


今月初め、Meta は「Segment Anything」AI モデル、つまり Segment Anything Model (SAM) をリリースしました。 SAM は画像セグメンテーションの普遍的な基本モデルと考えられており、オブジェクトに関する一般的な概念を学習し、トレーニング プロセス中に遭遇しなかったオブジェクトや画像タイプを含む、あらゆる画像またはビデオ内のあらゆるオブジェクトのマスクを生成できます。この「ゼロサンプルマイグレーション」機能は驚くべきもので、CV分野に「GPT-3の瞬間」が到来したとさえ言う人もいる。
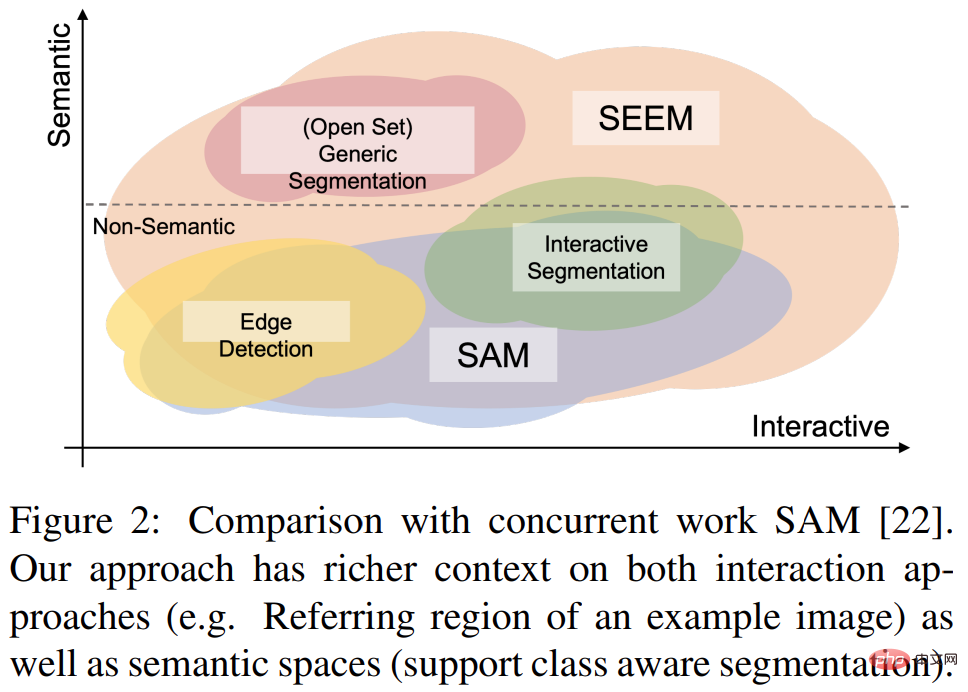
最近、「Segment Everything Everywhere All at Once」という新しい論文が再び注目を集めています。この論文では、ウィスコンシン大学マディソン校、マイクロソフト、香港科技大学の数名の中国人研究者が、新しいプロンプトベースの対話モデル SEEM を提案しました。 SEEM は、画像またはビデオ内のすべてのコンテンツを一度にセグメント化し、ユーザーによって与えられたさまざまなモーダル入力 (テキスト、画像、落書きなど) に基づいてオブジェクト カテゴリを識別できます。このプロジェクトはオープンソース化されており、誰もが体験できるトライアルアドレスが提供されています。

# 論文リンク: https://arxiv.org/pdf/2304.06718.pdf
# プロジェクトリンク: https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
#トライアルアドレス: https://huggingface.co/spaces/xdecoder/SEEM
この研究では、包括的な実験を通じて SEEM の有効性を検証しました。さまざまなセグメンテーションタスクに取り組みます。 SEEM にはユーザーの意図を理解する機能はありませんが、統一された表現空間でさまざまなタイプのプロンプトを作成することを学習するため、強力な一般化機能を示します。さらに、SEEM は軽量のプロンプト デコーダを通じて複数ラウンドのインタラクションを効率的に処理できます。
風景写真のセグメント化など、オブジェクトの種類をセグメント化することもできます。 :

SEEM では、ビデオ内の移動オブジェクトを簡単にセグメント化することもできます:
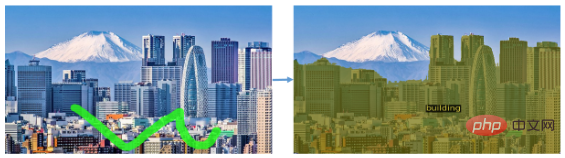
このセグメンテーション効果は非常にスムーズであると言えます。この研究で提案されたアプローチを見てみましょう。

