


最近、LMSYS Org (カリフォルニア大学バークレー校主導) の研究者が、もう 1 つの大きなニュースを発表しました。それは、大規模な言語モデル バージョンのランキング コンテストです。
名前が示すように、「LLM ランキング」は、大規模な言語モデルのグループにランダムに戦闘を実行させ、Elo スコアに基づいてランク付けすることです。
そうすれば、あるチャットロボットが「強口王」なのか「最強王」なのかが一目でわかります。
重要なポイント: チームはまた、これらすべての「クローズド ソース」モデルを国内外から導入する予定です。 (GPT-3.5 はすでに匿名アリーナにあります)

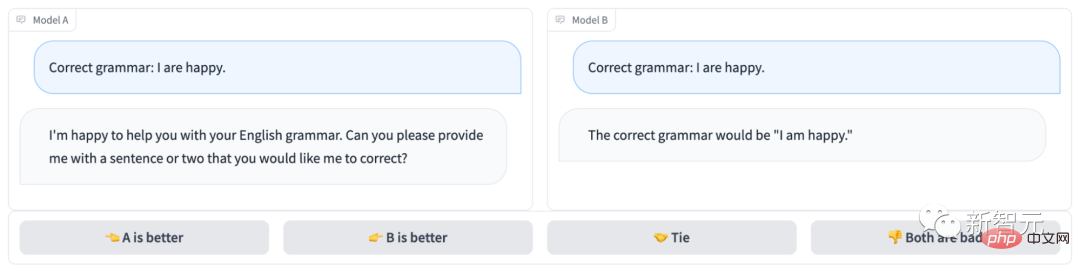
匿名チャットボット アリーナは次のようになります:
明らかに、モデル B は正しく答えてゲームに勝ちましたが、モデル A は質問さえ理解していませんでした...
##プロジェクト アドレス: https://arena.lmsys.org/
現在のランキングでは、ビクーニャが 130 億パラメータが 1169 ポイントで 1 位、130 億パラメータの Koala が 2 位、LAION の Open Assistant が 3 位でした。
清華大学によって提案された ChatGLM は、パラメーターが 60 億しかありませんが、それでもトップ 5 に食い込み、130 億のパラメーターを持つ Alpaca とわずか 23 ポイント差でした。
比較すると、Meta のオリジナル LLaMa は 8 位 (最後から 2 番目) にランクされただけで、Stability AI の StableLM はわずか 800 ポイントを獲得し、最後から 1 番目にランクされました。
チームは、ランキングリストを定期的に更新するだけでなく、アルゴリズムとメカニズムを最適化し、さまざまなタスクタイプに基づいてより詳細なランキングを提供すると述べています。

#現在、すべての評価コードとデータ分析が公開されています。
