


##コア部分: CPU、メモリ
1.CPU の内部構造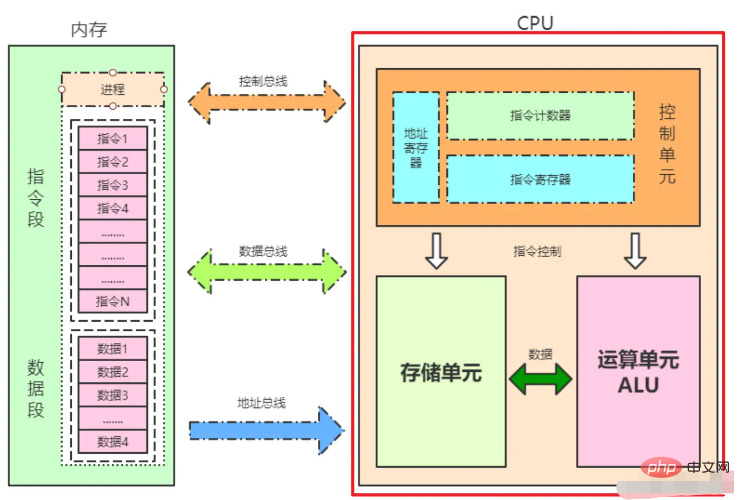
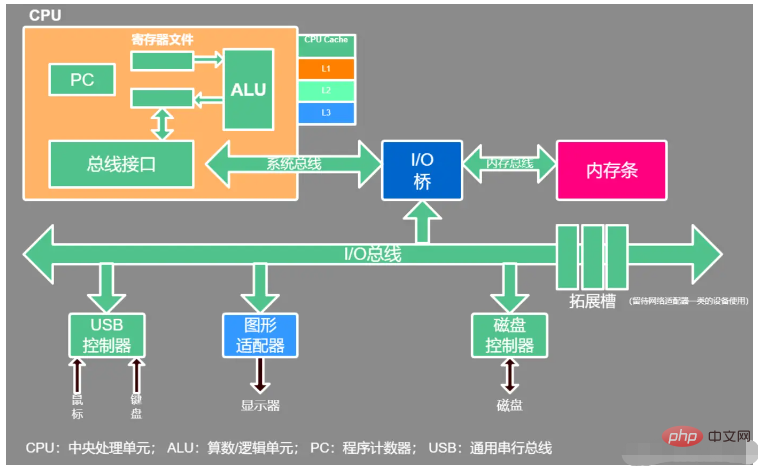
CPU 全体のコマンド アンド コントロール センター
CPU を含む) -チップ キャッシュ キャッシュ と レジスタ グループ##1.1.CPU キャッシュ構造
実行効率を向上させるために、最新の CPU は相互作用を減らします。 CPU とメモリ (相互作用は CPU 効率に影響します)、一般にマルチレベル キャッシュ アーキテクチャが CPU に統合されます 一般的な 3 レベル キャッシュ構造
Register
は CPU の内部コンポーネントであり、読み取りおよび書き込み速度が非常に高速です。 CPU はレジスタからデータを読み取るだけであり、各 CPU には他の CPU がアクセスできない固有のレジスタがあります。 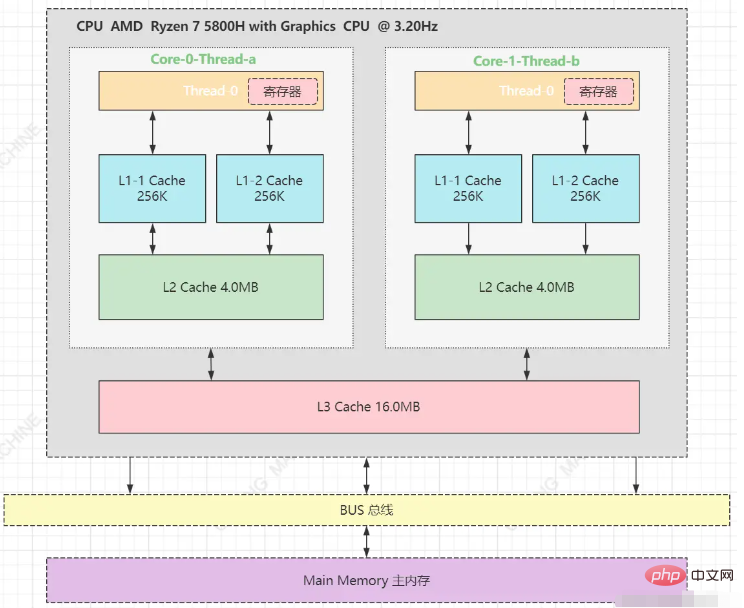 レジスタを使用すると、CPU がメモリにアクセスする回数が減り、CPU の動作速度が向上します。
レジスタを使用すると、CPU がメモリにアクセスする回数が減り、CPU の動作速度が向上します。
CPU に近づくほど、読み取り速度が速くなります . ムーアの法則によれば、CPU は 18 か月ごとに 2 倍の速度で開発されていますが、開発速度は 18 か月ごとに 2 倍になります。メモリとハードディスクの速度ははるかに速く、追いつくには程遠いです。 CPU の計算速度と I/O 速度の不一致の問題を解決するために
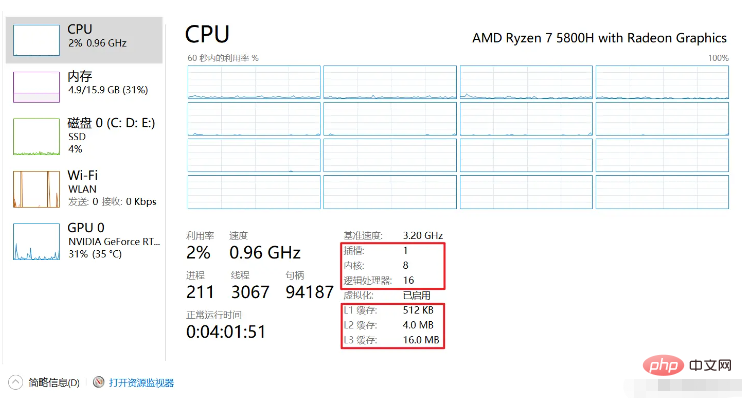
、CPU には少量の内蔵キャッシュ Lx キャッシュが搭載されるようになりました (CPU スペースとストレージ要素のサイズが制限されています)。 )。#メモリストレージスペースのサイズ: メモリ > L3 キャッシュ > L2 キャッシュ > L1 キャッシュ > レジスタ
データ x = 0 がメモリ上にあると仮定すると、その値の取得処理は次のようになります。
## メモリ読み取り速度: レジスタ > L1 キャッシュ > L2 キャッシュ > L3 キャッシュ > メモリ
キャッシュは最小のストレージで構成されますブロック --- CacheLine はブロックで構成されており、キャッシュ ライン サイズは通常 64 バイトです。私のマシン L1 のキャッシュ サイズは 512K で、512 * 1024/64 キャッシュ ラインで構成されています。
