最近、私は CCF コンピュータ ビジョン委員会の非公開セミナーや VALSE オフライン カンファレンスなど、いくつかの集中度の高い学術活動に参加しました。他の学者とコミュニケーションを取った後、多くのアイデアを思いついたので、私自身や同僚の参考のためにそれらを整理したいと思います。もちろん、個人のレベルや研究範囲に制限があるため、論文には間違いなく多くの不正確さ、あるいは間違いさえあるでしょうし、もちろん、研究の重要な方向性をすべて網羅することは不可能です。これらの視点を具体化し、将来の方向性をより良く探るために、興味のある学者とコミュニケーションをとることを楽しみにしています。
この記事では、コンピューター ビジョンの分野、特に視覚認識 (つまり、認識) の分野における困難さと研究の可能性を分析することに焦点を当てます。 ) 方向。私は、特定のアルゴリズムの詳細を改善するのではなく、現在のアルゴリズム (特に深層学習に基づく事前トレーニング微調整パラダイム) の制限とボトルネックを調査し、そこからどの問題が重要であるかを含め、開発に関する暫定的な結論を導き出したいと考えています。 、どの問題は重要ではないのか、どの方向が進歩する価値があるのか、どの方向は費用対効果が低いのか、などです。
#始める前に、まず次のマインド マップを描きます。適切な入り口点を見つけるために、コンピューター ビジョンと自然言語処理 (人工知能における 2 つの最も人気のある研究方向) の違いから始めて、画像信号の 3 つの基本的な特性、情報の希薄性、ドメイン間の多様性を紹介します。 、無限の粒度で、それらをいくつかの重要な研究方向に対応させます。このようにして、各研究方向の状況、つまりどのような問題が解決され、どのような重要な問題がまだ解決されていないのかをよりよく理解し、将来の開発傾向を的を絞った方法で分析することができます。
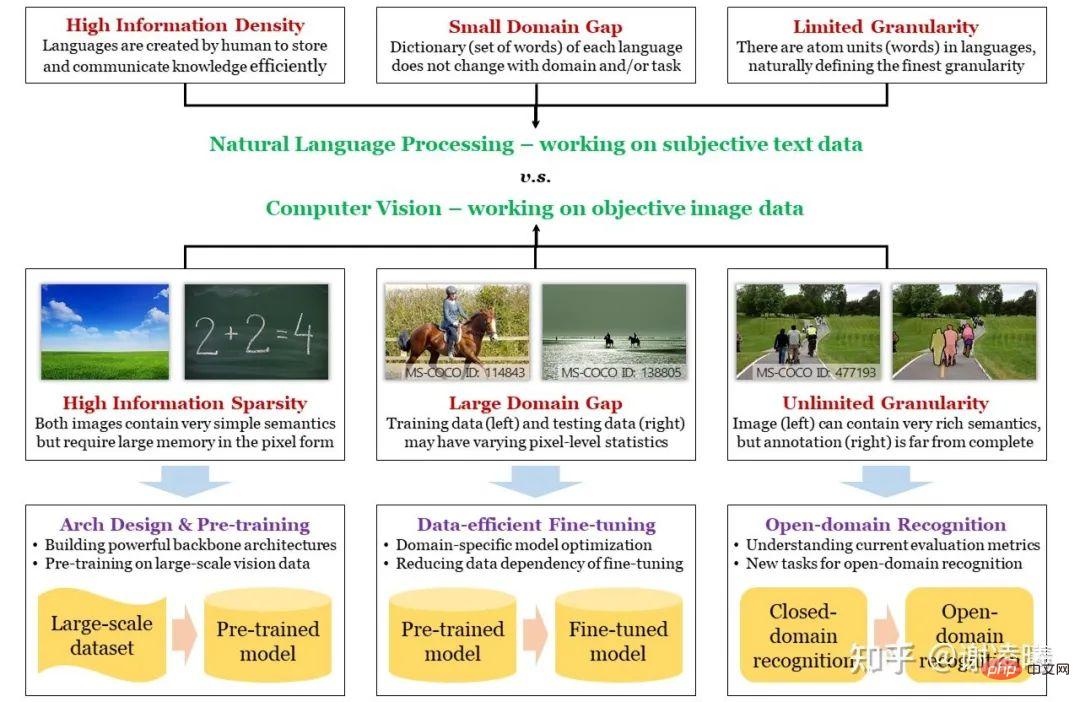
# マップ: CV と NLP の違い、CV の 3 つの主要な課題とその対処方法
CV の 3 つの基本的な困難とそれに対応する研究の方向性
NLP は常に CV の先を行ってきました。ディープ ニューラル ネットワークが手動手法を超えるか、事前トレーニングされた大規模モデルが統合の傾向を示し始めるかにかかわらず、これらのことは最初に NLP 分野で起こり、すぐに CV 分野に移りました。ここでの本質的な理由は、NLP の出発点がより高いということです。自然言語の基本単位は単語であるのに対し、画像の基本単位はピクセルです。前者は自然な意味情報を持っていますが、後者は意味を表現できない可能性があります。基本的に、自然言語は人間が知識を蓄積し、情報を伝達するために作成した媒体であるため、高効率かつ高情報密度の特性を持たなければなりませんが、画像は人間がさまざまなセンサーを通じて捉えた光信号であり、客観的に反映することができます。実際の状況はよく再現されていますが、そのため強力なセマンティクスを持たず、情報密度が非常に低い可能性があります。別の観点から見ると、画像空間はテキスト空間よりもはるかに大きく、空間の構造もはるかに複雑です。つまり、空間内で多数のサンプルをサンプリングし、これらのデータを使用して空間全体の分布を特徴付ける場合、サンプリングされた画像データは、サンプリングされたテキスト データよりも桁違いに大きくなります。ちなみに、これは自然言語事前トレーニング モデルが視覚事前トレーニング モデルよりも優れている本質的な理由でもあります。これについては後で説明します。