LLM をランクに引き上げるこの評価では、チームは現在よく知られている 9 つのオープンソース チャット ロボットを選択しました。
1 対 1 の戦いが行われるたびに、システムはランダムに 2 人の PK プレイヤーを引きます。ユーザーは両方のロボットと同時にチャットし、どちらのチャットボットが優れているかを判断する必要があります。
ご覧のとおり、ページの下部に 4 つのオプションがあり、左 (A) が優れている、右 (B) が優れている、同等に優れている、または両方が優れています。悪い。
ユーザーが投票を送信すると、システムはモデルの名前を表示します。この時点で、ユーザーはチャットを続けることも、新しいモデルを選択して戦闘ラウンドを再開することもできます。
ただし、分析の際、チームはモデルが匿名の場合にのみ投票結果を使用します。約 1 週間のデータ収集後、チームは合計 47,000 の有効な匿名投票を集めました。
チームは開始する前に、まずベンチマーク テストの結果に基づいて各モデルの可能な順位を把握しました。
このランキングに基づいて、チームはモデルにより適切な対戦相手を優先させます。
次に、均一なサンプリングを使用して、ランキングの全体的なカバレッジを向上させます。
予選の終わりに、チームは新しいモデル fastchat-t5-3b を導入しました。
上記の操作により、最終的にモデル周波数が不均一になります。
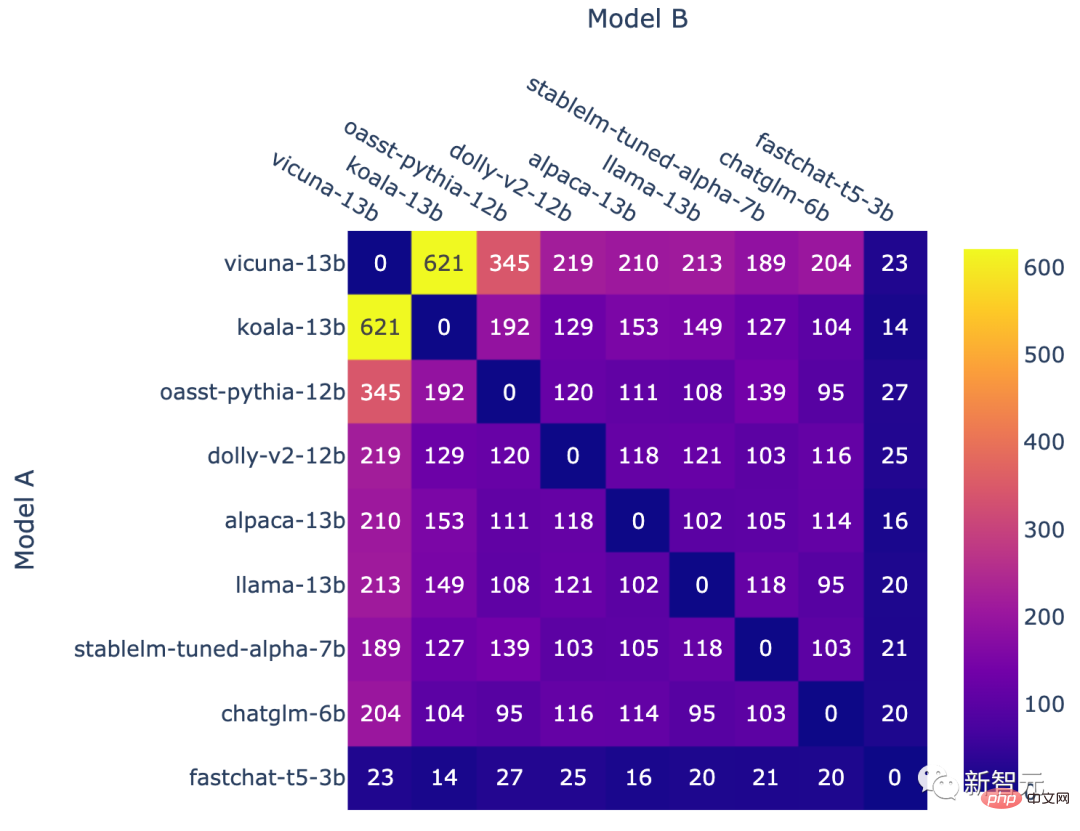
#モデルの組み合わせごとの戦闘数
統計データによると、ほとんどのユーザーは英語を使用しており、中国語が 2 番目にランクされています。
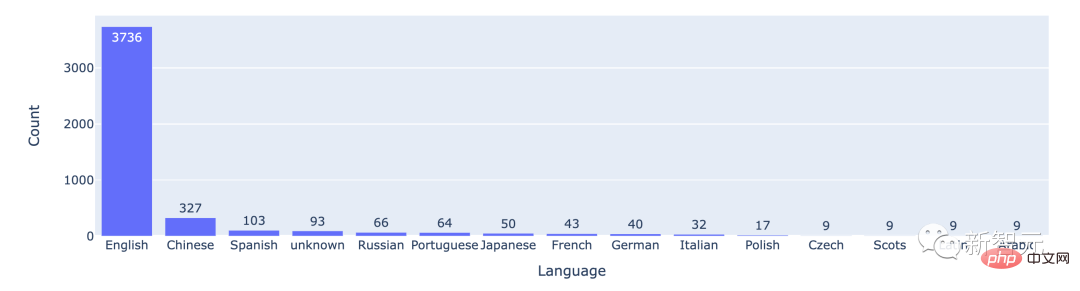
上位 15 言語での戦闘数
評価することは非常に重要ですLLM 難しいChatGPT の人気以来、指示に従って微調整されたオープンソースの大規模言語モデルが雨後の筍のように出現しました。新しいオープンソース LLM はほぼ毎週リリースされていると言えます。
しかし、問題は、これらの大規模な言語モデルを評価するのが非常に難しいことです。
