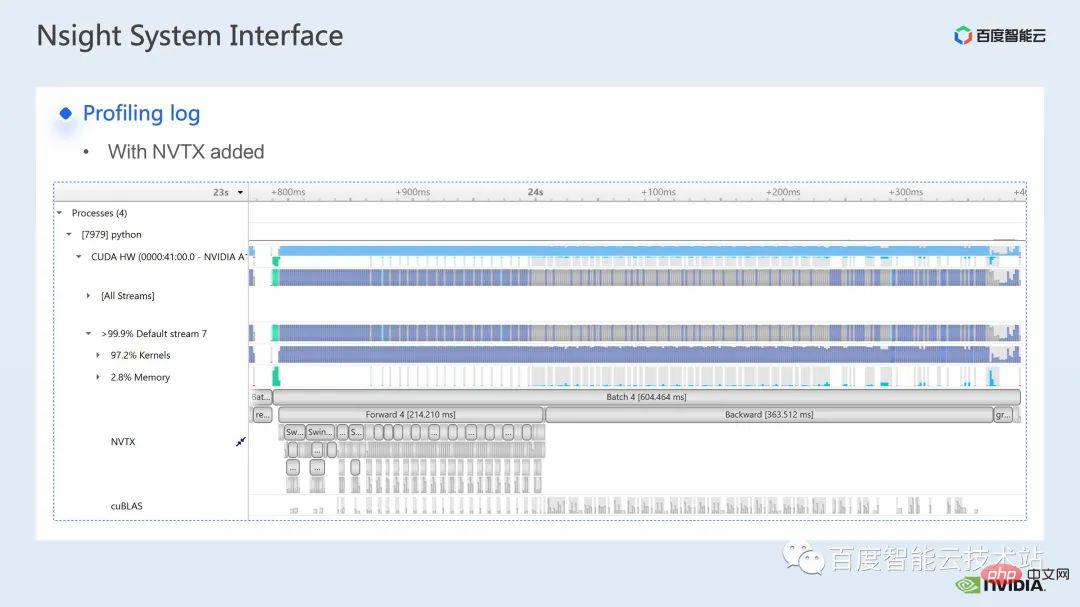
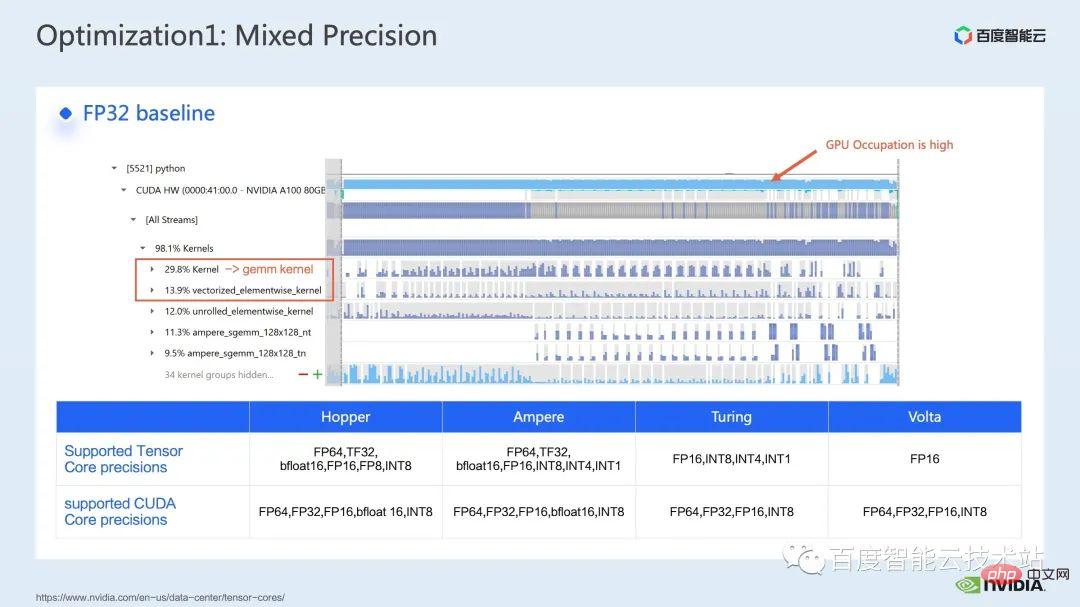
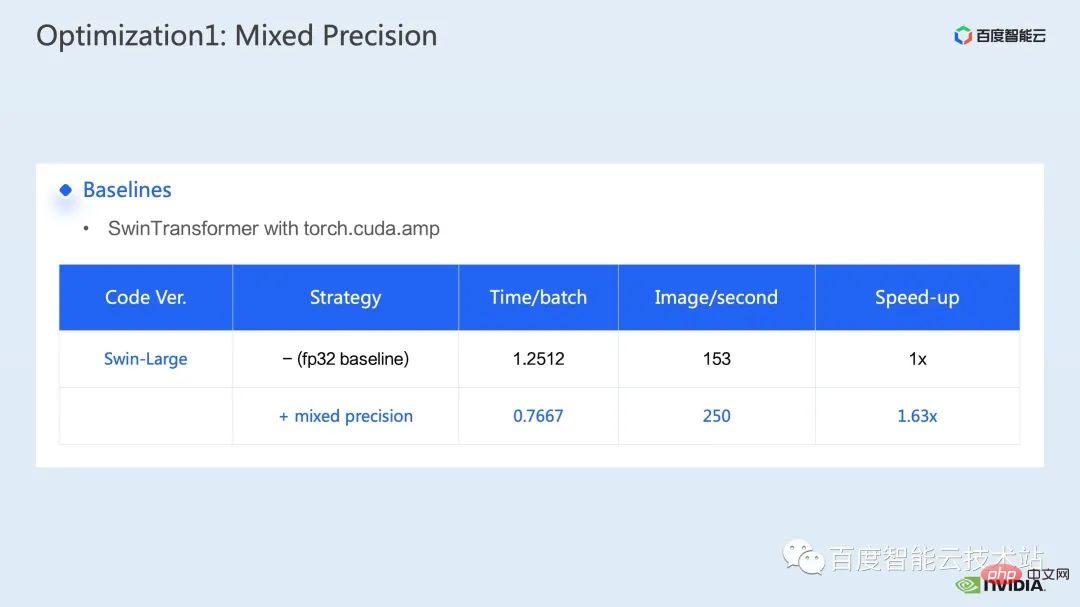
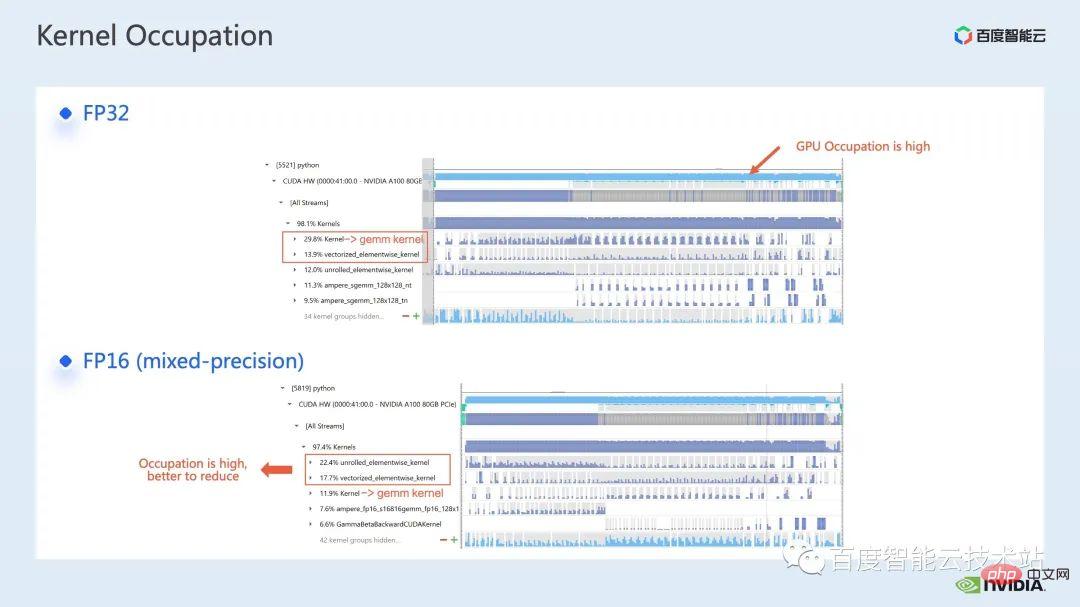
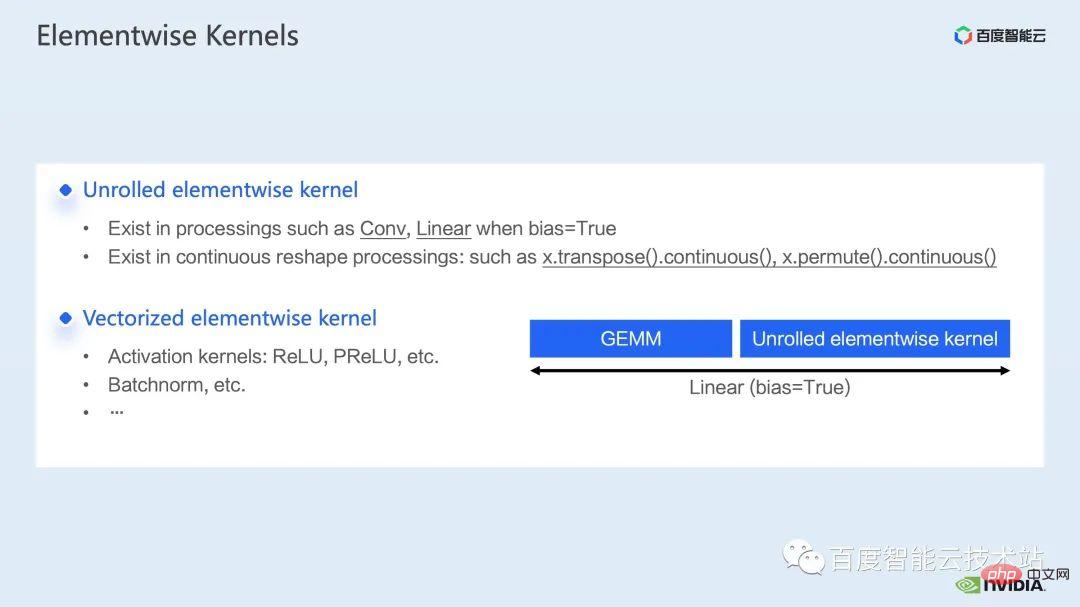
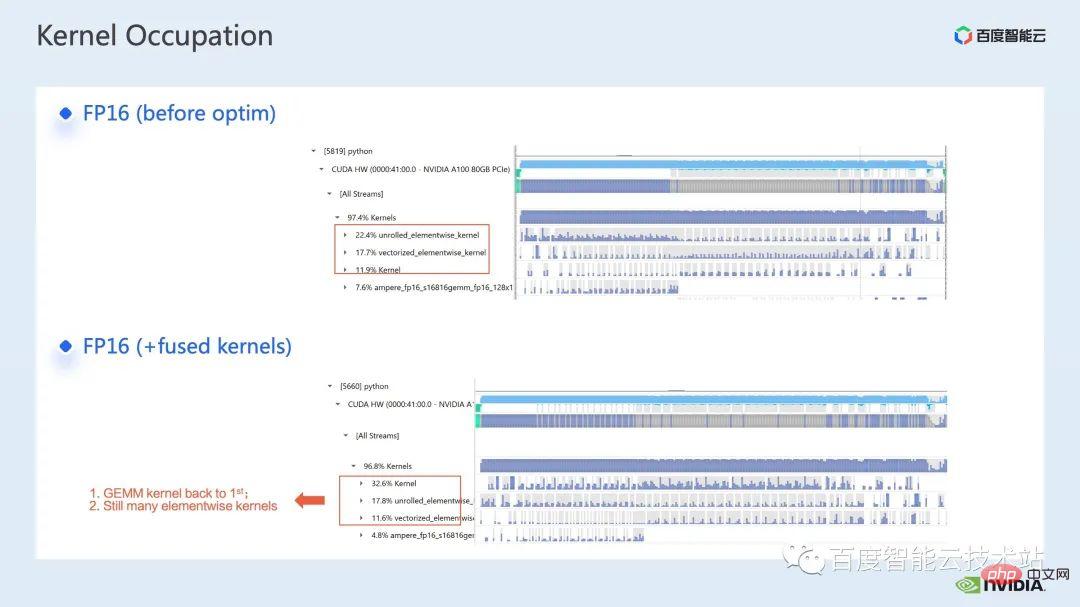
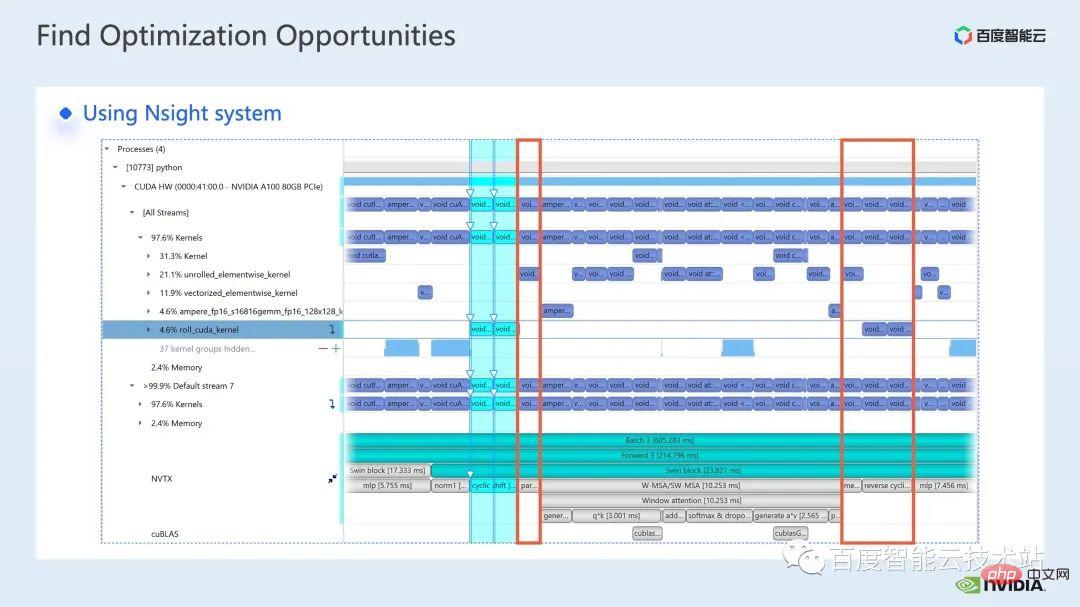
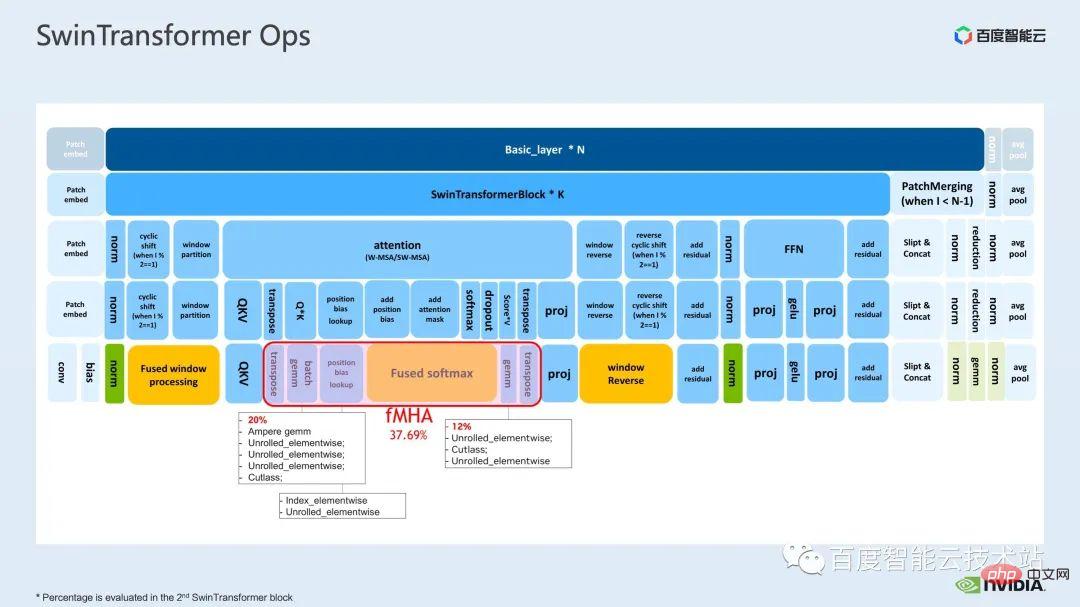
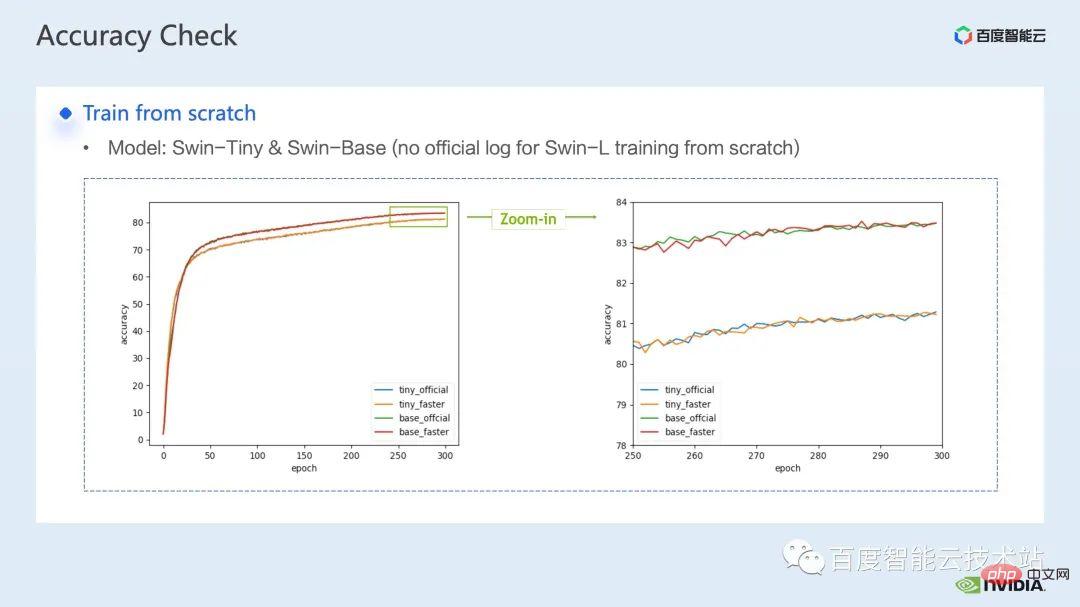
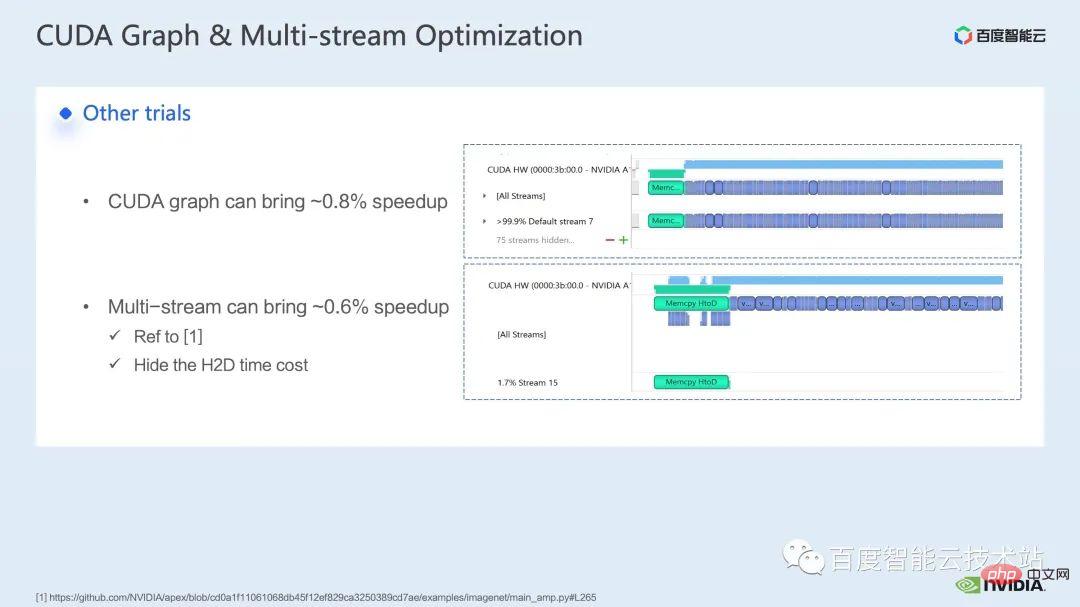
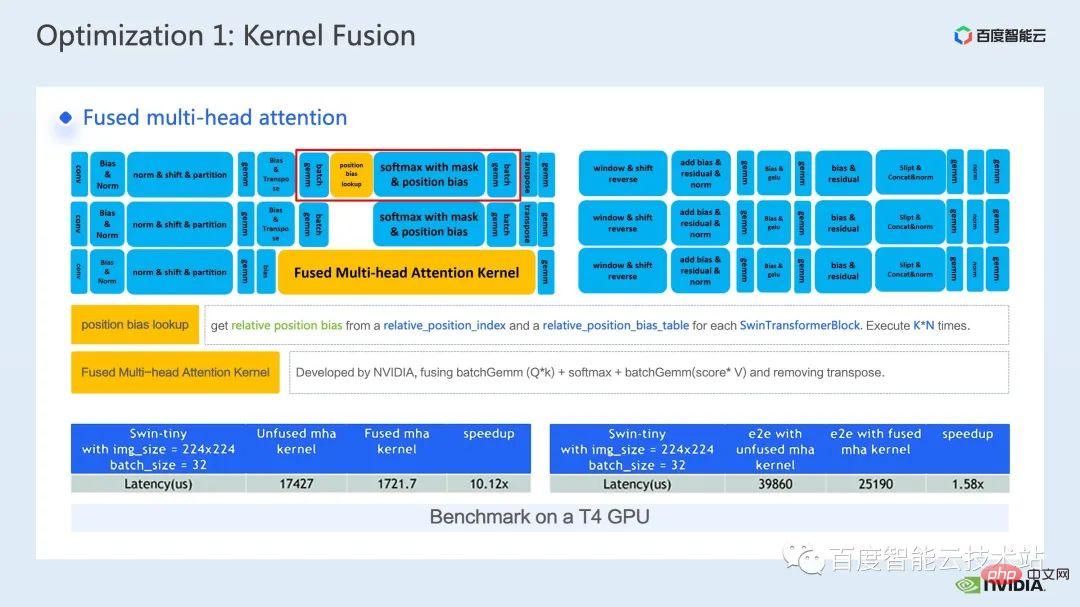
ウィンドウによって引き起こされる境界問題を補うために、Swin Transformer はさらにウィンドウ シフト操作を導入します。同時に、モデルに豊富な位置情報を持たせるために、相対位置バイアスも考慮して導入されます。実は、ここでのウィンドウ アテンションとウィンドウ シフトが、Swin Transformer の Swin という名前の由来になっています。 ここで示すのは Swin Transformer のネットワーク構造です。大まかなネットワーク構造は従来の CNN とよく似ています。 ResNet と同様です。 ネットワーク構造全体が複数のステージに分割されており、さまざまなステージの途中で、対応するダウンサンプリング プロセスが存在することがわかります。各ステージの解像度は異なるため、解像度ピラミッドが形成され、各ステージの計算の複雑さも徐々に軽減されます。 # 次に、各ステージにいくつかの変圧器ブロックがあります。各変圧器ブロックでは、前述のウィンドウ アテンション モジュールが使用されます。 #次に、具体的な操作の観点から Swin Transformer を分解していきます。 ご覧のとおり、Transformer ブロックには 3 つの部分が含まれており、最初の部分はウィンドウのシフト/分割/反転などのウィンドウ関連の操作であり、2 番目の部分はウィンドウ関連の操作です。部分はアテンションの計算で、3 番目の部分は FFN 計算です。アテンションと FFN の部分はさらにいくつかの演算に細分化でき、最終的にはモデル全体を数十の演算の組み合わせに細分化できます。 # このような演算子の分割は、パフォーマンス分析を実施し、パフォーマンスのボトルネックを特定し、高速化の最適化を実行するために非常に重要です。 #以上が前編の紹介です。次に、トレーニングで行った最適化作業の一部を紹介します。特に、プロファイリング ツール、つまり nsight システムを組み合わせて、トレーニング プロセス全体を分析し、最適化します。 2. Swin Transformer トレーニングの最適化 大規模向けモデルのトレーニングには、通常、マルチカードおよびマルチノードのコンピューティング リソースが使用されます。 Swin Transformer の場合、カード間通信のオーバーヘッドが比較的小さいことがわかり、カード枚数が増加するにつれて全体の速度がほぼ直線的に向上するため、ここでは単一の GPU での計算ボトルネックの分析を優先します。