


ニューラル ネットワークは、その複雑さのため、すべての機械学習の問題を解決するための「聖杯」とみなされることがよくあります。一方、ツリーベースの手法は、主にそのようなアルゴリズムの見かけの単純さのため、同様の注目を集めていません。ただし、これら 2 つのアルゴリズムは異なるように見えるかもしれませんが、同じコインの裏表のようなもので、どちらも重要です。

ツリーベースの手法は、通常、ニューラル ネットワークよりも優れています。基本的に、ツリーベースの手法とニューラル ネットワーク ベースの手法は、どちらもサポート ベクター マシンやロジスティック回帰のような複雑な境界を介してデータセット全体を分割するのではなく、段階的な分解を通じて問題にアプローチするため、同じカテゴリに分類されます。 。
明らかに、ツリーベースの方法では、さまざまな特徴に沿って特徴空間を段階的にセグメント化し、情報取得を最適化します。あまり明らかではありませんが、ニューラル ネットワークも同様の方法でタスクにアプローチします。各ニューロンは、特徴空間の特定の部分 (複数のオーバーラップを含む) を監視します。入力がこの空間に入ると、特定のニューロンが活性化されます。
ニューラル ネットワークでは、このモデルのフィッティングを確率論的な観点から見るのに対し、ツリーベースの手法では決定論的な観点がとられます。いずれにしても、両方のコンポーネントは特徴空間のさまざまな部分に関連付けられているため、両方のパフォーマンスはモデルの深さに依存します。
コンポーネント (ツリー モデルの場合はノード、ニューラル ネットワークの場合はニューロン) が多すぎるモデルは過剰適合しますが、コンポーネントが少なすぎるモデルでは意味のある予測が得られません。 (どちらも、一般化を学習するのではなく、データ ポイントを記憶することから始まります。)
ニューラル ネットワークが特徴空間をどのように分割するかをより直観的に理解したい場合は、この紹介記事を読むことができます。普遍近似定理について: https://medium.com/analytics-vidhya/you-dont-question-neural-networks-until-you-under-the-universal-estimated- Theory-85b3e7677126。
ランダム フォレスト、勾配ブースティング、AdaBoost、ディープ フォレストなど、デシジョン ツリーには強力なバリエーションが多数ありますが、一般に、ツリーベースの手法は本質的にニューラル ネットワークのバージョンを簡略化したものです。 。
ツリーベースの手法は、垂直線と水平線を通じて問題を部分的に解決し、エントロピー (オプティマイザーと損失) を最小限に抑えます。ニューラル ネットワークは活性化関数を使用して問題を少しずつ解決します。
ツリーベースの方法は、確率論的ではなく決定論的です。これにより、自動機能選択などの優れた簡素化が実現します。
デシジョン ツリー内のアクティブ化された条件ノードは、ニューラル ネットワーク内のアクティブ化されたニューロン (情報フロー) に似ています。
ニューラル ネットワークは、パラメータのフィッティングを通じて入力を変換し、後続のニューロンの活性化を間接的にガイドします。デシジョン ツリーは、情報の流れをガイドするパラメーターを明示的に適合させます。 (これは、決定論と確率論の結果です。)
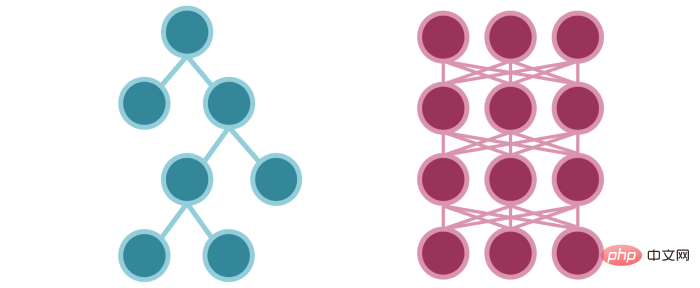
2 つのモデルの情報の流れは、ツリー モデル内だけで似ています。方法はより簡単です。
もちろん、これは抽象的な結論であり、次のような結果になる可能性があります。物議を醸す可能性さえあります。確かに、この接続を確立するには多くの障害があります。いずれにせよ、これは、いつ、そしてなぜツリーベースの手法がニューラル ネットワークよりも優れているのかを理解する上で重要な部分です。
デシジョン ツリーの場合、表形式または表形式の構造化データを操作するのは自然なことです。ニューラル ネットワークを使用して表形式のデータに対して回帰と予測を実行するのはやりすぎであることにほとんどの人が同意するため、ここではいくつかの簡略化が行われます。 2 つのアルゴリズムの違いの主な原因は、確率ではなく 1 と 0 の選択です。したがって、ツリーベースの手法は、構造化データなど、確率が必要ない状況にもうまく適用できます。
たとえば、各数値にはいくつかの基本的な特徴があるため、ツリーベースのメソッドは MNIST データセットで良好なパフォーマンスを示します。確率を計算する必要がなく、問題はそれほど複雑ではありません。そのため、適切に設計されたツリー アンサンブル モデルは、最新の畳み込みニューラル ネットワークと同等かそれ以上のパフォーマンスを発揮できます。
一般に、「ツリーベースのメソッドはルールを覚えているだけ」と言われがちですが、それは正しいです。ニューラル ネットワークは、より複雑な確率ベースのルールを記憶できる点を除いて同じです。 x>3 のような条件に対して真/偽予測を明示的に与えるのではなく、ニューラル ネットワークは入力を非常に高い値に増幅し、シグモイド値 1 を生成するか、連続式を生成します。
一方、ニューラル ネットワークは非常に複雑なので、それを使ってできることはたくさんあります。畳み込み層と再帰層はどちらも、処理されるデータに確率計算の微妙なニュアンスが必要になることが多いため、ニューラル ネットワークの優れた変種です。
1 と 0 でモデル化できる画像はほとんどありません。デシジョン ツリー値は、多くの中間値 (例: 0.5) を持つデータセットを処理できないため、ピクセル値がほぼすべて黒または白であるが、他のデータセットのピクセル値はそうではない MNIST データセットでは良好にパフォーマンスします (例: ImageNet) 。同様に、テキストには決定的な用語で表現するには情報が多すぎ、異常が多すぎます。
これが、ニューラル ネットワークがこれらの分野で主に使用される理由であり、大量の画像とテキストが存在した初期の時期 (21 世紀初頭以前) にニューラル ネットワークの研究が停滞した理由です。データが入手できませんでした。ニューラル ネットワークの他の一般的な用途は、非常に大規模で確率を使用する必要がある YouTube 動画推奨アルゴリズムなどの大規模な予測に限定されます。
Zoom ビデオの背景をぼかすなどの高負荷なアプリケーションを構築している場合を除き、どの企業のデータ サイエンス チームもおそらくニューラル ネットワークではなくツリーベースのモデルを使用するでしょう。しかし、日常的なビジネス分類タスクでは、ツリーベースの手法は決定論的な性質によりこれらのタスクを軽量にし、その手法はニューラル ネットワークと同じです。
実際の多くの状況では、確率的モデリングよりも決定的モデリングの方が自然です。たとえば、ユーザーが電子商取引 Web サイトから商品を購入するかどうかを予測するには、ユーザーはルールに基づいた意思決定プロセスに自然に従うため、ツリー モデルが適しています。ユーザーの意思決定プロセスは次のようになります:
一般的に、人間はルールに基づいた構造化された意思決定プロセスに従います。このような場合、確率モデリングは不要です。
以上が機械学習: ツリー モデルの力を過小評価しないでくださいの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



