


ICLR (学習表現に関する国際会議) は、機械学習に関して最も影響力のある国際学術会議の 1 つとして認識されています。
今年の ICLR 2023 カンファレンスで、Microsoft Research Asia は機械学習の堅牢性と責任ある人工知能の分野における最新の研究結果を発表しました。
その中で、マイクロソフト リサーチ アジアと韓国科学技術院 (KAIST) の学術協力の枠組みに基づく科学研究協力の成果が評価されました。その卓越した明快さ、洞察力、創造性、可能性が評価され、永続的な影響力が評価され、ICLR 2023 優秀論文賞を受賞しました。

文書アドレス: https://arxiv.org/abs/2303.14969
VTM : すべての高密度予測タスクに適応した最初の数ショット学習器高密度予測タスクは、セマンティック セグメンテーション、深度推定、エッジ検出、キーなど、コンピューター ビジョンの分野における重要なタスクのクラスです。ポイント検出待ち。このようなタスクの場合、ピクセルレベルのラベルに手動で注釈を付けると、法外なコストがかかります。したがって、少量のラベル付きデータからどのように学習して正確な予測を行うか、つまり小規模サンプル学習は、この分野での大きな関心事です。近年、小規模サンプル学習に関する研究、特にメタ学習と敵対的学習に基づくいくつかの手法は画期的な進歩を続けており、学術コミュニティから多くの注目と歓迎を集めています。
ただし、既存のコンピューター ビジョンの小規模サンプル学習方法は、通常、分類タスクやセマンティック セグメンテーション タスクなど、特定の種類のタスクを対象としています。これらは、モデル アーキテクチャとトレーニング プロセスの設計において、これらのタスクに特有の事前知識と仮定を利用することが多いため、任意の高密度予測タスクへの一般化には適していません。 Microsoft Research Asia の研究者は、少数のラベル付き画像から未表示の画像の任意のセグメントに対する高密度の予測タスクを学習できる一般的な少数ショット学習器があるかどうかという核心的な問題を調査したいと考えていました。
高密度予測タスクの目標は、入力画像からピクセルで注釈が付けられたラベルへのマッピングを学習することです。これは次のように定義できます。
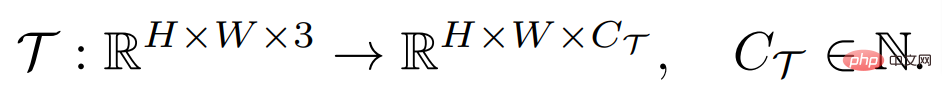