最適化。 nsight system は、システムレベルのパフォーマンス分析ツールです。このツールを通じて、モデルの各モジュールの GPU 使用状況を簡単に確認できます。潜在的なパフォーマンスのボトルネックやデータ待機などの最適化スペースにより、CPU と GPU 間の負荷を合理的に計画することが容易になります。 nsight システムは、CUDA および cublas、cudnn、tensorRT などの一部の GPU コンピューティング ライブラリによって呼び出されるカーネル関数の呼び出しおよび実行ステータスをキャプチャできます。ユーザーがいくつかのマークを追加して、マーク範囲内の対応する GPU の動作をカウントするのに便利です。 標準的なモデル最適化プロセスを次の図に示します。モデルをプロファイリングし、パフォーマンス分析レポートを取得し、パフォーマンスの最適化ポイントを発見して、それらをターゲットにします。パフォーマンスチューニングを行うためです。 これは nsight システムのインターフェイスです。カーネル関数の起動 (カーネルの起動)、カーネル関数の実行 (ランタイム部分) がはっきりとわかります。特定のカーネル関数については、プロセス全体における時間の割合、GPU がアイドル状態かどうかなどの情報を確認できます。 nvtx タグを追加すると、モデルが前進および後退するのにかかる時間を確認できます。 前の部分でズームインすると、各 SwinTransformer ブロックの特定の計算ニーズも明確にわかります。時間。 最初に、nsight システム パフォーマンス分析ツールを使用して、ベースライン全体のパフォーマンスを調べます (図を参照)。下の図 FP32 のベースラインから、GPU 使用率が非常に高く、行列乗算カーネルが最も高い割合を占めていることがわかります。 #したがって、行列乗算の最適化方法の 1 つは、加速のためにテンソル コアを最大限に活用することです。 NVIDIA の GPU には、行列乗算を高速化するために特別に設計されたモジュールである cuda コアや tensor コアなどのハードウェア リソースがあることが知られています。 tf32 tensor コアを直接使用するか、混合精度で fp16 tensor コアを使用することを検討できます。 fp16 を使用した tensor コアの行列乗算のスループットは tf32 のスループットよりも高く、純粋な fp32 の行列乗算にも高い加速効果があることがわかります。 #ここでは、混合精度ソリューションを採用します。 torch.cuda.amp の混合精度モードを使用すると、1.63 倍のスループット向上を達成できます。 プロファイリング結果からも、元々最大の数値を占めていた行列の乗算が、が最適化されたため、タイムライン全体に占める割合は 11.9% に低下しました。これまでのところ、比較的高い割合を占めるカーネルは要素ごとのカーネルです。 #要素ごとのカーネルの場合、まず要素ごとのカーネルがどこで使用されるかを理解する必要があります。 Elementwise カーネルでは、より一般的な展開された要素ごとのカーネルとベクトル化された要素ごとのカーネルです。その中でも、アンロールされた要素ごとのカーネルは、一部のバイアスをかけた畳み込みや線形層、さらにはメモリ内のデータの連続性を保証する一部の演算で広く見られます。 ベクトル化された要素ごとのカーネルは、ReLU などの一部の活性化関数の計算によく登場します。