


ChatGPT のリリース以来、この期間中、会話モデルの人気は高まるばかりです。これらのモデルの驚くべきパフォーマンスに感心する一方で、その背後にある巨大なコンピューティング能力と大規模なデータのサポートも推測する必要があります。
データに関する限り、高品質のデータは非常に重要です。このため、OpenAI はデータとアノテーションの作業に多大な労力を費やしてきました。 ChatGPT は人間よりも信頼性の高いデータ アノテーターであることが複数の研究で示されており、オープンソース コミュニティが ChatGPT などの強力な言語モデルから大量の対話データを取得できれば、対話モデルをより優れたパフォーマンスでトレーニングできるようになります。これは、アルパカ、ビキューナ、コアラなどのアルパカ ファミリーのモデルによって証明されています。たとえば、Vicuna は、ShareGPT から収集したユーザー共有データを使用して LLaMA モデルの命令を微調整することで、ChatGPT の 9 段階の成功を再現しました。 データが強力な言語モデルをトレーニングするための主要な生産性であることを示す証拠が増えています。
ShareGPT は、ユーザーが興味深いと思う ChatGPT の回答をアップロードする ChatGPT データ共有 Web サイトです。 ShareGPT 上のデータはオープンですが些細なものであり、研究者自身が収集して整理する必要があります。高品質で幅広いデータセットがあれば、オープンソース コミュニティは会話モデルの開発に半分の労力で 2 倍の結果を得ることができます。
これに基づいて、UltraChat と呼ばれる最近のプロジェクトにより、超高品質の会話データ セットが体系的に構築されました。プロジェクトの作成者は、2 つの独立した ChatGPT Turbo API を使用して会話を実行し、複数ラウンドの会話データを生成しようとしました。
具体的には、このプロジェクトの目的は、 Turbo API に基づくオープンソースの大規模なマルチラウンド対話データにより、研究者が普遍的な対話機能を備えた強力な言語モデルを開発できるようになります。なお、本プロジェクトではプライバシー保護等を考慮し、インターネット上のデータをプロンプトとして直接利用することはありません。生成されたデータの品質を保証するために、研究者らは生成プロセスで 2 つの独立した ChatGPT Turbo API を使用しました。1 つのモデルは質問や指示を生成するユーザーの役割を果たし、もう 1 つのモデルはフィードバックを生成します。