この研究は、マルチモーダル プロンプトを利用した画像セグメンテーションのための一般的なインターフェイスを提案することを目的としています。この目標を達成するために、彼らは、汎用性、構成性、対話性、意味論的認識を含む 4 つの属性を含む新しいスキームを提案しました。ポイント、マスク、テキスト、検出ボックス(ボックス)、さらには別の画像の参照領域(参照領域)など、同じ共同視覚的意味空間内のプロンプトにエンコードされます。
2) 構成性は、視覚的プロンプトとテキスト プロンプトの共同視覚的意味空間を学習することにより、推論のためにオンザフライでクエリを作成します。 SEEM は、入力プロンプトの任意の組み合わせを処理できます。3) インタラクティブ性: この研究では、学習可能な記憶プロンプトとマスクによって誘導される相互注意を組み合わせることにより、会話履歴情報の保持が導入されています。
4) セマンティック認識: テキスト エンコーダーを使用してテキスト クエリをエンコードし、ラベルをマスクすることで、すべての出力セグメンテーション結果に対してオープンセット セマンティクスを提供します。

# アーキテクチャ的には、SEEM は単純な Transformer エンコーダ/デコーダ アーキテクチャに従い、追加のテキスト エンコード デバイスを追加します。 SEEM では、デコード プロセスは生成 LLM と似ていますが、マルチモーダル入力とマルチモーダル出力を使用します。すべてのクエリはプロンプトとしてデコーダにフィードバックされ、画像およびテキスト エンコーダは、あらゆる種類のクエリをエンコードするためのプロンプト エンコーダとして使用されます。
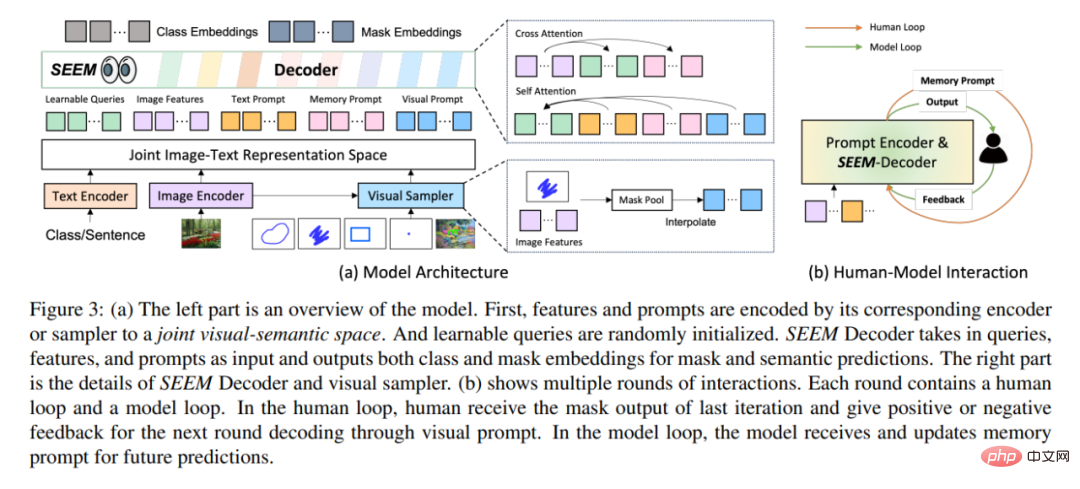
具体的には、この研究では、すべてのクエリ (ポイント、ボックス、マスクなど) を視覚的なプロンプトにエンコードします。テキスト エンコーダは、テキスト クエリをテキスト プロンプトに変換し、ビジュアル プロンプトとテキスト プロンプトの位置を合わせたままにします。 5 つの異なるタイプのプロンプトはすべて共同視覚的意味空間にマッピングでき、目に見えないユーザー プロンプトはゼロショット適応を通じて処理できます。さまざまなセグメンテーション タスクでトレーニングすることにより、モデルはさまざまなプロンプトを処理できるようになります。さらに、異なるタイプのプロンプトは相互注意を助け合うことができます。最終的に、SEEM モデルはさまざまなプロンプトを使用して、優れたセグメンテーション結果を達成できます。