ここで多数の要素ごとのカーネルを削減したい場合、一般的なアプローチは演算子の融合を実行することです。たとえば、行列の乗算では、要素ごとの演算を行列乗算の演算子と融合することで、この部分の時間オーバーヘッドを削減できます。 一般的に、演算子融合には次の 2 つの利点があります。 1 つは、カーネルの起動コストを削減することです。下の図に示すように、2 つの cuda カーネルを実行するには 2 回の起動が必要です。これにより、カーネル間にギャップが生じ、GPU がアイドル状態になる可能性があります。 2 つの cuda カーネルを 1 つの cuda カーネルにマージすると、起動を節約できる一方で、ギャップの生成を回避できます。 もう 1 つの利点は、グローバル メモリ アクセスは非常に時間がかかり、結果はグローバル メモリを介して 2 つの独立した cuda カーネル間で転送される必要があるため、グローバル メモリ アクセスが軽減されることです。カーネルを使用すると、結果をレジスタまたは共有メモリに転送できるため、1 つのグローバル メモリの書き込みと読み取りが回避され、パフォーマンスが向上します。 演算子融合の最初のステップは、既製の apex ライブラリを使用して Layernorm と Adam で操作を実行することです。融合については、単純な命令の置き換えにより、apex の融合されたlayernorm と融合された Adam が有効になり、それによって加速が 1.63 倍から 2.11 倍に増加することがわかります。 プロフリング ログから、演算子の融合後、要素ごとのカーネルがこのタイムラインの割合を占めていることもわかります。この比率は大幅に減少し、行列乗算が再び最大の時間を占めるカーネルになりました。 既存の apex ライブラリの使用に加えて、手動融合オペレータも開発しました。 タイムラインを観察してモデルを理解することで、Swin Transformer にはウィンドウの分割/シフト/マージなど、ウィンドウに関連する固有の操作があることがわかりました。ウィンドウ シフトには 2 つのカーネルを呼び出す必要があり、要素ごとのカーネルはシフトが完了した後に呼び出されます。さらに、そのような操作をアテンションモジュールの前に実行する必要がある場合は、その後、対応する逆の操作が行われます。ここで、ウィンドウ シフトによって呼び出される roll_cuda_kernel だけで、タイムライン全体の 4.6% を占めます。 今述べた操作は実際にはデータを分割するだけです。つまり、対応するデータは に分割されます。ウィンドウに対応する元のコードを次の図に示します。 操作のこの部分が実際には単なるインデックス マッピングであることが判明したため、この部分をオペレーター開発に統合しました。開発プロセスでは、CUDA プログラミングの関連知識を習得し、演算子の順計算と逆計算に関連するコードを記述する必要があります。 pytorch にカスタム演算子を導入する方法。公式チュートリアルが提供されています。チュートリアルに従って CUDA コードを記述し、コンパイル後に使用できます。オリジナルモデルをモジュールとして紹介します。カスタマイズした Fusion オペレーターを導入することで、さらに 2.19 倍まで高速化できることがわかります。 以下は、mha 部分に関する融合作業です。 Mha 部分は変圧器モデルの大きなモジュールであるため、これを最適化すると、多くの場合、より大きな加速効果が得られます。