#上記の分析によれば、CV と NLP の違いを通じて、CV の最初の基本的な難しさであるセマンティック スパース性が明らかになりました。他の 2 つの問題、ドメイン間の違いと無限の粒度は、前述の本質的な違いに多少関連しています。画像をサンプリングするときにセマンティクスが考慮されていないため、異なるドメイン (つまり、昼と夜、晴れと雨の日などの異なる分布) をサンプリングすると、サンプリング結果 (つまり、画像ピクセル) が大きく影響を受けます。ドメインの特性と相関関係があり、結果としてドメイン間の差異が生じます。同時に、画像の基本的な意味単位を定義するのは難しく(テキストは定義するのが簡単ですが)、画像によって表現される情報は豊富で多様であるため、人間は画像からほぼ無限に細かい意味情報を取得できます。現在の CV フィールドをはるかに超えており、この評価指標によって定義される機能は無限の粒度です。無限の粒度については、私はかつてこの問題について特に論じた記事を書きました。 https://zhuanlan.zhihu.com/p/376145664
# # 上記の 3 つの基本的な問題をガイドとして考慮し、近年の業界の研究の方向性を次のように要約します。
-
セマンティック スパース性: 解決策は、効率的なコンピューティング モデル (ニューラル ネットワーク) と視覚的な事前トレーニングを構築することです。ここでの主なロジックは、データの情報密度を高めたい場合は、データの不均一な分布 (情報理論) を仮定してモデル化する必要がある (つまり、データの事前分布を学習する) 必要があるということです。現在、最も効率的なモデリング方法は 2 種類あり、1 つはニューラル ネットワーク アーキテクチャ設計を使用して、データに依存しない事前分布を取得する方法です (たとえば、畳み込みモジュールは画像データの局所的な事前分布に対応し、変換モジュールは画像データの局所的な事前分布に対応します)。 1 つは、大規模データの事前トレーニングを通じてデータ関連の事前分布を取得することです。これら 2 つの研究方向は、視覚認識の分野において最も基本的であり、最も関係のあるものでもあります。
-
ドメイン間の違い: 解決策は、データ効率の高い微調整アルゴリズムです。上記の分析によれば、ネットワークのサイズが大きくなり、事前トレーニング データセットが大きくなるほど、計算モデルに格納される事前強度が強くなります。ただし、トレーニング前ドメインとターゲット ドメインの間のデータ分布に大きな差がある場合、この強い事前分布は不利な点をもたらします。情報理論によれば、特定の部分 (トレーニング前ドメイン) の情報密度を高めると、他の部分(事前学習領域に含まれない部分、つまり、事前学習プロセス中に重要ではないと考えられる部分)の情報密度を確実に削減します。実際には、ターゲット ドメインは部分的または全体的に関与していない部分に含まれる可能性が高く、その結果、事前トレーニングされたモデルの直接転送が不十分になります (つまり、過剰適合)。このとき、ターゲットドメインでの微調整により、新しいデータ分布に適応する必要があります。ターゲット ドメインのデータ量がトレーニング前のドメインのデータ量よりもはるかに小さい場合が多いことを考慮すると、データ効率は必須の前提条件となります。さらに、実用的な観点から見ると、モデルはドメインの変化に適応できなければならないため、生涯学習が必須となります。
-
無制限の粒度: ソリューションは、オープン ドメイン認識アルゴリズムです。無限の粒度にはオープン ドメイン機能が含まれており、より高い追求目標となります。特に業界では一般に受け入れられているオープンドメイン認識データセットや評価指標が存在しないため、この方向の研究はまだ予備段階です。ここで最も重要な問題の 1 つは、視覚認識にオープン ドメイン機能を導入する方法です。良いニュースは、クロスモーダルな事前トレーニング方法 (特に 2021 年の CLIP) の出現により、自然言語がオープン ドメイン認識の推進力にますます近づいていることです。これが次の主流の方向になると信じています。 2~3年。しかし、私は、オープンドメイン認識の追求の中で登場したさまざまなゼロショット認識タスクには同意しません。私はゼロショット自体が誤った命題だと思っており、ゼロショットの識別方法は世の中に存在しませんし、その必要もありません。既存のゼロショット タスクはすべて、アルゴリズムに情報を漏洩するために異なる方法を使用しており、漏洩方法は多岐にわたるため、異なる方法間で公平に比較することが困難です。この方向で、視覚認識の無限の粒度をさらに明らかにし、探索するために、オンデマンド視覚認識と呼ばれる方法を提案します。
