


テスト時間適応 (TTA) メソッドは、テスト フェーズ中にモデルが迅速な教師なし/自己教師あり学習を実行するようにガイドします。これは現在、ディープ モデルの分布外汎化能力を向上させるための強力かつ効果的なツールです。 。ただし、動的なオープン シナリオでは、安定性が不十分であることが依然として既存の TTA 手法の大きな欠点であり、実際の展開を大きく妨げています。この目的を達成するために、華南理工大学、テンセントAI研究所、シンガポール国立大学の研究チームは、既存のTTA手法が動的なシナリオにおいて不安定である理由を統一的な観点から分析し、依存する正規化層が脆弱であることを指摘した。安定性の主な理由の 1 つは、さらに、テスト データ ストリームにノイズや大規模な勾配がある一部のサンプルでは、縮退した自明なソリューションにモデルを簡単に最適化できることです。これに基づいて、動的なオープンシナリオでの安定かつ効率的なテスト時間モデルのオンライン移行と一般化を達成するために、シャープネスに敏感で信頼性の高いテスト時間エントロピー最小化方法SARがさらに提案されます。この研究は、ICLR 2023 Oral (受理された論文の上位 5%) に選ばれました。

従来の機械学習テクノロジーは通常、事前に収集された大量のトレーニング データを学習し、推論予測用のモデルを修正します。このパラダイムは、テスト データとトレーニング データが同じデータ分布から得られる場合に、非常に優れたパフォーマンスを達成することがよくあります。ただし、実際のアプリケーションでは、テスト データの分布が元のトレーニング データの分布から容易に逸脱する可能性があります (分布シフト)。たとえば、テスト データを収集する場合: 1) 天候の変化により、画像に雨、雪、霧が含まれます。オクルージョン; 2) 不適切な撮影により画像がぼやけている、またはセンサーの劣化により画像にノイズが含まれている; 3) モデルは北部の都市で収集されたデータに基づいてトレーニングされましたが、南部の都市にも展開されました。上記の状況は非常に一般的ですが、これらのシナリオではパフォーマンスが大幅に低下する可能性があり、現実世界 (特に自動運転などの高リスク アプリケーション) の広範な展開での使用が大幅に制限される可能性があるため、ディープ モデルにとって致命的なことがよくあります。
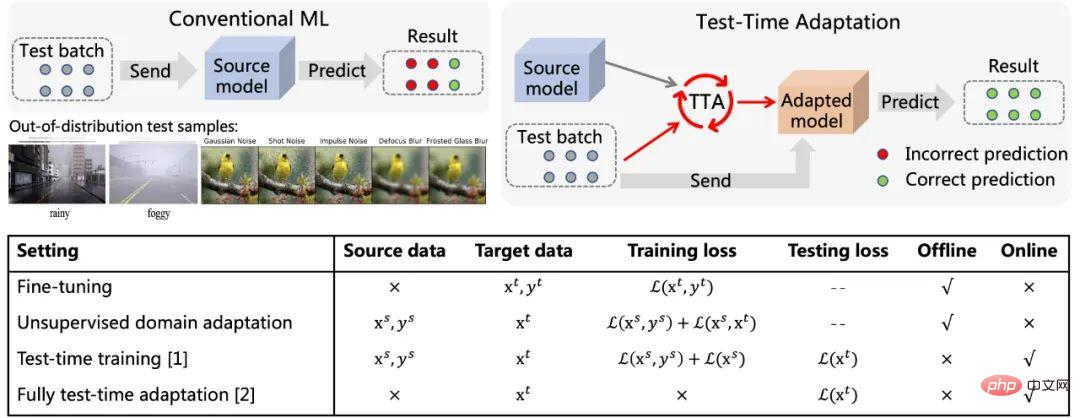
図 1 テスト時適応の概略図 ([5] を参照) および現在の方法特性の比較
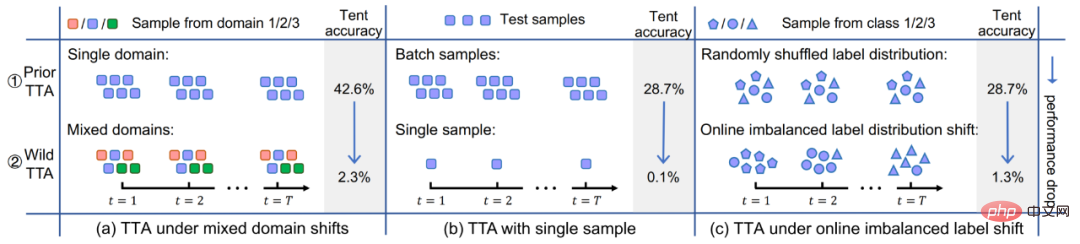
との関係は、図 1 に示すように、従来の機械学習パラダイムとは異なります。テスト サンプルが到着した後、Test-時間適応 (TTA) は、まずデータに基づいて、自己教師ありまたは教師なしの方法でモデルを微調整するために使用され、次に更新されたモデルを使用して最終予測が行われます。一般的な自己/教師なし学習の目標には、回転予測、対照学習、エントロピー最小化などが含まれます。これらの方法はすべて、優れた配布外汎化パフォーマンスを示します。従来の微調整および教師なしドメイン適応方法と比較して、テスト時適応では、より効率的でより汎用的な オンライン移行を実現できます。