図からわかるように、演算子融合が実行される前は、mha 部分の演算の割合は 37.69% であり、多くの要素ごとのカーネルが含まれています。関連する操作をより高速な別のカーネルに融合できれば、高速化をさらに向上させることができます。 Swin Transformer では、クエリ、キー、値に加えて、マスクとバイアスがテンソル形式で渡されるため、オリジナルのカーネルを変換できる fMHA のようなモジュールを開発しました。統合された。 fMHA モジュールに含まれる計算から判断すると、このモジュールは Swin Transformer で発生するいくつかの形状を大幅に改善しました。 #モデルで fMHA モジュールを使用した後、加速率をさらに 2.85 倍に高めることができます。上記は 1 枚のカードで達成したトレーニング加速効果です。8 枚のカードを備えた 1 台のマシンでのトレーニング状況を見てみましょう。上記の最適化により、トレーニング スループットが 1612 から 3733 に増加できることがわかります。 2.32倍の加速を実現。 トレーニングの最適化については、加速率が高いほど良いと考えています。加速前と同じパフォーマンスを維持できます。 上記のいくつかの加速ソリューションを重ね合わせた後、モデルの収束が元のベースラインと一致していることがわかります。最適化の前後で改善され、一貫性は Swin-Tiny、Swin-Base、Swin-Large で証明されています。 # トレーニング部分に関しては、CUDA グラフ、マルチストリームなどの他のアクセラレーション戦略をすべて使用できます。 Swin Transformer のパフォーマンスはさらに向上しました。他の側面では、現在、Swin Transformer 公式リポジトリで採用されている戦略である混合精度ソリューションを導入しています。純粋な fp16 ソリューション (つまり、apex O2 モード) を使用すると、次のことを実現できます。より速い加速。 Swin には高い通信要件はありませんが、マルチノードの大規模モデルのトレーニングでは、元の分散トレーニングと比較して、合理的な戦略が使用されます。通信オーバーヘッドを隠すことで、マルチカード トレーニングでさらなる利点を得ることができます。
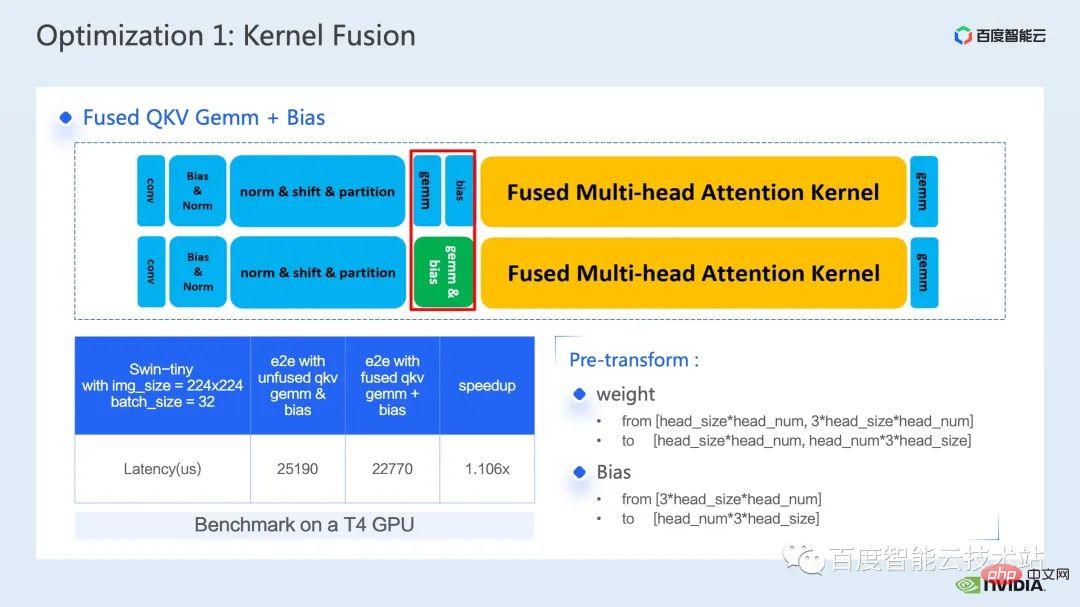
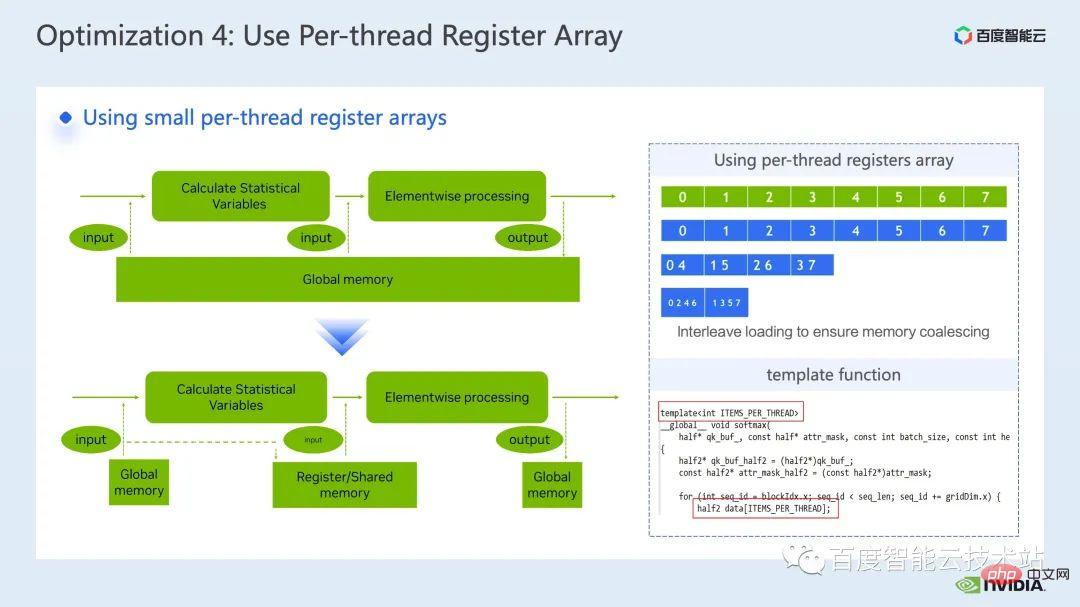
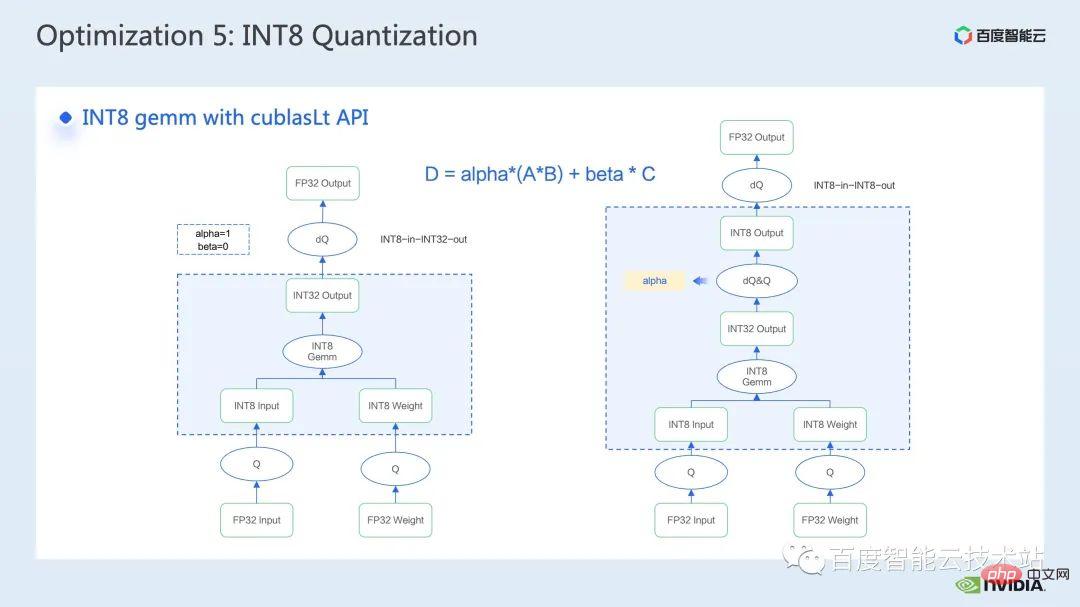
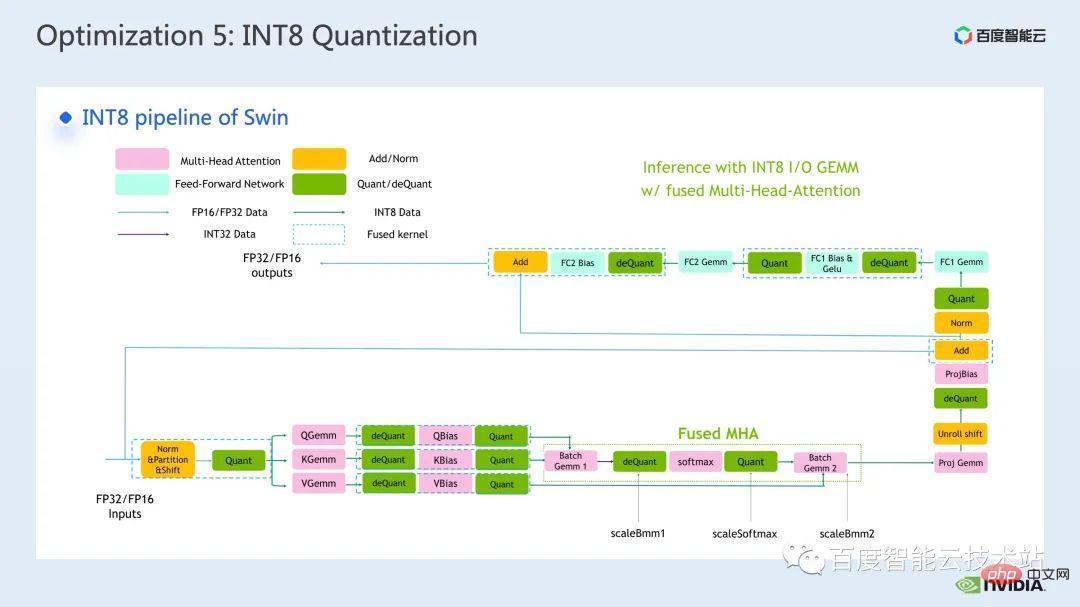
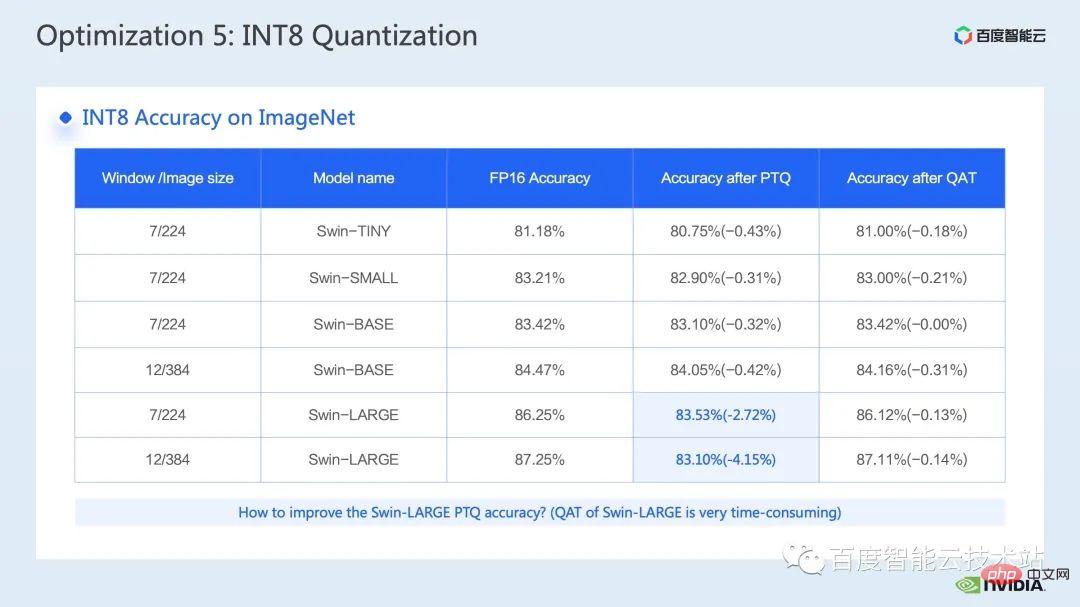
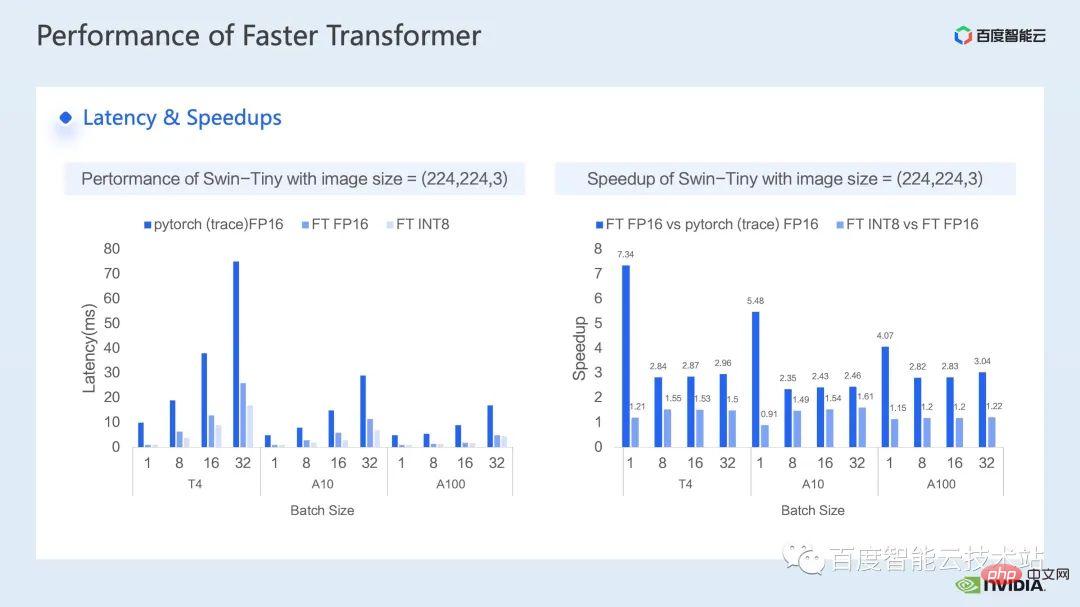
3. Swin トランスフォーマー推論の最適化 #トレーニングと同様、推論の高速化はオペレーター フュージョン ソリューションから切り離せません。ただし、トレーニングと比較して、演算子融合は推論の柔軟性に優れています。これは主に次の 2 つの点に反映されています。逆方向を考慮する必要があるため、カーネル開発プロセスでは勾配の計算に必要な中間結果の保存を考慮する必要がありません。 推論プロセスでは前処理が可能です。 、計算が 1 回だけ必要で繰り返し使用できる一部の操作を計算し、事前に計算して結果を保持し、各推論中に直接呼び出して計算の繰り返しを避けることができます。 まず第一に、行列の乗算と畳み込みを別々にリストします。