具体的には、モデルの品質を測定するために現在使用されているものは、基本的に、特定の NLP タスクでテスト データ セットを構築するなど、いくつかの学術的なベンチマークに基づいています。テストデータセットの精度。
ただし、これらの学術ベンチマーク (HELM など) は、大規模なモデルやチャット ロボットで使用するのは簡単ではありません。理由は次のとおりです:
1. チャットボットがチャットに優れているかどうかの判断は非常に主観的なため、既存の方法で測定することは困難です。
2. これらの大規模なモデルはトレーニング中にインターネット上のほぼすべてのデータをスキャンするため、テスト データ セットが見られていないかどうかを確認するのは困難です。さらに一歩進んで、テスト セットを使用してモデルを直接「特別にトレーニング」すると、パフォーマンスが向上します。
3. 理論上は、チャットボットと何でもチャットできますが、多くのトピックやタスクは既存のベンチマークに存在しません。
これらのベンチマークを使用したくない場合は、実際には別の方法があります。それは、誰かにお金を払ってベンチマークを実行してもらうことです。それはモデルのスコアリングです。
実際、これが OpenAI の機能です。しかし、この方法は明らかに非常に時間がかかり、さらに重要なことに、コストがかかりすぎます...
この厄介な問題を解決するために、UC バークレー、UCSD、CMU のチームは新しい方法を発明しました。楽しくて実用的な仕組み - チャットボット アリーナ。
# これと比較して、戦闘ベースのベースライン システムには次の利点があります:
Elo レーティング システム
Elo レーティング システムは、プレーヤーの相対的なスキル レベルを計算する方法であり、対戦ゲームやさまざまなスポーツで広く使用されています。このうち、Elo スコアが高いほど、プレイヤーは強力になります。たとえば、League of Legends、Dota 2、Chicken Fighting などでは、これはシステムがプレイヤーをランク付けするメカニズムです。