SEEM は、強力な汎化機能に加えて、操作も非常に効率的です。研究者らはデコーダーへの入力としてプロンプトを使用したため、SEEM は人間との複数回の対話を通じて特徴抽出機能を最初に 1 回実行するだけで済みました。反復ごとに、新しいプロンプトを使用して軽量デコーダーを再度実行するだけです。したがって、モデルをデプロイするときに、多数のパラメーターと重いランタイム負荷を伴う特徴抽出器をサーバー上で実行し、比較的軽量のデコーダーのみをユーザーのマシン上で実行して、複数のリモート呼び出しにおけるネットワーク遅延の問題を軽減します。
上記の図 3(b) に示すように、複数ラウンドのインタラクションでは、各インタラクションに手動ループとモデル ループが含まれています。人工ループでは、人間は前の反復のマスク出力を受け取り、視覚的なプロンプトを通じて次のデコード ラウンドに向けて正または負のフィードバックを与えます。モデルのループ中に、モデルは将来の予測のためのメモリ プロンプトを受信して更新します。
実験結果この研究では、SEEM モデルと SOTA インタラクティブ セグメンテーション モデルを実験的に比較しました。結果を以下の表 1 に示します。
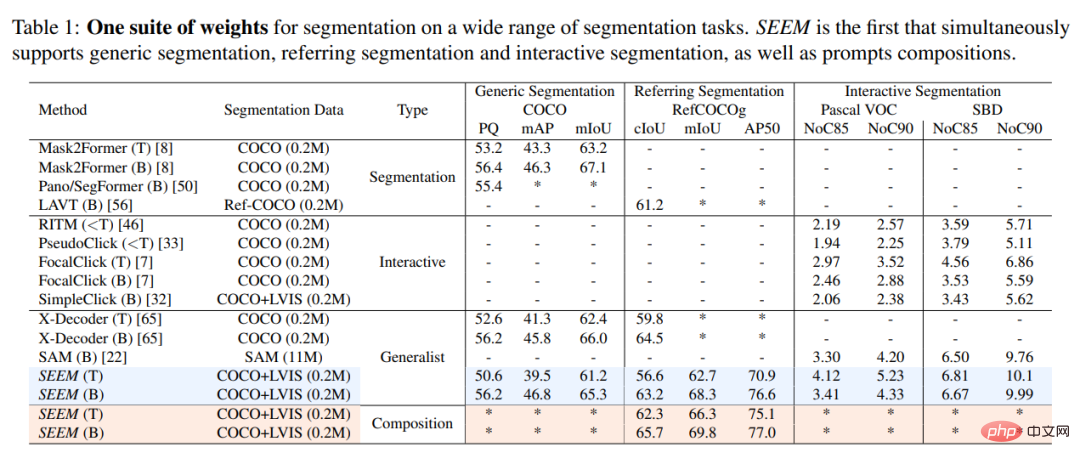
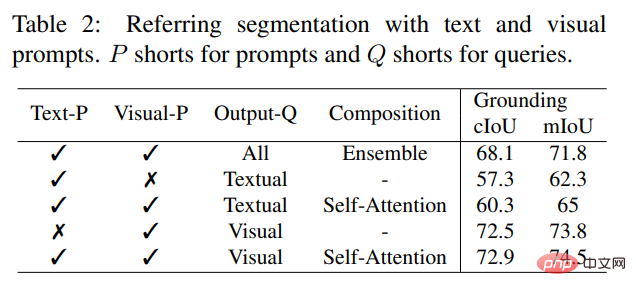
既存のインタラクティブ モデルとは異なり、SEEM は、従来のセグメンテーション タスクだけでなく、テキスト、ポイント、落書き、フレーム、画像などのさまざまなユーザー入力タイプもサポートする初のユニバーサル インターフェイスであり、強力な機能を提供します。組み合わせ能力。以下の表 2 に示すように、組み合わせ可能なプロンプトを追加することにより、SEEM は cIoU、mIoU、およびその他の指標におけるセグメンテーション パフォーマンスを大幅に向上させました。


参照画像を直接入力して参照領域を指定し、他の画像をセグメント化し、参照領域と一致するオブジェクトを検索することもできます。
#このプロジェクトはオンラインで試用できるようになりました。興味のある読者は、ぜひ試してみてください。
以上が中国のチームによって作成されたユニバーサル セグメンテーション モデルである SEEM は、ワンタイム セグメンテーションを新たなレベルに引き上げますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



