



チャットボットまたはカスタマー サービス アシスタントは、インターネット上のテキストまたは音声を通じてユーザーに配信することでビジネス価値を達成することを目的とした AI ツールです。チャットボットの開発は、単純なロジックに基づいた初期のロボットから、自然言語理解 (NLU) に基づいた現在の人工知能に至るまで、ここ数年で急速に進歩しました。後者については、チャットボットを構築する際によく使われるフレームワークやライブラリとしては、海外のRASA、Dialogflow、Amazon Lexなどのほか、国内の大手企業であるBaidu、iFlytekなどが挙げられます。これらのフレームワークは、自然言語処理 (NLP) と NLU を統合して、入力テキストを処理し、意図を分類し、応答を生成するための適切なアクションをトリガーできます。
ラージ言語モデル (LLM) の出現により、これらのモデルを直接使用して、完全に機能するチャットボットを構築できるようになりました。有名な LLM の例の 1 つは、OpenAI の Generative Pre-trained Transformer 3 (GPT-3: chatgpt は gpt 微調整とヒューマン フィードバック モデルの追加に基づいています) です。これは、ダイアログまたはセッション データを使用してモデルを微調整でき、自然な会話のようなテキスト。この機能により、カスタム チャットボットの構築に最適です。
今日は、GPT-3 モデルを微調整して独自のシンプルな会話型チャットボットを構築する方法について説明します。
通常、顧客サービスの会話記録、チャット ログ、映画の字幕などのビジネス会話の例のデータセットに基づいてモデルを微調整する必要があります。微調整プロセスでは、この会話データによりよく適合するようにモデルのパラメーターが調整され、チャットボットがユーザー入力をよりよく理解して応答できるようになります。
GPT-3 を微調整するには、事前トレーニングされたモデルと微調整ツールを提供する Hugging Face の Transformers ライブラリを使用できます。このライブラリには、さまざまなサイズと機能のいくつかの GPT-3 モデルが用意されています。モデルが大きいほど、処理できるデータが多くなり、精度が高くなる可能性があります。ただし、今回は簡単のため、少量のコードを記述するだけで微調整が実現できる OpenAI インターフェースを使用します。