ここで、H と W はそれぞれ画像の高さと幅です。入力画像には通常 3 つの RGB チャネルが含まれており、C_Τ は出力チャネルの数を表します。異なる密予測タスクには、異なる出力チャネル番号とチャネル属性が含まれる場合があります。たとえば、セマンティック セグメンテーション タスクの出力はマルチチャネル バイナリですが、深度推定タスクの出力は単一チャネルの連続値です。一般的な少数サンプル学習器 F は、そのようなタスク Τ に対して、少数のラベル付きサンプル サポート セット S_Τ (サンプル X^i とラベル Y^i の N グループを含む) が与えられると、目に見えない画像のクエリを学習できます。
##まず、統合されたアーキテクチャが必要です。この構造は、任意の密度の予測タスクを処理することができ、一般化可能な知識を得るためにほとんどのタスクに必要なパラメーターを共有し、少数のサンプルで未知のタスクの学習を可能にします。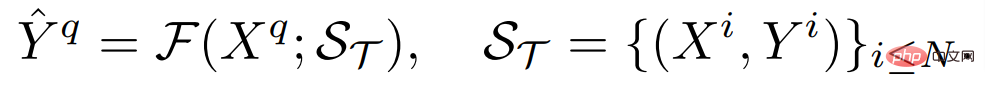
第 2 に、学習者は予測メカニズムを柔軟に調整して、過学習を防ぐのに十分な効率を保ちながら、さまざまなセマンティクスを持つ目に見えないタスクを解決する必要があります。
VTM の設計は、人間の思考プロセスの類似性にインスピレーションを得ています。新しいタスクの少数の例が与えられると、人間は、例間の類似性に基づいて、同様の出力を同様の入力にすばやく割り当てることができ、また、与えられたコンテキストに基づいて、入力と出力が類似するレベルを柔軟に適応させます。研究者らは、パッチレベルに基づいたノンパラメトリックマッチングを使用して、高密度予測のための類似プロセスを実装しました。トレーニングを通じて、モデルは画像パッチの類似点を捕捉するようになります。
新しいタスクに対して少数のラベル付きサンプルが与えられると、VTM はまず、指定されたサンプルとサンプルのラベルに基づいて類似性の理解を調整し、サンプル画像パッチをロックインします。ラベルを組み合わせることにより、類似した画像パッチを予測し、まだ見ていない画像パッチのラベルを予測します。
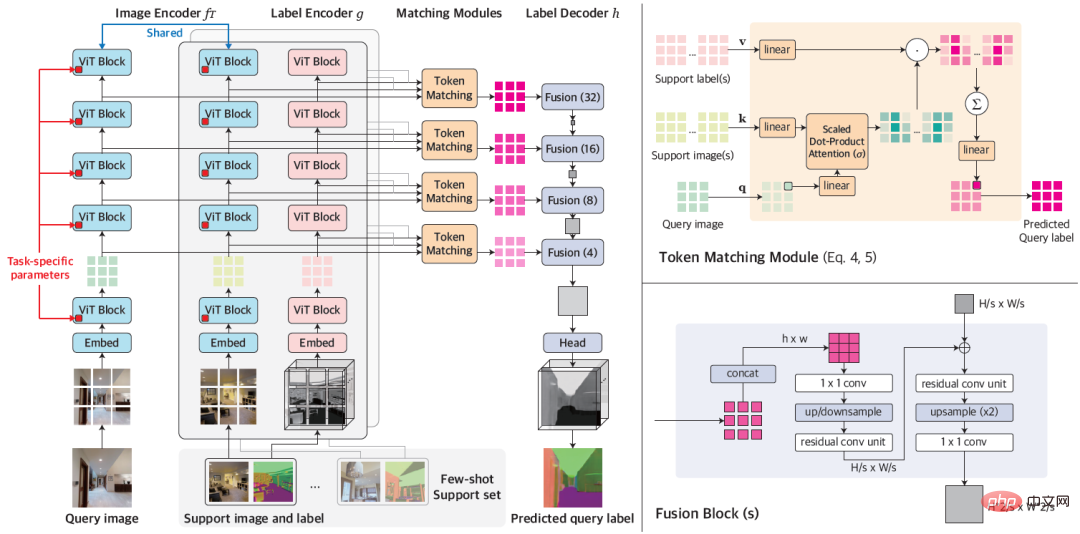
#図 1: VTM の全体的なアーキテクチャ
VTM は階層化を採用しています。エンコーダ/デコーダ アーキテクチャは、パッチベースのノンパラメトリック マッチングを複数のレベルで実装します。主に画像エンコーダ f_T、ラベルエンコーダ g、マッチングモジュール、ラベルデコーダ h の 4 つのモジュールで構成されます。クエリ画像とサポート セットが与えられると、画像エンコーダはまず各クエリとサポート画像の画像パッチレベル表現を独立して抽出します。タグ エンコーダは、タグをサポートする各タグを同様に抽出します。各レベルのラベルが与えられると、マッチング モジュールはノンパラメトリック マッチングを実行し、ラベル デコーダーが最終的にクエリ画像のラベルを推測します。
