


Apache Kafka は、分散型パブリッシュ/サブスクライブ メッセージング システムです。kafka 公式 Web サイトでの kafka の定義は、「分散型パブリッシュ/サブスクライブ メッセージング システム」です。これは元々 LinkedIn によって開発され、2010 年に Apache Foundation に寄付され、トップのオープンソース プロジェクトになりました。 Kafka は、高速かつスケーラブルで、本質的に分散され、パーティション化され、複製可能なコミット ログ サービスです。
注: Kafka は JMS 仕様 () に従っておらず、パブリッシュおよびサブスクライブ通信メソッドのみを提供します。
ブローカー: Kafka ノード、Kafka ノードはブローカーであり、複数のブローカーで Kafka クラスターを形成できます
#kafka クラスターのインストール
Zookeeper クラスター環境のインストール
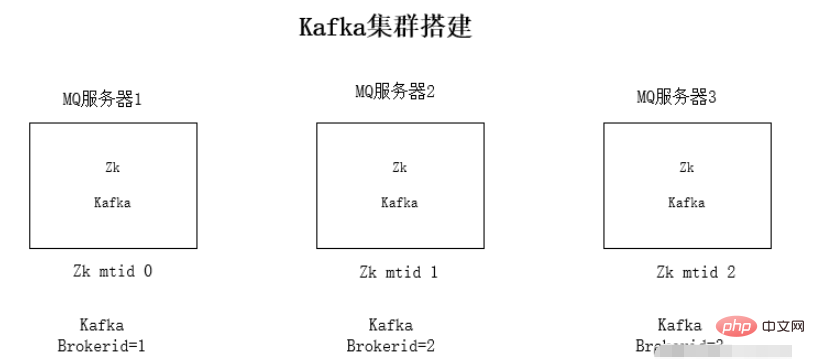 kafka クラスターのインストール手順:
kafka クラスターのインストール手順:
1. Kafka 圧縮パッケージをダウンロードします
2. インストール パッケージ
tar -zxvf kafka_2 を解凍します。 11 -1.0.0.tgz3. kafka の設定ファイルを変更 config/server.properties
設定ファイルの変更内容:
Zookeeper 接続アドレス:
zookeeper.connect=192.168.1.19:2181リスニング IP がローカル iplisteners=PLAINTEXT:// 192.168 に変更されます。 .1.19:9092
#kafka のブローカー ID、各ブローカーの ID は異なりますbroker.id=0
4. Kafka を順番に開始します
kafka の使用法
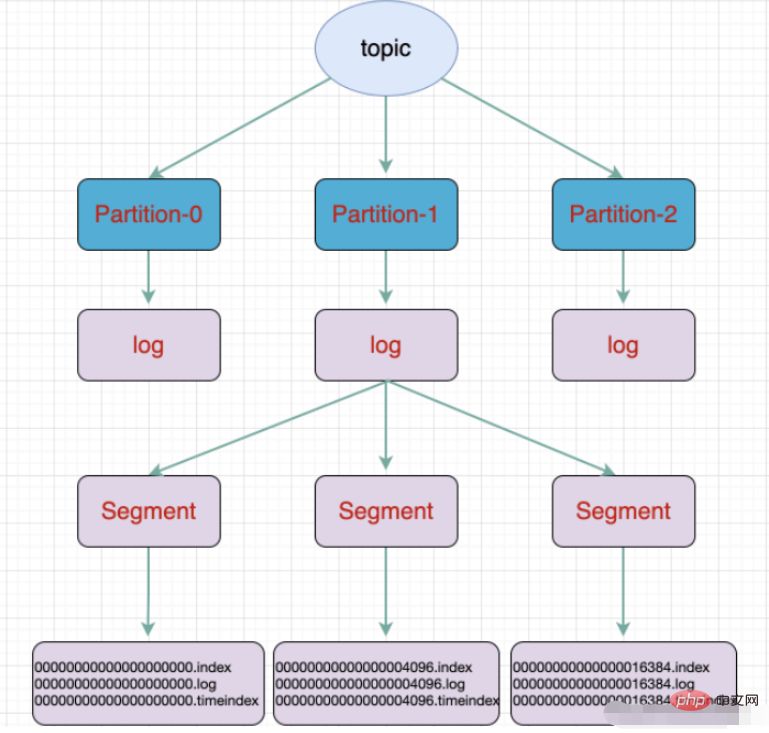
kafkaファイル ストレージトピックは論理概念、パーティションは物理概念です。各パーティションはログ ファイルに対応し、ログ ファイルにはプロデューサーによって生成されたデータが保存されます。プロデューサーによって生成されたデータは、ログ ファイルの末尾に継続的に追加されます。ログ ファイルが大きくなりすぎてデータ配置の非効率が引き起こされるのを防ぐために、Kafka はシャーディングおよびインデックス作成メカニズムを採用して各パーティションを複数のセグメントに分割します。各セグメントには、「.index」ファイル、「.log」ファイル、および .timeindex ファイルが含まれます。これらのファイルはフォルダー内にあり、フォルダーの命名規則は次のとおりです: トピック名 パーティション シリアル番号。
 #a パーティション 複数のセグメントに分割
#a パーティション 複数のセグメントに分割
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies># kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094@RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}@Component
public class TopicKaicoConsumer {
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topics = "kaico") //监听的主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
//输出key对应的value的值
System.out.println(consumer.value());
}
}以上がJava 分散 Kafka メッセージ キュー インスタンスの分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