- CPU はレジスタから直接データを取得することしかできません。
CPU によるメモリ データ プロセスの読み取り:
レジスタに存在するかどうかを判定します。 存在しない場合はトラバースします。 L1 キャッシュを調べて存在するかどうかを確認します。L2 キャッシュ、L2 キャッシュ、および L3 キャッシュの走査はありません。中間プロセスが存在する場合、キャッシュ ラインはレジスタに到達するまでロックされ、上位レベルにコピーされます。
キャッシュ内に見つからない場合は、メモリ内で検索されます。まずメモリ コントローラにバス帯域幅を占有するように通知し、メモリをロックするように通知し、メモリ読み取りリクエストを開始して、待機します。応答を取得し、応答データを L3 キャッシュにコピーします。注: CPU のロックが解除されるまで、プロセス全体がロックされます。局所性の原則: CPU がストレージ デバイスにアクセスするとき、データへのアクセスでも命令へのアクセスでも、データは連続的に集まる傾向があります。エリア。局所性の原則には 2 つのタイプがあります:
時間的局所性: 情報アイテムがアクセスされている場合、そのため、近い将来再びアクセスされる可能性があります。たとえば、ループ、再帰、メソッドの繰り返し呼び出しなどです。
空間的局所性: 記憶場所が参照されると、将来的にはその近くの場所も参照されます。たとえば、連続して実行されるコード、連続して作成される 2 つのオブジェクト、配列などです。
空間的局所性の例: 大規模な 2 次元配列の場合、行ごとの累積合計は列ごとの合計よりもはるかに高速です。 CPU がメモリ内のデータを読み取ると、添付されているすべてのデータが読み込まれます。
CPU は 4 つの動作レベルに分かれています:
ring0
カーネル状態ring1
ring2
ring3 ユーザーモード
Linux と Windows では、ring0、ring3 の 2 つのレベルのみが使用されます。オペレーティング システム内の内部プログラム命令は、通常、ring0 レベルで実行されます。オペレーティング システムの外部のサードパーティプログラムはリング 3 レベルで実行されます。サードパーティ プログラムがオペレーティング システムの内部関数を呼び出したい場合、動作セキュリティ レベルが十分ではないため、CPU の実行状態をリング 3 からリング 0 に切り替えてから、システムを実行する必要があります。関数を実行してスレッドを作成します。スレッドのブロックとウェイクアップは重い操作です。これは、CPU が動作状態を切り替える必要があるためです。