VTM の本質はメタ学習手法です。そのトレーニングは複数のエピソードで構成されており、各エピソードは小さなサンプルの学習問題をシミュレートします。 VTM トレーニングでは、メタトレーニング データセット D_train が使用されます。これには、高密度予測タスクのさまざまなラベル付きサンプルが含まれています。各トレーニング エピソードは、サポート セットが与えられたクエリ画像の正しいラベルを生成することを目的として、データセット内の特定のタスク T_train の数ショット学習シナリオをシミュレートします。モデルは、複数の小さなサンプルから学習する経験を通じて、新しいタスクに迅速かつ柔軟に適応するための一般知識を学習できます。テスト時、モデルはトレーニング データ セット D_train に含まれていないタスク T_test に対して少数ショット学習を実行する必要があります。
任意のタスクを扱う場合、メタトレーニングやテストにおける各タスクの出力次元 C_Τ が異なるため、すべてのタスクに対して統一された一般的なモデルパラメータを設計することは大きな課題になります。シンプルで一般的な解決策を提供するために、研究者らはタスクを C_Τ 単一チャネルのサブタスクに変換し、各チャネルを個別に学習し、共有モデル F を使用して各サブタスクを独立してモデル化しました。
VTM をテストするために、研究者らはまた、目に見えない高密度予測タスクのスモールショット学習をシミュレートするために、Taskonomy データセットのバリアントを特別に構築しました。 Taskonomy には注釈付きのさまざまな屋内画像が含まれており、研究者らはその中からセマンティクスと出力次元が異なる 10 個の高密度予測タスクを選択し、相互検証のためにそれらを 5 つの部分に分割しました。各分割では、2 つのタスクがスモールショット評価 (T_test) に使用され、残りの 8 つのタスクがトレーニング (T_train) に使用されます。研究者らは、新しいセマンティクスによるタスクの評価を可能にするために、エッジ タスク (TE、OE) をテスト タスクにグループ化するなど、トレーニング タスクとテスト タスクが互いに十分に異なるようにパーティションを慎重に構築しました。
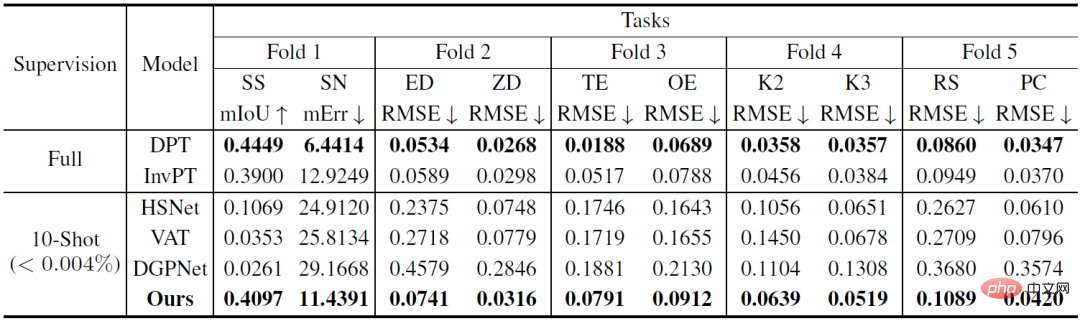
#表 1: Taskonomy データセットの定量的比較 (他のパーティションからタスクをトレーニングした後の少数ショットのベースライン) 10 ショット学習はテスト対象の分割タスクで実行され、完全に監視されたベースラインが各フォールド (DPT) またはすべてのフォールド (InvPT) でトレーニングおよび評価されました)