これらの周りには演算子融合の大きなクラスがあるためです。行列の乗算に関連する融合については、cublas、cutlass、cudnn の使用を検討できます。ライブラリ; 畳み込みには、cudnn または Cutlass を使用できます。したがって、Transformer モデルでは、行列乗算の演算子融合については、gemm バイアス、gemm バイアス活性化関数などの gemm 要素ごとの操作として要約します。このタイプの演算子融合については、cublas または Cutlass を直接呼び出して実行することを検討できます。 。 さらに、gemm の後の操作操作が、layernorm、transpose など、より複雑な場合は、gemm とbias を分離することを検討できます。 then integratingbias into In the next op, this makes it easy to call cublas を呼び出して単純な行列乗算を実装します もちろん、このバイアスを次の op と統合するパターンでは、通常、cuda カーネルを手動で記述する必要があります。 #最後に、layernorm シフト ウィンドウ パーティションなど、cuda カーネルを手書きして融合する必要がある特定の操作がいくつかあります。 オペレーターフュージョンでは、cuda カーネルをより巧みに設計する必要があるため、一般的には、最初に nsight システムパフォーマンス分析ツールを通じてパイプライン全体を分析し、以下を優先することをお勧めします。ホットスポット モジュールは、オペレータ フュージョンの最適化を実行して、パフォーマンスとワークロードのバランスを実現します。 そこで、多くの演算子融合最適化の中から、明らかな加速効果を持つ 2 つの演算子を選択しました。 最初は、mha 部分の演算子融合です。推論のたびに検索を実行することを避けるために、位置バイアス検索操作を前処理部分に進めます。 次に、batch gemm、softmax、batch gemm を独立した fMHA カーネルにマージし、同時に転置関連の操作を fMHA カーネル I/に統合します。 O 操作。明示的な転置操作を避けるために、データの読み取りと書き込みの特定のパターンが使用されます。 #融合後、この部分は 10 倍の加速を達成し、エンドツーエンドの加速も次のように達成されたことがわかります。 1.58倍。 紹介したいもう 1 つの演算子の融合は、QKV gemmbias の融合です。 gemm とbias の融合は非常に一般的な融合方法ですが、前述の fMHA カーネルと連携するには、重みとバイアスを調整する必要があります。フォーマットを変更してください。 私がこの演算子融合をここで紹介することにした理由は、まさにこの高度な変換が前述した推論計算を具体化しているためです。 -fusion を使用すると、モデルの精度に影響を与えない範囲でモデルの推論プロセスに変更を加えることができ、それによってオペレーターの融合パターンが改善され、加速効果が向上します。 最後に、QKV gemmbias の統合により、さらに 1.1 倍のエンドツーエンドの高速化を達成できます。 #次の最適化方法は、行列乗算パディングです。 Swin Transformer の計算では、主次元が奇数の行列乗算が発生することがありますが、現時点では、行列乗算カーネルがベクトル化された読み取りと書き込みを実行するのに役立たないため、カーネルの演算効率が低くなります。