ChatGPT を直接使用して、いくつかのシード会話や質問に基づいて自由に生成すると、単一のトピックやコンテンツの繰り返しなどの問題が発生しやすくなります。データの多様性そのものを保証することが困難になります。この目的を達成するために、UltraChat は会話データの対象となるトピックとタスクのタイプを体系的に分類して設計し、次の 3 つの部分で構成されるユーザー モデルと応答モデルの詳細なプロンプト エンジニアリングも実施しました。 世界についての質問: 会話のこの部分は、現実世界の概念、エンティティ、オブジェクトに関する幅広い質問から生まれています。取り上げられるトピックは、テクノロジー、アート、金融、その他の分野に及びます。
たとえば、データの最初の部分の主な課題は、合計数十万の会話の中で人間社会の共通知識をできるだけ広範囲にカバーする方法です。この目的のために、研究者らは自動的にウィキデータから生成されたトピックとソース エンティティの 2 つの側面がフィルタリングされ、構築されます。
第 2 部と第 3 部の課題は主に、最終的な目標から逸脱することなく、ユーザーの指示をシミュレートし、後続の会話でユーザー モデルの生成をできるだけ多様にする方法にあります。会話 (必要に応じてマテリアルを生成するか、マテリアルを書き換えます)。これについて研究者は、ユーザー モデルの入力プロンプトを完全に設計し、実験しました。構築が完了した後、著者らは幻覚の問題を弱めるためにデータを後処理しました。
現在、プロジェクトはデータの最初の 2 つの部分をリリースしており、そのデータ量は 124 万件で、これはオープンソース コミュニティで最大の関連データ セットとなるはずです。コンテンツには現実世界での豊かで多彩な会話が含まれており、データの最終部分は今後公開される予定です。
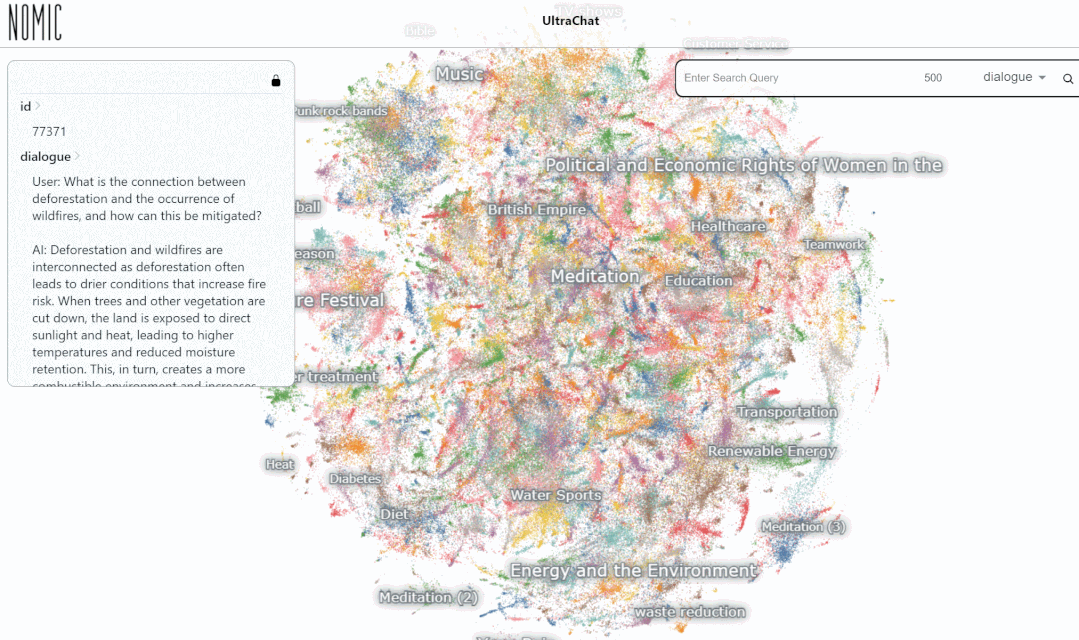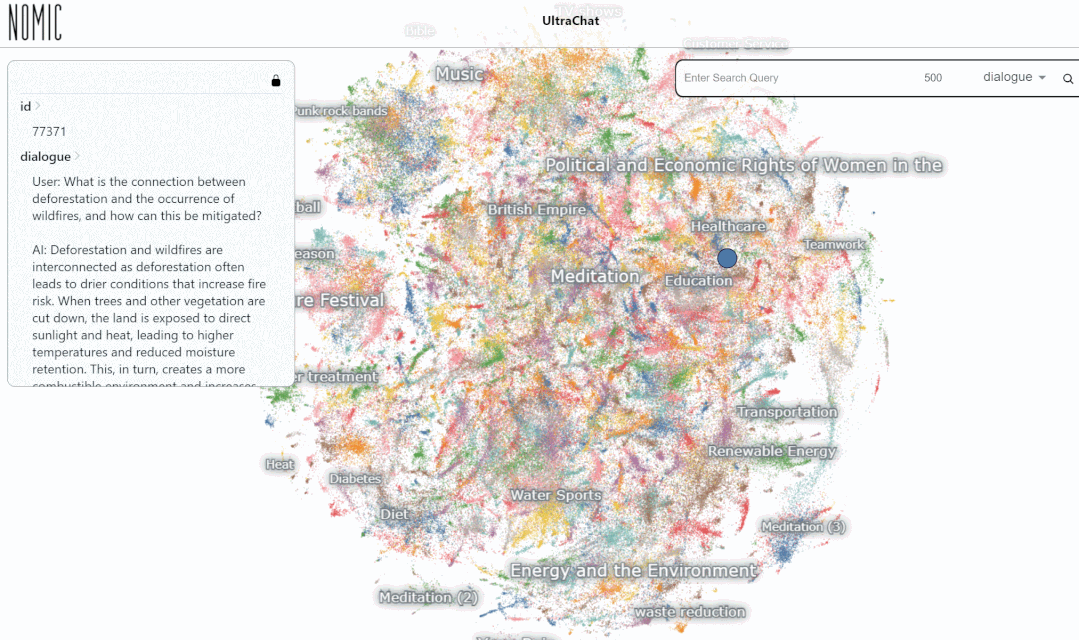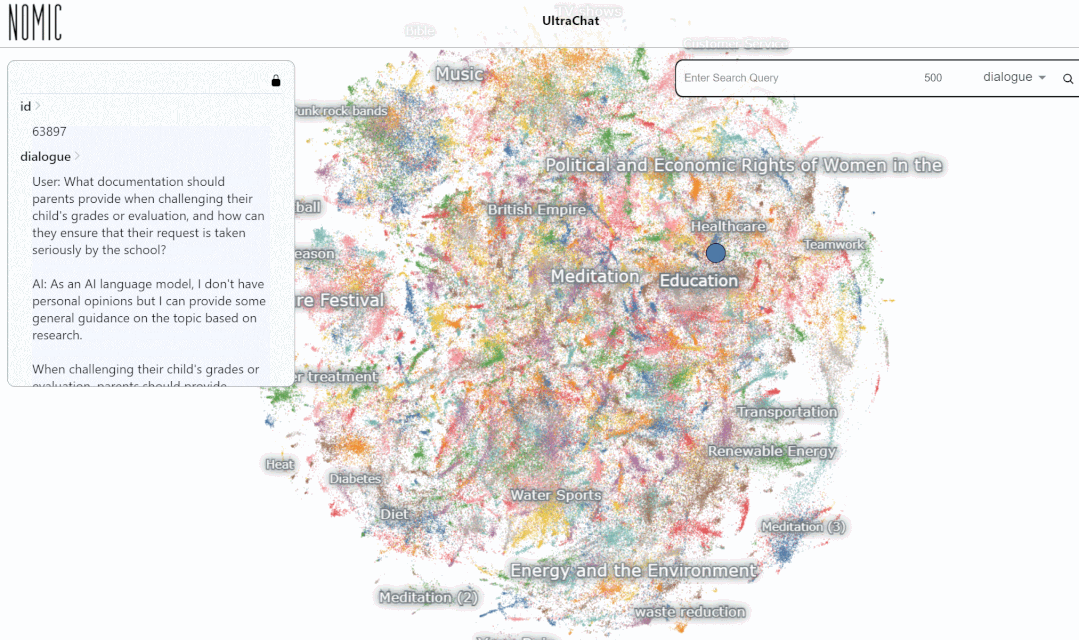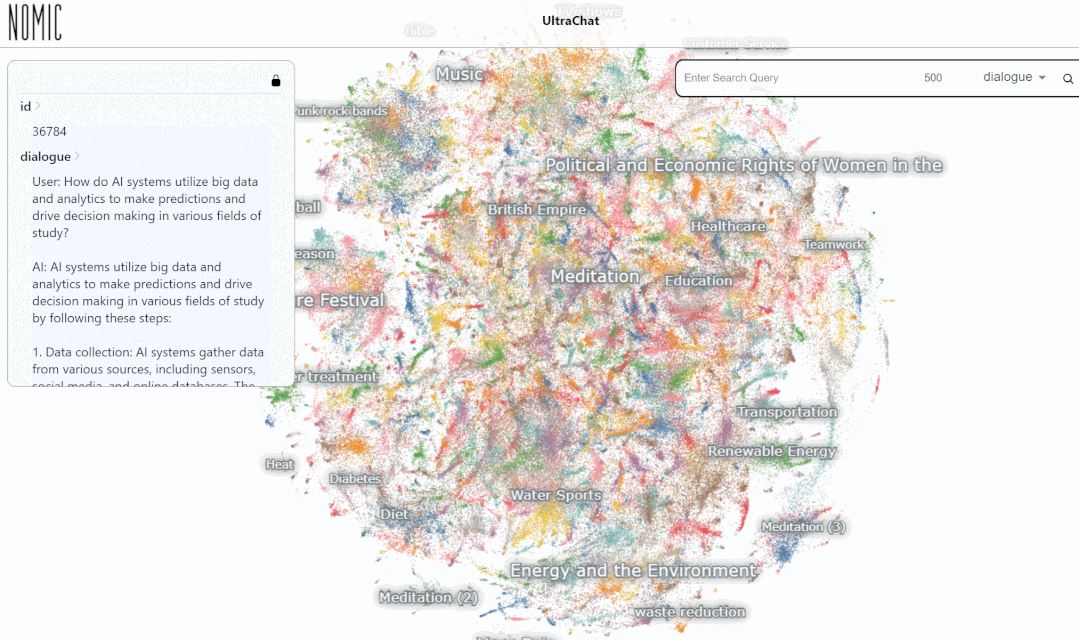
#世界の問題データは、以下の図に示すように、30 の代表的で多様なメタテーマから得られます。

