



Numpy は、Python 科学計算のコア モジュールです。これは、非常に効率的な配列オブジェクトと、これらの配列オブジェクトを操作するためのツールを提供します。 Numpy 配列は、すべて同じ型の多くの値で構成されます。
Python のコア ライブラリは List リストを提供します。リストは最も一般的な Python データ型の 1 つであり、サイズを変更したり、さまざまな型の要素を含めることができるため、非常に便利です。
それでは、List と Numpy 配列の違いは何でしょうか?ビッグデータを処理するときに Numpy Array を使用する必要があるのはなぜですか?答えはパフォーマンスです。
Numpy データ構造は、次の点でパフォーマンスが向上します:
1. メモリ サイズ - Numpy データ構造は、使用するメモリが少なくなります。
2. パフォーマンス - Numpy の最下層は C 言語で実装されており、リストよりも高速です。
3. 演算メソッド - 組み込みの最適化された代数演算およびその他のメソッド。
以下では、ビッグ データ処理におけるリストに対する Numpy 配列の利点について説明します。
List の代わりに Numpy 配列を適切に使用すると、メモリ使用量を 20 分の 1 に削減できます。
Python のネイティブ List の場合、新しいオブジェクトが追加されるたびに、新しいオブジェクトを参照するために 8 バイトが必要になり、新しいオブジェクト自体は 28 バイトを占有します (整数を例に挙げます)。したがって、リストのサイズは次の式で計算できます:
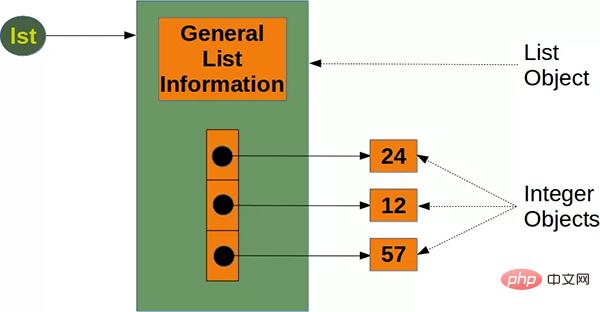
while Numpy を使用すると、占有されるスペースを大幅に削減できます。たとえば、長さ n の Numpy 整数配列には次のものが必要です:

配列が大きくなるほど、配列が大きくなることがわかります。 、節約できるお金が増えるほど、メモリスペースが増えます。配列に 10 億の要素があると仮定すると、メモリ使用量の違いは GB レベルになります。
次のスクリプトを実行すると、特定の次元の 2 つの配列も生成され、それらが加算されます。ネイティブの List と Numpy 配列が表示されます。パフォーマンスのギャップ。
import time
import numpy as np
size_of_vec = 1000
def pure_python_version():
t1 = time.time()
X = range(size_of_vec)
Y = range(size_of_vec)
Z = [X[i] + Y[i] for i in range(len(X)) ]
return time.time() - t1
def numpy_version():
t1 = time.time()
X = np.arange(size_of_vec)
Y = np.arange(size_of_vec)
Z = X + Y
return time.time() - t1
t1 = pure_python_version()
t2 = numpy_version()
print(t1, t2)
print("Numpy is in this example " + str(t1/t2) + " faster!")
結果は次のとおりです:
0.00048732757568359375 0.0002491474151611328 Numpy is in this example 1.955980861244019 faster!
ご覧のとおり、Numpy はネイティブ配列より 1.95 倍高速です。
注意して見ると、Numpy 配列が直接加算演算を実行できることもわかります。ネイティブ配列ではこのようなことはできませんが、これが Numpy の演算方法の利点です。
このパフォーマンス上の利点が永続的であることを証明するために、さらにいくつかの実験を繰り返します。
import numpy as np
from timeit import Timer
size_of_vec = 1000
X_list = range(size_of_vec)
Y_list = range(size_of_vec)
X = np.arange(size_of_vec)
Y = np.arange(size_of_vec)
def pure_python_version():
Z = [X_list[i] + Y_list[i] for i in range(len(X_list)) ]
def numpy_version():
Z = X + Y
timer_obj1 = Timer("pure_python_version()",
"from __main__ import pure_python_version")
timer_obj2 = Timer("numpy_version()",
"from __main__ import numpy_version")
print(timer_obj1.timeit(10))
print(timer_obj2.timeit(10)) # Runs Faster!
print(timer_obj1.repeat(repeat=3, number=10))
print(timer_obj2.repeat(repeat=3, number=10)) # repeat to prove it!
結果は次のとおりです:
0.0029753120616078377 0.00014940369874238968 [0.002683573868125677, 0.002754641231149435, 0.002803879790008068] [6.536301225423813e-05, 2.9387418180704117e-05, 2.9171351343393326e-05]
2 番目の出力時間が常に大幅に短いことがわかり、このパフォーマンス上の利点が持続していることがわかります。
したがって、財務データや株式データなどのビッグデータ調査を行っている場合、Numpy を使用すると、メモリ領域を大幅に節約し、より強力なパフォーマンスを得ることができます。
参考文献: //m.sbmmt.com/link/5cce25ff8c3ce169488fe6c6f1ad3c97
私たちの記事はここで終わります、よろしければ引き続きフォローしてください今日のPython実践チュートリアルです。
以上がPython ビッグデータではなぜ Numpy 配列を使用する必要があるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



