


最近、上海デジタルブレイン研究所(以下、デジタルブレイン研究所)は、初の大規模デジタルブレインマルチモーダル意思決定モデル(DB1)を立ち上げ、国内のこの領域のギャップを明らかにし、テキスト、画像テキスト、強化学習の意思決定、および運用最適化の意思決定における事前トレーニング済みモデルの可能性をさらに検証します。現在、DB1 コードを Github でオープンソース化しています (プロジェクト リンク: https://github.com/Shanghai-Digital-Brain-Laboratory/BDM-DB1)。
以前、数理科学研究所は MADT (https://arxiv.org/abs/2112.02845)/MAT (https://arxiv.org/abs/2205.14953) とその他のマルチインテリジェンス インテリジェンス ボディ モデルでは、いくつかの大規模なオフライン モデルでのシーケンス モデリングを通じて、Transformer モデルを使用していくつかの単一/マルチ エージェント タスクで顕著な結果を達成しており、この方向での研究と探索は継続しています。
ここ数年、事前トレーニングされた大規模モデルの台頭により、学界と産業界は事前トレーニングされたモデルのパラメーター量とマルチモーダル タスクにおいて新たな進歩を続けてきました。大規模な事前トレーニング モデルは、大量のデータと知識の詳細なモデリングを通じて、一般的な人工知能への重要なパスの 1 つであると考えられています。意思決定インテリジェンスの研究に重点を置くデジタル研究所は、事前トレーニング済みモデルの成功を意思決定タスクに模倣するという革新的な試みを行い、ブレークスルーを達成しました。
以前、DeepMind は、単一エージェントの意思決定タスク、複数ラウンドの対話、画像を統合する Gato を立ち上げました。 Transformer の自己回帰問題に基づいて、604 の異なるタスクで良好なパフォーマンスを達成し、いくつかの単純な強化学習意思決定問題がシーケンス予測を通じて解決できることを示しました。これは、数学研究所の研究の方向性を検証しています。大規模な意思決定モデルの方向性。
今回、数研が立ち上げたDB1は主にGatoを再現・検証し、ネットワーク構造とパラメータ量、タスクの種類とタスク数の側面から検証してみました。改善:
DB1 の全体的なパフォーマンスは Gato と同等のレベルに達しており、より実際のビジネスに近い需要フィールド本体に向けて進化し始めていることがわかります。 NP ハード TSP 問題は、Gato によってこれまでこの方向で検討されていませんでした。
 #DB1 (右) インジケーターと GATO (左) インジケーターの比較
#DB1 (右) インジケーターと GATO (左) インジケーターの比較
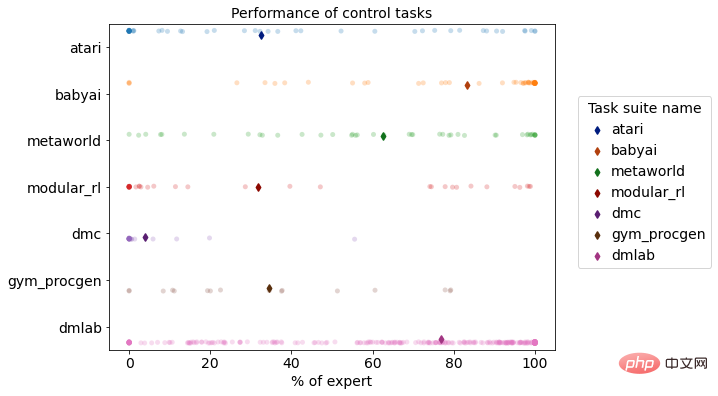
強化学習シミュレーション環境における DB1 のマルチタスクのパフォーマンス分布
従来の意思決定アルゴリズムと比較して、DB1 はクロスタスク意思決定機能と高速移行機能において優れたパフォーマンスを発揮します。タスク間の意思決定能力とパラメータ量の点で、単一の複雑なタスクの数千万のパラメータから、複数の複雑なタスクの数十億のパラメータへの飛躍を達成し、成長を続けており、問題を解決する能力を備えています。複雑なビジネス環境における問題を解決し、実際的な問題を解決する適切な能力。移行機能の点で、DB1 はインテリジェントな予測からインテリジェントな意思決定へ、そしてシングル エージェントからマルチ エージェントへの飛躍を完了し、タスク間移行における従来の方法の欠点を補い、大規模なモデルの構築を可能にしました。企業内で。
DB1 も、開発プロセスで多くの困難に直面したことは否定できません。デジタル研究所は、大規模なモデルのトレーニングと複数のモデルを業界に提供するために多くの試みを行ってきました。タスク トレーニング データ ストレージ。いくつかの標準的なソリューション パスを提供します。モデルパラメータが10億パラメータに達し、タスクの規模が巨大になり、100T(300Bトークン)を超えるエキスパートデータでトレーニングする必要があるため、通常の深層強化学習トレーニングフレームワークでは、高速トレーニングの要件を満たすことができなくなりました。この状況。このため、一方で、数理研では、分散学習において、強化学習、演算最適化、大規模モデル学習などの計算構造を十分に考慮しています。 、ハードウェア リソースを最大限に活用し、モジュールを巧みに設計し、2 つのモデル間の通信メカニズムにより、モデルのトレーニング効率を最大化し、870 タスクのトレーニング時間を 1 週間に短縮します。一方、分散ランダムサンプリングでは、学習プロセスに必要なデータのインデックス作成、保存、読み込み、前処理もボトルネックとなっており、数研研究所はデータセットを読み込む際に遅延読み込みモードを採用して問題を解決しました。メモリ制限を軽減し、利用可能なメモリを最大限に活用します。さらに、ロードされたデータを前処理した後、処理されたデータがハードディスクにキャッシュされるため、後で前処理されたデータを直接ロードできるため、前処理の繰り返しによる時間とリソースのコストが削減されます。
現在、OpenAI、Google、Meta、Huawei、Baidu、DAMO Academy などの国内外の大手企業や研究機関がマルチモーダル大規模モデルの研究を行っており、自社製品への適用やモデル API や関連業界ソリューションの提供など、商業化の試み。対照的に、数理科学研究所は意思決定の問題により重点を置き、ゲーム AI 意思決定タスク、オペレーションズ リサーチ最適化 TSP 解決タスク、ロボット意思決定制御タスク、ブラックボックス最適化解決タスク、およびマルチラウンドダイアログタスク。
オペレーション リサーチの最適化: TSP 問題解決
中国語による都市をノードとした部分 TSP 問題
強化学習タスクのビデオデモ
DB1 モデルの完成 870 後さまざまな意思決定タスクをオフラインで学習した結果、タスクの 76.67% が専門家レベルの 50% 以上に達したことが評価結果でわかりました。以下は、いくつかのタスクの効果を示しています。

アタリブレイクアウト

##DMLab オブジェクトの場所の探索

連続制御シナリオ: ロボット工学分野の連続制御タスクでは、DB1 は連続アクションのポリシー出力をモデル化し、シミュレーションで適切に完了することもできます。タスク。
#Metaworld PlateSlide

テキスト-画像タスク
テキスト生成: テキスト プロンプトを表示し、長いテキストの説明を生成します

以上が上海デジタルブレイン研究所が、超複雑な問題に対する迅速な意思決定を実現できる中国初の大規模マルチモーダル意思決定モデル DB1 をリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