JVM スレッドの作成は CPU プロセスです:
2. オペレーティング システムのメモリ管理プログラム動作の安全な分離と安定性を確保するために、オペレーティング システムには 2 つの概念があります:
ステップ 1: CPU がリング 3 からリング 0 に切り替えてスレッドを作成します
2 番目のステップ: 作成が完了すると、CPU はリング 0 からリング 3 に戻ります
- ##3 番目のステップ: スレッドが JVM プログラムを実行します
- ステップ 4: スレッドが実行された後、それを破棄し、リング 0 に戻ります。
- ステップ 5: スレッドを破棄し、リング 0 に戻ります。 ring3
ユーザー空間とカーネル空間。 32 ビット オペレーティング システムの 4G メモリ空間を例に挙げます。
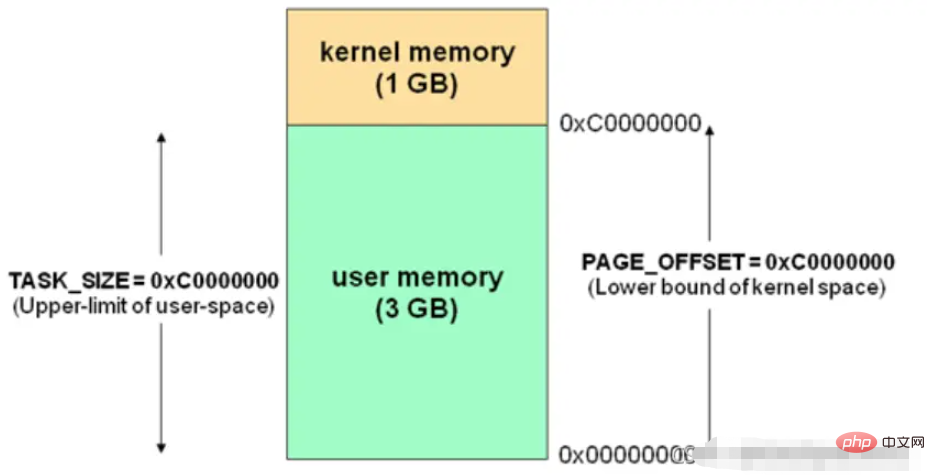
ユーザーコードおよびカーネルコード ( はユーザー空間 ) から参照できます。黄色の部分のリニア アドレス は、カーネル コード ( はカーネル空間 ) によってのみアクセスできます。
プロセスとスレッドは、usermode(usermode) または kernelmode(kernelmode) でのみ実行できます。ユーザープログラムはユーザーモードで実行され、システムコールはカーネルモードで実行されます。
ユーザー モードでは一般スタック (ユーザー空間スタック) を使用し、カーネル モードでは固定サイズのスタック (カーネル空間スタック、通常はメモリ ページのサイズ) を使用します。つまり、実際には各プロセスとスレッドが存在します。は 2 つのスタックで、それぞれユーザー モード と カーネル モードで実行されます。
CPU スケジューリングの基本単位スレッドも次のように分割されます。
によって使用されます。 Java では、カーネルはスレッドのステータスとコンテキスト情報を保存するため、スレッドのブロックによってプロセスがブロックされることはありません。マルチプロセッサ システムでは、複数のスレッドが複数のプロセッサ上で並行して実行されます。スレッドの作成、スケジューリング、管理はカーネルによって完了され、その効率は ULT より遅く、プロセス操作よりも高速です。