表 1 と図 2 は、それぞれ 10 個の集中予測タスクにおける VTM と 2 種類のベースライン モデルの小サンプル学習パフォーマンスを定量的および定性的に示しています。その中でも、DPT と InvPT は最も先進的な教師あり学習手法であり、DPT は単一タスクごとに独立してトレーニングできるのに対し、InvPT はすべてのタスクを共同でトレーニングできます。 VTM の前には一般的な高密度予測タスク用に開発された専用の小サンプル手法がなかったため、研究者らは VTM を 3 つの最先端の小サンプル セグメンテーション手法 (DGPNet、HSNet、VAT) と比較し、それらを拡張して A を処理できるようにしました。高密度予測タスク用の一般的なラベル空間。 VTM はトレーニング中にテスト タスク T_test にアクセスできず、テスト時に少数 (10) のラベル付き画像のみを使用しましたが、すべてのスモールショット ベースライン モデルの中で最高のパフォーマンスを発揮し、多くのタスクで良好なパフォーマンスを発揮しました。監視されたベースライン モデル。
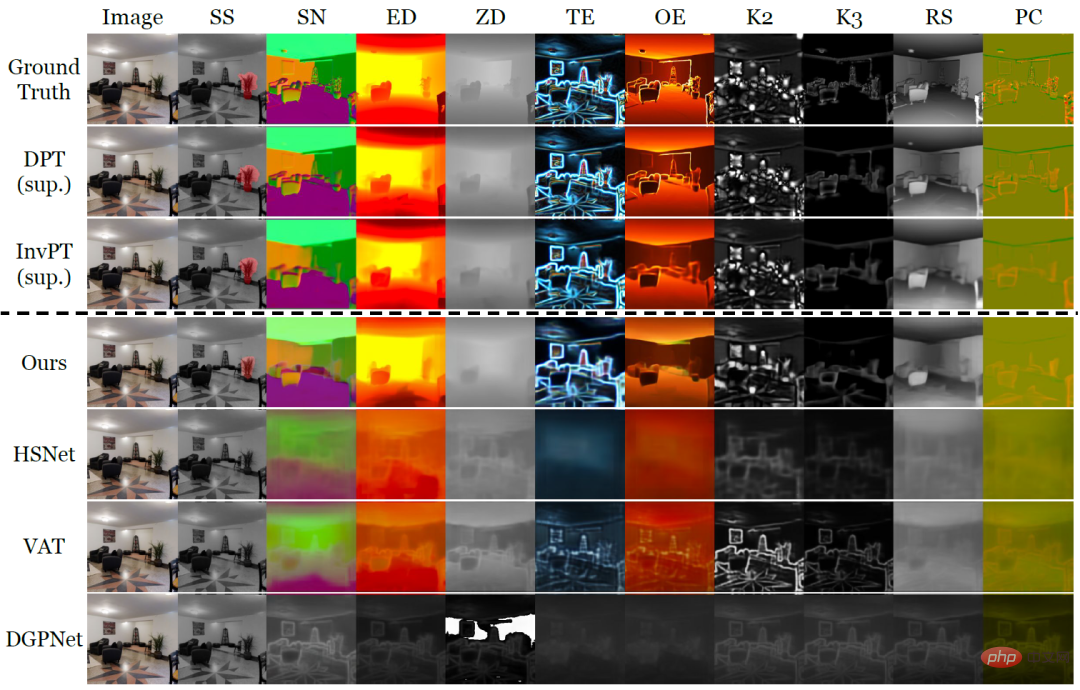
図 2: Taskonomy の 10 個の集中予測タスクのうち、新しいタスクに関する 10 個のラベル付き画像のみの小さなサンプル学習方法。他の方法では失敗しましたが、VTM は、異なるセマンティクスと異なるラベル表現を持つすべての新しいタスクを正常に学習しました。
図 2 では、点線の上に実際のラベルと 2 つの教師あり学習手法 DPT と InvPT がそれぞれ示されています。点線の下は小規模サンプルの学習方法です。特に、VTM はすべてのタスクを正常に学習しましたが、他の小規模サンプルのベースラインでは新しいタスクで壊滅的なアンダーフィッティングが発生しました。実験では、VTM が、非常に少数のラベル付きサンプル (
要約すると、VTM の基礎となる考え方は非常にシンプルですが、統合されたアーキテクチャを備えており、あらゆる高密度予測タスクに使用できます。マッチング アルゴリズムには、基本的にすべてのタスクとラベル構造 (連続または離散など) が含まれます。さらに、VTM は少数のタスク固有のパラメータのみを導入するため、オーバーフィッティングに強く、柔軟性が高くなります。将来的に研究者らは、タスクの種類、データ量、データ分布が事前トレーニングプロセス中のモデル汎化パフォーマンスに及ぼす影響をさらに調査し、それによって真に汎用的な小サンプル学習器の構築に役立てたいと考えています。
以上がユニバーサル フューショット学習器: 広範囲の高密度予測タスク用のソリューションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