さらに、完全なテスト時適応方法 [2] は、元のトレーニング データやモデルの元のトレーニング プロセスへの干渉を必要とせずに、事前トレーニングされたモデルに適応できます。上記の利点により、TTA 法の実用的な汎用性が大幅に向上し、その優れたパフォーマンスと相まって、TTA は移行、一般化、およびその他の関連分野で非常に注目されている研究方向となっています。 既存の TTA 手法は、配布外の一般化において大きな可能性を示していますが、この優れたパフォーマンスは、一定期間内のデータ ストリームのサンプルなどの特定のテスト条件下で得られることがよくあります。すべてが同じ分布シフト タイプに由来し、テスト サンプルの真のカテゴリ分布は均一かつランダムであり、適応を実行する前に毎回ミニバッチ サンプルが必要になります。しかし実際には、上記の潜在的な仮定を現実のオープンワールドで常に満たすことは困難です。実際には、テスト データ ストリームは任意の組み合わせで到着する可能性があり、理想的には モデルはテスト データ ストリームの到着形式についていかなる仮定も立てるべきではありません。図 2 に示すように、テスト データ フローでは、(a) サンプルが異なる分布オフセットから取得されている (つまり、混合サンプル オフセット)、 (b) サンプル バッチ サイズが発生する可能性があります。は非常に小さい (偶数 1);(c)一定期間内のサンプルの真のカテゴリ分布は不均等であり、動的に変化します。この記事では、上記のシナリオの TTA を Wild TTA と呼びます。残念ながら、既存の TTA 手法は、このようなワイルドなシナリオでは脆弱で不安定であることが多く、移行パフォーマンスが限られており、元のモデルのパフォーマンスに損害を与える可能性さえあります。したがって、実際のシナリオで TTA 手法の大規模かつ詳細なアプリケーション展開を真に実現したい場合、Wild TTA 問題を解決することは避けられない重要な部分です。 #図 2 モデル テスト中の適応中の動的オープン シーン この記事では、TTA が多くのワイルド シナリオで失敗する理由を統一的な観点から分析し、解決策を提供します。 1. Wild TTA が不安定なのはなぜですか? (1) バッチ正規化 (BN) は、動的シナリオにおける TTA の不安定性の主な理由の 1 つです : 既存の TTA 手法は、通常、以下に基づいて確立されています。適応 BN 統計では、テスト データを使用して BN 層の平均と標準偏差が計算されます。ただし、実際の 3 つの動的シナリオでは、BN 層内の統計推定精度に偏りが生じ、TTA が不安定になります。 上記の分析をさらに検証するために、この記事では、2 つの代表的な TTA メソッド (TTT [1] および Tent [2]) に基づいて、広く使用されている 3 つのモデル (異なる BatchLayerGroup Norm を備えた) を検討します。最終的な結論は次のとおりです。 バッチに依存しない Norm レイヤー (Group および Layer Norm) は、Batch Norm の制限をある程度回避し、動的なオープン シナリオで TTA を実行するのにより適しており、安定性も高くなります## #。そのため、本記事でもGroupLayer Normを搭載したモデルをベースにメソッド設計を行っていきます。 なぜテスト時にワイルドに適応するのでしょうか?