たとえば、League of Legends でランク付けされたゲームを多数プレイすると、非表示のスコアが表示されます。この隠されたスコアはあなたのランクを決定するだけでなく、ランク付けされたプレイ中に遭遇する対戦相手が基本的に同様のレベルであるかどうかも決定します。 さらに、この Elo スコアの値は絶対的なものです。つまり、将来的に新しいチャットボットが追加された場合でも、Elo のスコアを通じてどのチャットボットがより強力であるかを直接判断できます。 # 具体的には、プレーヤー A のレーティングが Ra で、プレーヤー B のレーティングが Rb である場合、プレーヤー A の勝利確率の正確な式 (底 10 のロジスティック曲線を使用) は次のとおりです。 
その後、プレイヤーの評価は各試合後に直線的に更新されます。
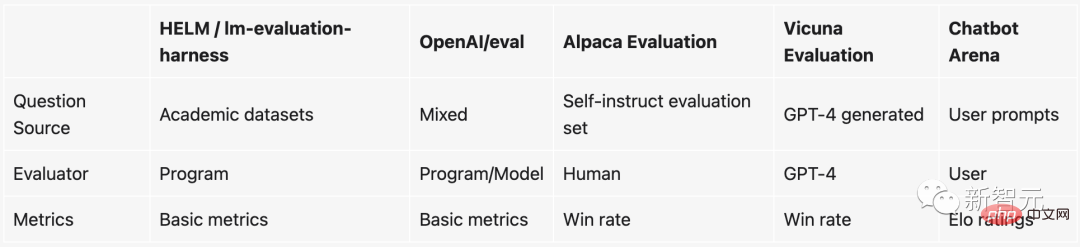
プレイヤー A (Ra 評価) が Ea ポイントを獲得すると予想していましたが、実際には Sa ポイントを獲得したとします。このプレーヤーの評価を更新するための式は次のとおりです:
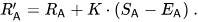
結果は、Elo スコアが確かに比較的正確に予測できることを示しています
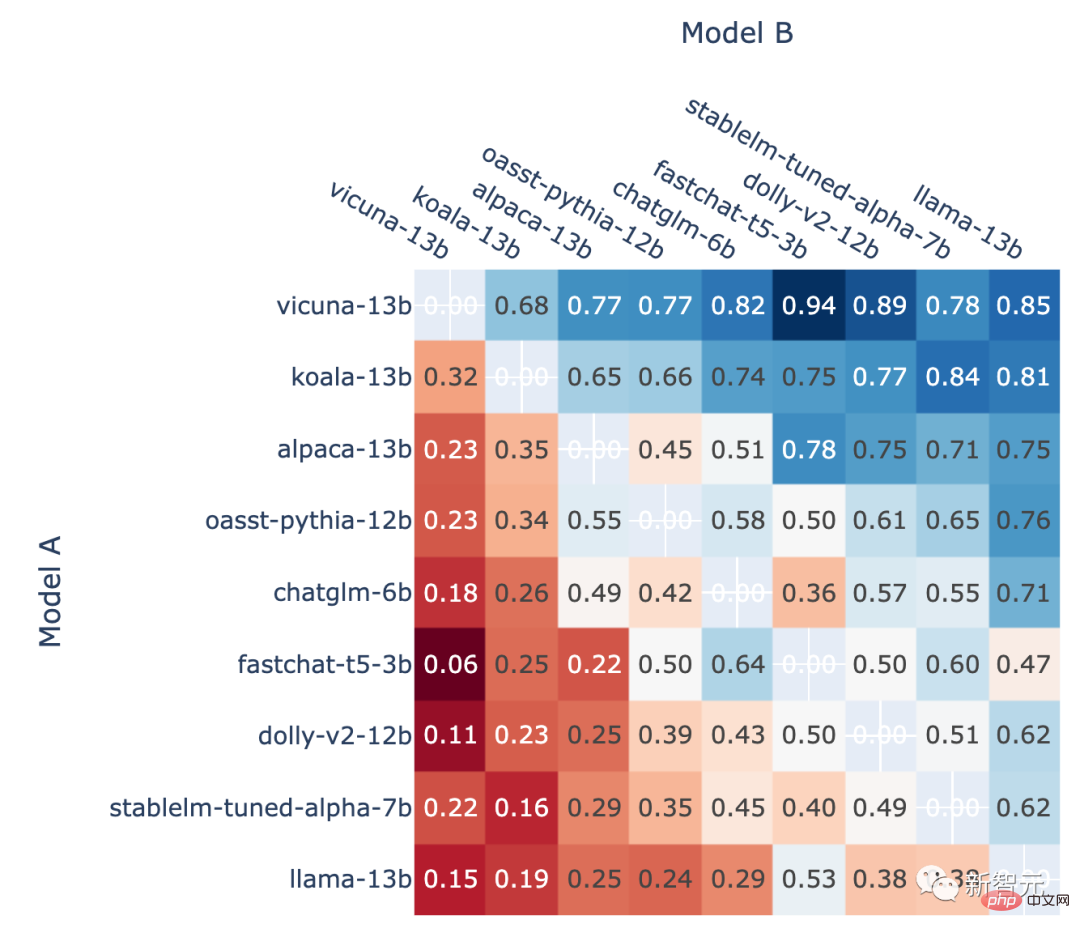
すべて非引き分け A 対 B の戦いでモデル A が勝つ割合
著者紹介
この機関は、オープン データ セット、モデル、システムと評価ツール。大規模なモデルを入手します。
 ##Lianmin Zheng
##Lianmin Zheng
Hao Zhang
以上がカリフォルニア大学バークレー校が大規模言語モデルのランキングを発表! Vicuna が優勝、Tsinghua ChatGLM がトップ 5 にランクインの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