このとき、演算に参加する行列の主な次元をパディングして 8 の倍数にすることを検討できます。これにより、行列乗算カーネルは一度に 8 つの要素を読み書きできます。 withalignment=8. パフォーマンスを向上させるためにベクトル化された読み取りと書き込みを実行するメソッド。 以下の表に示すように、n を 49 から 56 にパディングした後、行列乗算のレイテンシは 60.54us から 40.38us に低下し、1.5 倍を達成しました。速度向上率。 #次の最適化方法は、half2 や char4 などのデータ型を使用することです。 次のコードは、half2 最適化の例です。これは、バイアスと残差を追加する単純な演算子融合演算を実装しています。 、ハーフデータクラスと比較して、レイテンシーを 20.96us から 10.78us に短縮でき、1.94 倍の加速が可能です。 #では、half2 データ型を使用する一般的な利点は何でしょうか?主要なポイントは 3 つあります: 最初の利点は、図に示すように、ベクトル化された読み取りと書き込みによってメモリ帯域幅の利用効率が向上し、メモリ アクセス命令の数が削減できることです。下図の右側では、half2 を使用することにより、メモリ アクセス命令が半分に減り、メモリの SOL も大幅に改善されることがわかります。 #2 番目の利点は、half2 独自の高スループット演算命令を組み合わせることで、カーネル レイテンシを短縮できることです。これらの点は両方とも、このサンプル プログラムに反映されています; #3 番目の利点は、リダクション関連のカーネルを開発するときに、half2 データ型を使用することは、1 つを意味することです。 CUDA スレッドは 2 つの要素を同時に処理するため、アイドル状態のスレッドの数が効果的に削減され、スレッド同期の待ち時間が短縮されます。 #次の最適化方法は、レジスタ配列を上手に使用することです。 layernorm や Softmax などの Transformer モデルの一般的な演算子を最適化する場合、多くの場合、カーネル内で同じ入力データを複数回使用する必要があります。毎回グローバル メモリから読み取る場合、レジスタ アレイを使用してデータをキャッシュし、グローバル メモリの繰り返し読み取りを避けることができます。 レジスタは各 cuda スレッド専用であるため、カーネル設計時に各 cuda スレッドがキャッシュする必要がある要素を事前に設定する必要があります。これにより、対応するサイズのレジスタ配列が開かれ、各 cuda スレッドを担当する要素を割り当てるときに、8 つのスレッドがある場合に、下図の右上に示すように、複合アクセスを確実に達成できるようにする必要があります。 、スレッド No. 0 要素 No. 0 を処理できます。スレッドが 4 つの場合、スレッド No. 0 は要素 No. 0 と要素 No. 4 を処理します。 #一般的には、テンプレート関数を使用して、テンプレート パラメーターを通じて各 cuda スレッドのレジスタ配列サイズを制御することをお勧めします。 さらに、レジスタ配列を使用する場合は、添え字が定数であることを確認する必要があります。ループの場合、変数は添字として使用されます。ループ展開が確実に実行できるように最善を尽くす必要があります。これにより、コンパイラがローカル メモリにデータを配置する際の待ち時間が長くなります。次の図に示すように、制限を追加します。