#図 3 混合分布部分移動におけるさまざまな方法とモデル (さまざまな正規化層)パフォーマンスの低下


#図 5 オンラインの不均衡なラベル分布シフトにおけるさまざまなメソッドとモデル (さまざまな正規化層) のパフォーマンス パフォーマンスが大きいほど図の横軸の不均衡率が大きいほどラベルの不均衡が深刻であることを示します
(2) オンラインエントロピー最小化の最適化が容易モデルを縮退自明解に、つまり、任意のサンプルを同じクラスに予測します。モデルの劣化と崩壊現象、つまり、すべてのサンプル (実際のカテゴリが異なる) が同じクラスに予測されると同時に、モデルの勾配のノルムがモデルの崩壊の前後で急速に増加し、その後ほぼ 0 に低下します。図 6 (c) の側面の説明を参照してください。これは、モデル パラメーターを破壊し、モデルの崩壊を引き起こす何らかの大規模/ノイズ勾配です。

#図 6 オンライン テスト中のエントロピー最小化の失敗例の分析
2. シャープネスに敏感で信頼性の高いテスト時間エントロピー最小化手法上記のモデル劣化問題を軽減するために、この論文では、は、テスト中にシャープネスを意識した信頼性の高いエントロピー最小化手法 (SAR) を提案します。この問題は 2 つの方法で軽減されます: 1)
信頼性の高いエントロピー最小化は、モデルの適応更新から大きな/ノイズの多い勾配を生成する 一部の サンプルを削除します; 2) モデルのシャープネスの最適化 モデルは、残りの サンプルで生成される 特定のノイズ勾配 の影響を受けなくなります。具体的な詳細は次のように説明されます。 信頼性の高いエントロピー最小化
: エントロピーに基づいて、勾配選択のための代替判断指標が確立され、高エントロピー サンプル (図 6 (d) 領域 1 および 2 のサンプルを含む) はモデル適応から除外され、モデル更新には参加しません:

は指標関数を表し、 はサンプルのエントロピーを表します。予測結果、
はサンプルのエントロピーを表します。予測結果、 はスーパーパラメータを表します。
はスーパーパラメータを表します。  # の場合のみ、サンプルは逆伝播計算に参加します。
# の場合のみ、サンプルは逆伝播計算に参加します。 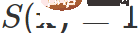
シャープネスに敏感なエントロピー最適化: 信頼性の高いサンプル選択メカニズムによってフィルタリングされたサンプルには、図 6 (d) 領域 4 のサンプルが含まれることを避けることができません。これらのサンプルはモデルに干渉し続けるノイズや大きな勾配が発生する可能性があります。この目的を達成するために、この記事では、ノイズ勾配によるモデルの更新の影響を受けないようにする、つまり元のモデルのパフォーマンスに影響を与えないように、モデルをフラットな最小値に最適化することを検討します。最適化の目標は次のとおりです:
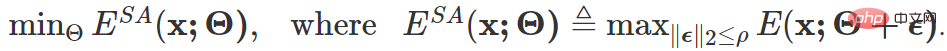 上記のターゲットの最終的なグラデーション更新フォームは次のとおりです:
上記のターゲットの最終的なグラデーション更新フォームは次のとおりです:
このうち 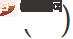 は SAM [4] からインスピレーションを受けており、一次テイラー展開による近似解によって得られます。この文書の原文とコードを参照してください。
は SAM [4] からインスピレーションを受けており、一次テイラー展開による近似解によって得られます。この文書の原文とコードを参照してください。
#現時点でのこの記事の全体的な最適化目標は次のとおりです:
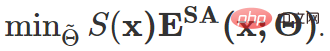
# #さらに、上記のスキームが極端な条件下でも失敗する可能性を防ぐために、モデル回復戦略がさらに導入されます。モデルが劣化または崩壊していないかをモバイル監視することで、モデルを復元することが決定されます。モデルの元の値は、必要な瞬間にパラメータを更新します。
実験評価動的オープン シナリオでのパフォーマンス比較
SAR は上記に基づいています3 つの動的なオープン シナリオ、すなわち、a) 混合分布シフト、b) 単一サンプル適応、および c) オンライン不均衡クラス分布シフトが、ImageNet-C データ セットで実験的に検証され、その結果が表 1、2、および表に示されています。 3. SAR は 3 つのシナリオすべてで、特にシナリオ b) と c) で顕著な結果を達成しており、SAR はベース モデルとして VitBase を使用しており、その精度は現在の SOTA メソッド EATA を 10% 近く上回っています。
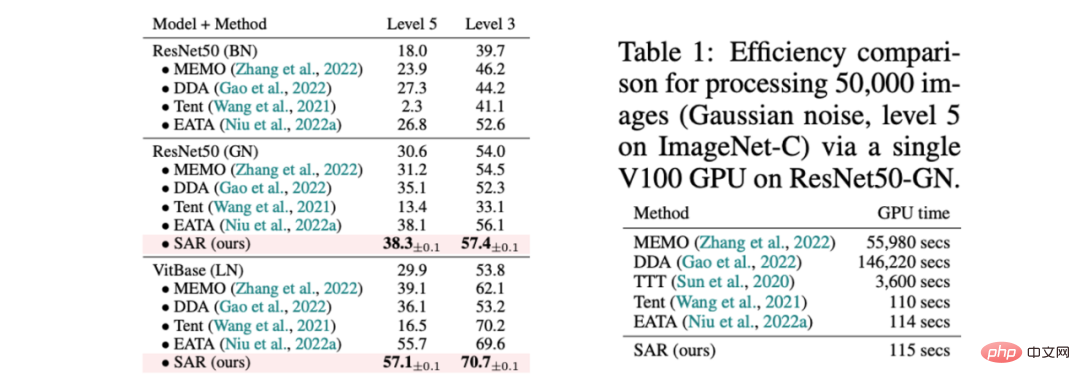
#表 1 ImageNet-C の 15 種類の破損に対する既存の手法と組み合わせた SAR のパフォーマンス比較動的シナリオ (a) に対応するシナリオ、および既存の方法との効率比較
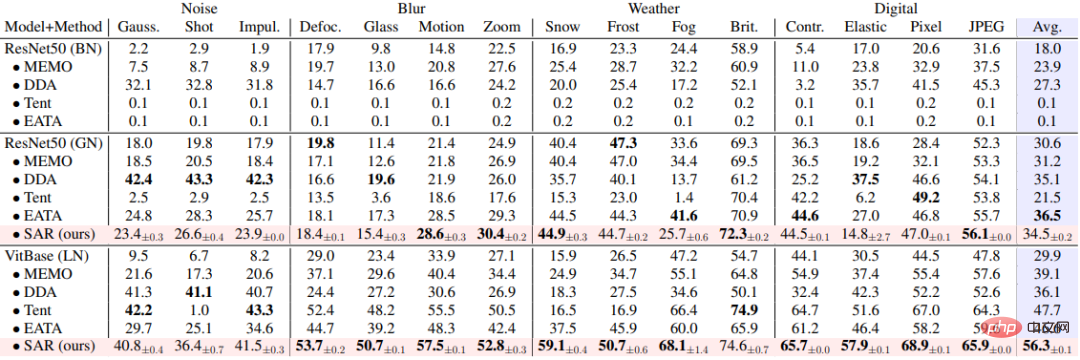
##表 2 動的シナリオに対応する、ImageNet-C 上の単一サンプル適応シナリオにおける SAR と既存の手法のパフォーマンス比較 (b)