次のステップでは、OpenAI GPT-3 を使用して微調整を実装します。データ セットはここから入手できます。申し訳ありませんが、また外部データ セットを使用しました。このような処理されたデータは実際にはほとんどありません。中国のセットです。
アカウントの作成は非常に簡単で、このリンクを開くだけです。 openai キーを介して OpenAI 上のモデルにアクセスできます。 API キーを作成する手順は次のとおりです。
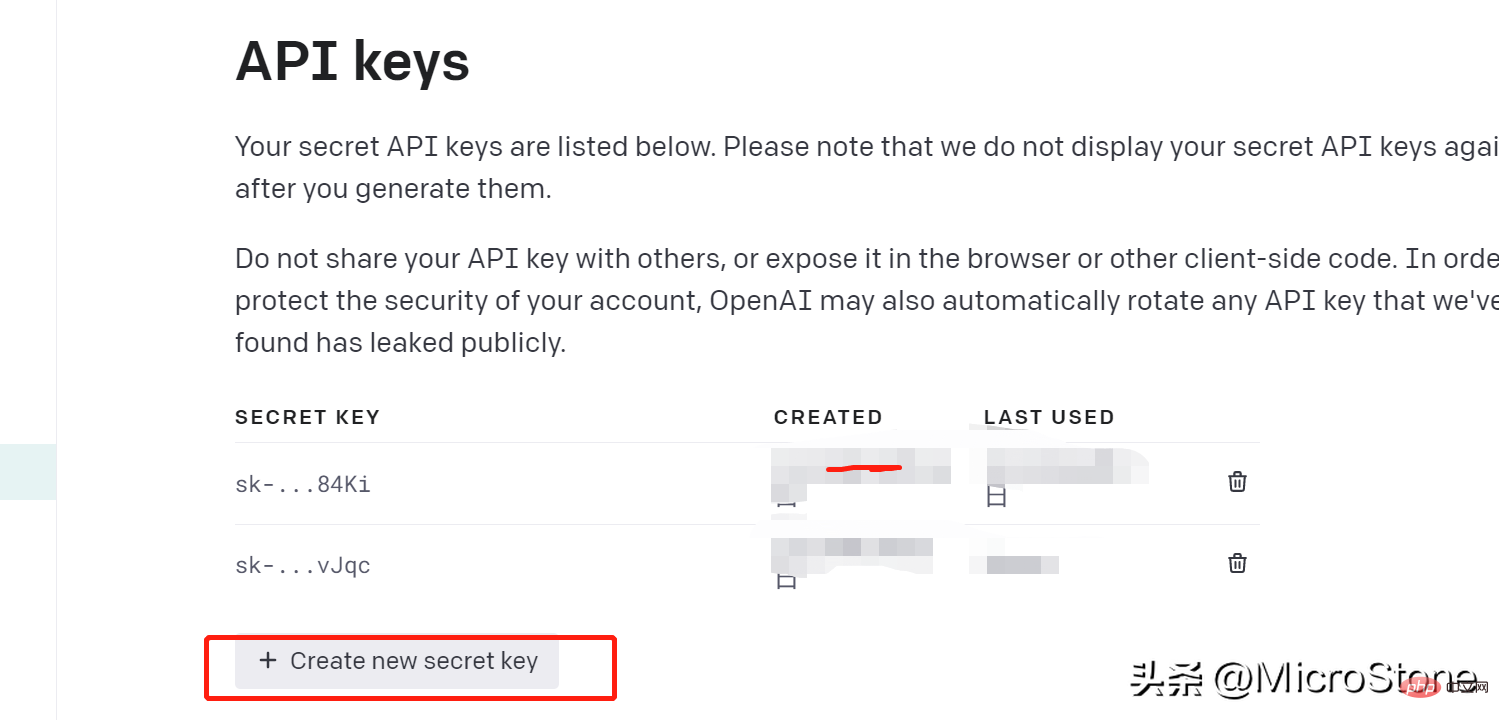
API キーを作成したので、微調整モデル用のデータの準備を開始できます。ここでデータセットを表示できます。

OpenAI ライブラリをインストールする pip install openai
インストール後、データをロードできます:
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))質問を Interview AI 列にロードし、対応する回答を Human 列にロードします。 OPENAI_API_KEYを保存するための環境変数 .env ファイルも作成する必要があります。
次に、データを GPT-3 標準に変換します。ドキュメントによると、データが 2 つのキーを持つ JSONL 形式であることを確認してください。これは重要です: プロンプト、例:complete
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }上記に適合するようにデータセットを再構築し、基本的にデータ フレーム内の各行をループして配置します。テキストを人間に割り当て、インタビュー AI テキストを完了に割り当てます。
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')prepare_data コマンドを使用します。プロンプトが表示されたらいくつかの質問が表示されます。Y または N で回答できます。
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")最後に、data_prepared.jsonl という名前のファイルがディレクトリにダンプされます。
モデルを楽しくチューニングするには、1 行のコマンドを実行するだけです:
os .system( "openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci " )
这基本上使用准备好的数据从 OpenAI 训练davinci模型,fine-tuning后的模型将存储在用户配置文件下,可以在模型下的右侧面板中找到。
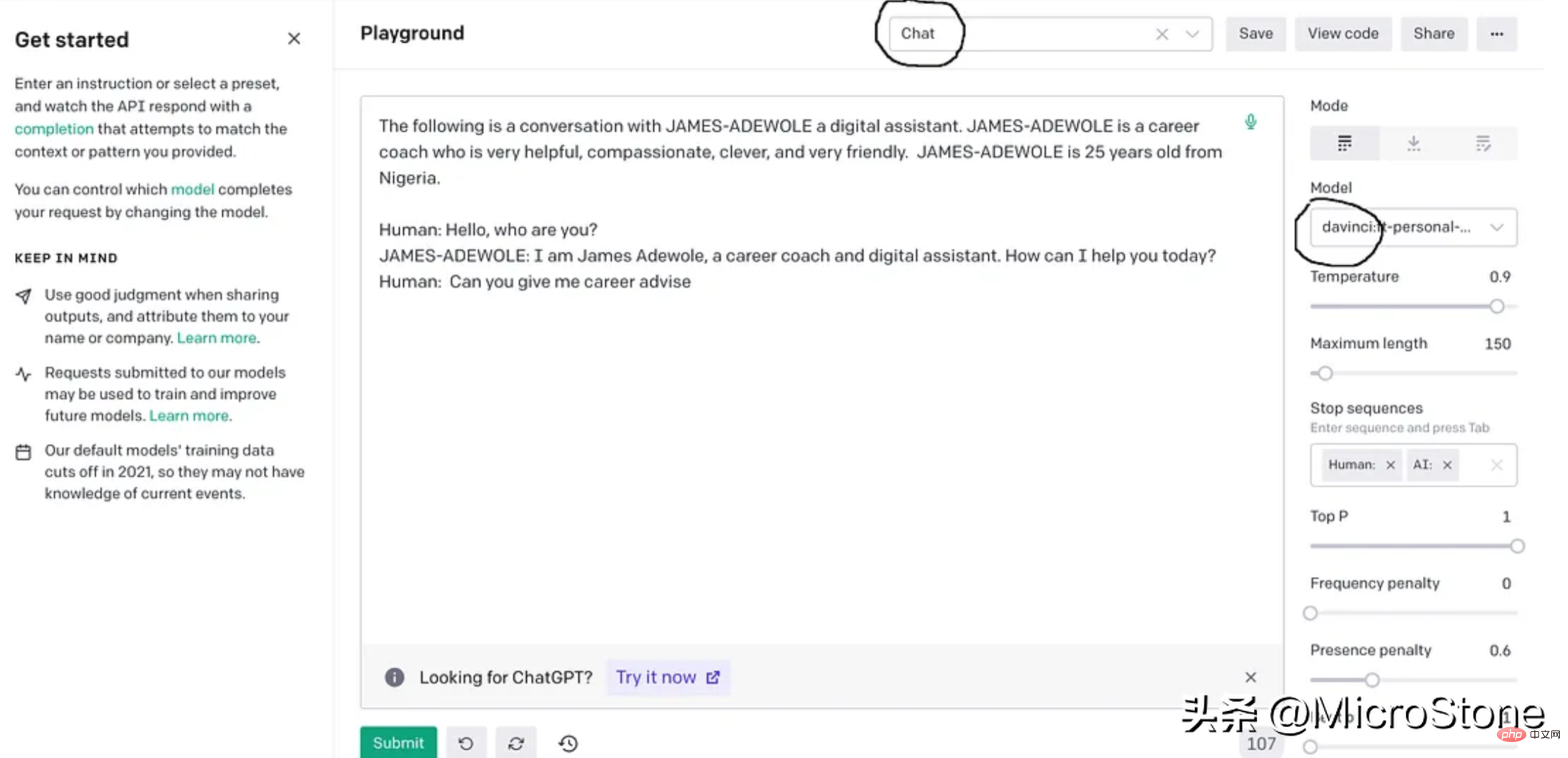
我们可以使用多种方法来验证我们的模型。可以直接从 Python 脚本、OpenAI Playground 来测试,或者使用 Flask 或 FastAPI 等框构建 Web 服务来测试。
我们先构建一个简单的函数来与此实验的模型进行交互。
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()
output = generate_response(input_text)
print(output)把它们放在一起。
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")
os.system("openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci ")
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()示例响应:
input_text = "what is breadth first search algorithm" output = generate_response(input_text)
The breadth-first search (BFS) is an algorithm for discovering all the reachable nodes from a starting point in a computer network graph or tree data structure
GPT-3 是一种强大的大型语言生成模型,最近火到无边无际的chatgpt就是基于GPT-3上fine-tuning的,我们也可以对GPT-3进行fine-tuning,以构建适合我们自己业务的聊天机器人。fun-tuning过程调整模型的参数可以更好地适应业务对话数据,让机器人更善于理解和响应业务的需求。经过fine-tuning的模型可以集成到聊天机器人平台中以处理用户交互,还可以为聊天机器人生成客服回复习惯与用户交互。整个实现可以在这里找到,数据集可以从这里下载。
以上がGPT-3 を使用してビジネス ニーズを満たすエンタープライズ チャットボットを構築するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