ローカル メモリの使用を回避し、ncu レポートを通じて確認できるループ条件を確認します。 最後に紹介する最適化方法は、INT8 量子化です。 INT8 量子化は、推論を高速化するための非常に重要な高速化方法です。Transformer ベースのモデルの場合、INT8 量子化はメモリ消費を削減し、より良い結果をもたらします。 Swin の場合、適切な PTQ または QAT 量子化スキームを組み合わせることで、量子化精度を確保しながら良好な高速化を実現できます。一般に、int8 量子化は、主に行列の乗算または畳み込みを量子化するために実行されます。たとえば、int8 行列の乗算では、最初に元の FP32 または FP16 入力と重みを INT8 に量子化し、次に INT8 行列乗算を実行して INT32 データに累積します。賢明に言えば、ここで逆量子化操作を実行し、FP32 または FP16 の結果を取得します。 INT8 行列乗算を呼び出すためのより一般的なツールは、cublasLt です。より良いパフォーマンスを達成するには、次のようにする必要があります。 cublasLt API のいくつかの機能を詳しく見てみましょう。 cublasLt int8 行列乗算の場合、次の図の左側に示すように、INT32 として出力するか、または次のように 2 つの出力タイプが提供されます。下図の右側に表示、INT8で出力、図中青枠のcublasLtの演算動作を表示します。 INT32 出力と比較して、INT8 出力には逆量子化および量子化操作の追加のペアがあり、一般的により多くの処理が行われることがわかります。精度は低下しますが、グローバル メモリに書き込む場合、INT8 出力は INT32 出力よりもデータ量が 3/4 少ないため、パフォーマンスが向上するため、精度とパフォーマンスの間にはトレードオフがあります。 Swin Transformer では、INT8 出力方式を使用しているため、QAT を使用すると、良好な加速比を達成することを前提として、INT8 出力が精度を確保できることがわかりました。 。 一般的に、IMMA 固有のレイアウトを使用する場合、これとの互換性が必要になる可能性があるため、列優先レイアウトを使用すると、パイプライン コード全体の開発が容易になります。レイアウト 上流および下流のカーネルだけでなく、多くの追加の操作も、この特別なレイアウトと互換性がある必要があります。ただし、IMMA 固有のレイアウトは、サイズによっては行列乗算のパフォーマンスが向上する場合があるため、int8 推論を構築したい場合は、最初にいくつかのベンチマークを実行して、パフォーマンスと開発の容易さをよりよく理解することをお勧めします。 。 #FasterTransformer では、IMMA 固有のレイアウトを使用します。次に、IMMA 固有のレイアウトを例として、cublasLt int8 行列乗算の基本的な構築プロセスといくつかの開発テクニックを簡単に紹介します。 cublasLt int8 行列乗算の基本的な構築プロセスは 5 つのステップに分けることができます。 上記は IMMA 固有のレイアウトでの構築プロセスを説明していますが、多くの制限があることがわかります。パフォーマンスに対するこれらの制限の影響を回避するために、Faster Transformer では次のテクニックを採用しています。 次は、Faster Transformer で使用する INT8 プロセスの概略図です。すべての行列乗算は int8 データ型になりました。