次に、具体的な例を見てみましょう:
UltraChat プラットフォームでデータをテストしました。結果。たとえば、「音楽」と入力すると、システムは音楽関連の ChatGPT 会話データ 10,000 セットを自動的に検索します。各セットは複数ラウンドの会話です。
キーワード「数学(数学)」を入力して検索した結果、複数ラウンドの会話が 3346 件あります: 
# #現在、UltraChat は医療、教育、スポーツ、環境保護などの情報分野をすでにカバーしています。同時に、著者はオープンソース LLaMa-7B モデルを使用して UltraChat 上で教師あり命令の微調整を実行しようとしましたが、わずか 10,000 ステップのトレーニング後に非常に印象的な効果があることがわかりました。いくつかの例は次のとおりです。

##世界の知識: 中国とアメリカの優れた大学をそれぞれ 10 校挙げてください

想像力の質問: 宇宙旅行が可能になった後に考えられる結果は何ですか? 
三段論法: クジラは魚ですか? ##仮定の質問: ジャッキー チェンがブルース リーよりも優れていることを証明してください 全体として、UltraChat は高品質で広範囲にわたる ChatGPT 会話データ セットであり、他のデータ セットと組み合わせてオープンソース会話モデルの品質を大幅に向上させることができます。現在、UltraChat は英語版のみを公開していますが、将来的には中国語版のデータも公開する予定です。興味のある読者はぜひ調べてみてください。 
以上が複数の ChatGPT API を使用した Tsinghua UltraChat マルチラウンド会話の実装の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