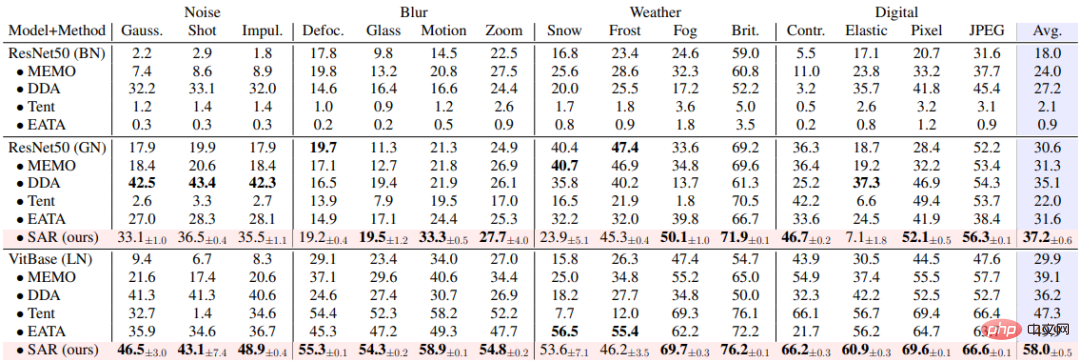
アブレーション実験
と勾配クリッピング法の比較
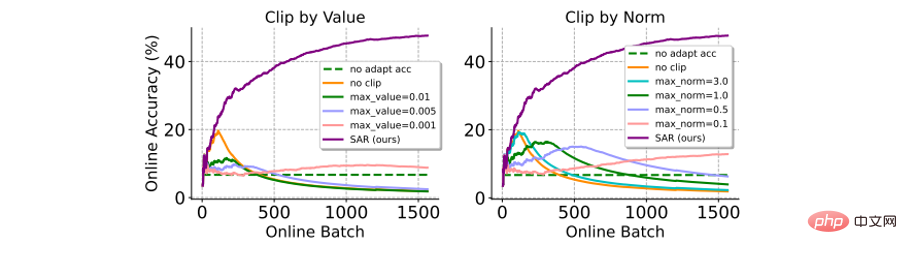
:グラデーション クリッピングは、大きなグラデーションがモデルの更新に影響を与える (または崩壊を引き起こす) ことを避けるための単純かつ直接的な方法です。ここでは、勾配クリッピングの 2 つの変形 (値による、またはノルムによる) との比較を示します。以下の図に示すように、勾配クリッピングは勾配クリッピングしきい値 δ の選択に非常に敏感であり、δ が小さいほどモデルが更新されていない結果と等しく、δ が大きいほどモデルの崩壊を避けることが困難になります。対照的に、SAR は複雑なハイパーパラメータ フィルタリング プロセスを必要とせず、勾配クリッピングよりも大幅に優れたパフォーマンスを発揮します。
アルゴリズムのパフォーマンスに対するさまざまなモジュールの影響: 以下の表に示すように、SAR のさまざまなモジュールの相乗効果により、動的オープン シナリオでのテスト中のモデルの適応安定性が効果的に向上します。

# 損失表面の鮮明さの可視化: モデルの重みに摂動を加えて損失関数を可視化した結果を次の図に示します。その中で、SAR は Tent よりも損失が最も低い等高線内に広い領域 (濃い青色の領域) を持ち、SAR によって得られるソリューションがより平坦で、ノイズ/より大きな勾配に対してより堅牢で、より強力な耐干渉能力を備えていることを示しています。 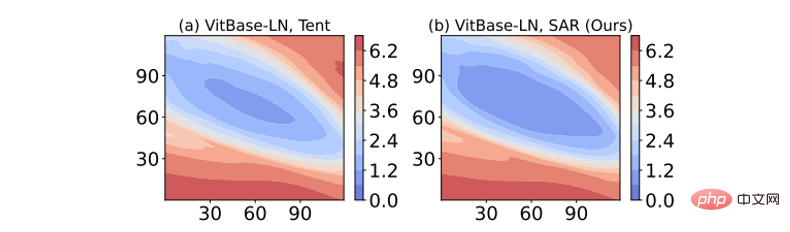
#図 8 エントロピー損失曲面の視覚化
結論この記事は、動的オープン シナリオでのモデルのオンライン テスト中の適応の不安定性の問題を解決することを目的としています。この目的のために、この記事ではまず、実際の動的シナリオにおいて既存の手法が失敗する理由を統一的な観点から分析し、詳細な検証を行うための完全な実験を設計します。これらの分析に基づいて、この論文は最終的に、シャープネスに敏感で信頼性の高いテスト時間エントロピー最小化方法を提案します。この方法は、モデル更新に対する大きな勾配/ノイズを持つ特定のテストサンプルの影響を抑制することにより、安定かつ効率的なモデルのオンラインテスト時間適応を実現します。 。
以上がBatch Norm レイヤーなどの欠点を解決するオープン環境ソリューションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