オペレーティング システム コアに依存せず、アプリケーションはユーザーを制御するスレッドの作成、同期、スケジュール、管理を行う機能を提供します。スレッド。ユーザーモード/カーネルモードの切り替えが不要で高速です。カーネルは ULT を認識しません。スレッドがブロックされると、プロセス (そのすべてのスレッドを含む) がブロックされます。
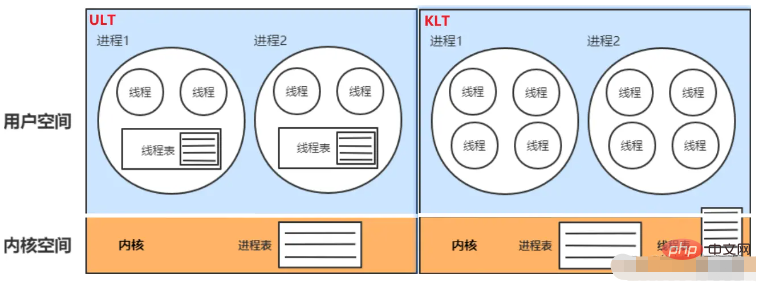 スレッドには 2 つのスタックがあり、1 つはユーザー空間 、カーネル空間に 1 つ。スレッドをブロック、作成、強制終了すると、ユーザー空間スタックが破棄されてカーネル空間に転送され、実行完了後にユーザー空間に転送されます。
スレッドには 2 つのスタックがあり、1 つはユーザー空間 、カーネル空間に 1 つ。スレッドをブロック、作成、強制終了すると、ユーザー空間スタックが破棄されてカーネル空間に転送され、実行完了後にユーザー空間に転送されます。
3. プロセスとスレッド
プロセス:オペレーティング システムのリソース割り当ての最小単位、例: Java プログラムを開始し、オペレーティング システムのリソースを割り当てます。システムは、複数のスレッドを含めることができる Java プロセスを作成します。
スレッド:オペレーティング システムの CPU スケジューリングの最小単位。スレッドはカウンター、スタック、ローカル変数などの独自の属性を持ち、共有メモリにアクセスできます。変数。 CPU はこれらのスレッドを高速に切り替えるため、ユーザーはこれらのスレッドが同時に実行されているように感じられます (同時実行)。
スレッドの上下切り替え:実行中の前のスレッドの中間状態を保存し、次のスレッドを実行します

時間の重複はありません。前のタスクは完了しておらず、次のタスクは待つことしかできません。
時間的に重複があります。2 つのタスクは互いに干渉することなく同時に実行されます。
2 つのタスクを実行すると相互に干渉します。 . 同時に実行されるタスクは 1 つだけです。交互実行
以上がJava の基礎となるオペレーティング システムと同時実行性についての基本的な知識は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