対応する量子化ノードと逆量子化ノードは、各 int8 行列乗算の前後に挿入されます。その後、バイアスの追加、残差またはレイヤーノルムの追加などの操作については、元の FP32 または FP16 データ型が保持されます。もちろん、その I/O は int8 であってもよく、これにより FP16 や FP32 よりも優れた I/O パフォーマンスが提供されます。 ここに示されているのは、Swin Transformer int8 量子化の精度です。QAT を通じて、精度の損失が確実に保証されます。 1000分の1以内 5以内 PTQ 列を見ると、Swin-Large のポイント低下がより深刻であることがわかります。一般的に、深刻なレベルに該当する場合は、使用を検討できます。ポイントドロップの問題 量子化精度を向上させるために一部の量子化ノードを削減します もちろん、これにより加速効果が弱まる可能性があります。 FT では、FC2 および PatchMerge および量子化ノードでの int8 行列乗算の出力前に逆量子化を無効にすることができます。この最適化操作により、swin-large の PTQ 精度も大幅に向上していることがわかります。 下図の左側は最適化とpytorchのレイテンシ比較、右図は最適化後のFP16とpytorchの高速化比、INT8最適化とFP16最適化の高速化比を示しています。 。最適化により、FP16 精度で pytorch と比較して 2.82x ~ 7.34x の高速化を達成でき、INT8 量子化と組み合わせることで、これをベースにさらに 1.2x ~ 1.5x の高速化を達成できることがわかります。 #4. Swin トランスの最適化の概要 最後に、要約しましょう。この共有では、nsight システム パフォーマンス分析ツールを通じてパフォーマンスのボトルネックを見つける方法を紹介し、その後、パフォーマンス ボトルネックに対する一連のトレーニング推論高速化テクニックを紹介しました。トレーニング/低精度推論、2. 演算子融合、3. cuda カーネル最適化テクニック: 行列のゼロ パディング、ベクトル化された読み取りと書き込み、レジスタ配列の賢明な使用など。 4. 推論の最適化で前処理が使用され、推論の最適化が向上します。計算プロセス; マルチストリームと cuda グラフのいくつかのアプリケーションも紹介しました。 上記の最適化と組み合わせて、Swin-Large モデルを例として使用し、1 枚のカードで 2.85 倍、1 枚のカードで 2.32 倍の加速比を達成しました。 8 カード モデルの比; 推論の観点から、Swin-tiny モデルを例にとると、FP16 精度で 2.82x ~ 7.34x の加速比を達成し、INT8 量子化と組み合わせることで、さらに 2.82x ~ 7.34x の加速比を達成しました。 1.2倍~1.5倍。 大規模なビジュアル モデルのトレーニングと推論のための上記の高速化メソッドは、Baidu Baige AI ヘテロジニアス コンピューティング プラットフォームの AIAK に実装されました。アクセラレーション機能に実装されているので、どなたでもご利用いただけます。 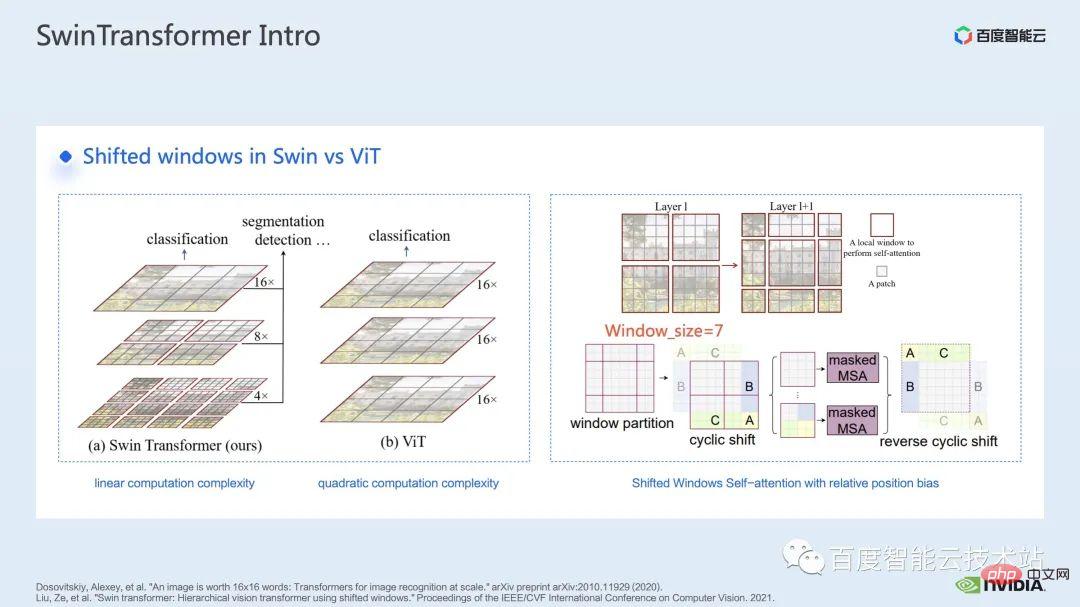















以上が大規模なビジュアル モデルを使用してトレーニングと推論を高速化するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