#ここでは追加の説明が必要です。データ空間のサイズと構造の複雑さの違いにより、少なくとも今のところ、CV 分野では事前トレーニング済みモデルを通じてドメイン間の差異の問題を直接解決することはできませんが、NLP 分野はこの点に近づいています。したがって、NLP 学者がプロンプトベースの手法を使用して数十、数百の下流タスクを統合しているのを私たちは見てきましたが、CV 分野では同じことは起こりませんでした。さらに、NLP で提案されているスケーリング則の本質は、より大きなモデルを使用して事前トレーニング データセットをオーバーフィットすることです。言い換えれば、NLP の場合、小さなプロンプトと組み合わせた事前トレーニング データセットで意味空間全体の分布を表すのに十分であるため、過学習はもはや問題になりません。ただし、CV 分野ではこれが達成されていないため、ドメイン移行も考慮する必要があり、ドメイン移行の核心はオーバーフィットを避けることです。つまり、今後 2 ~ 3 年で、CV と NLP の研究の焦点は大きく異なるため、ある方向の思考モードを別の方向にコピーすることは非常に危険です。 #以下は、各研究の方向性の簡単な分析です
##方向 1a: ニューラル ネットワーク アーキテクチャの設計## AlexNet は 2012 年に、CV の分野でディープ ニューラル ネットワークの基礎を築きました。その後 10 年間 (現在まで)、ニューラル ネットワーク アーキテクチャの設計は、手動設計から自動設計、そして手動設計 (より複雑なコンピューティング モジュールの導入) に戻るというプロセスを経てきました。
- 2012 年から 2017 年にかけて、より深い畳み込みニューラル ネットワークを手動で構築し、一般的な最適化手法を調査しました。キーワード: ReLU、ドロップアウト、3x3畳み込み、BN、スキップ接続などこの段階では、畳み込み演算が最も基本的な単位であり、画像特徴の局所性事前分布に相当します。
- 2017-2020 では、より複雑なニューラル ネットワークが自動的に構築されます。中でも、Network Architecture Search (NAS) は一時期流行し、ようやく基本的なツールとして定着しました。どのような検索空間においても、自動設計によりわずかに優れた結果が得られ、さまざまな計算コストに迅速に適応できます。
- 2020 年以降、NLP から生まれたトランス モジュールが CV に導入され、アテンション メカニズムを使用して、CV の長距離モデリング機能を補完しています。ニューラルネットワーク。現在、トランスフォーマーを含むアーキテクチャの助けを借りて、ほとんどの視覚的なタスクで最適な結果が得られます。
#この方向の将来について、私の判断は次のとおりです。
- 視覚認識タスクが大幅に変わらない場合、自動設計も、より複雑なコンピューティング モジュールの追加も、CV を新たな高みに押し上げることはできません。視覚認識タスクで起こり得る変化は、入力と出力の 2 つの部分に大別できます。イベント カメラなどの入力部分で起こり得る変化は、静的または逐次的な視覚信号の通常の処理の現状を変え、特定のニューラル ネットワーク構造を引き起こす可能性があります。出力部分で起こり得る変化は、ある種のフレームワーク (方向性) です。さまざまな認識タスクを統合します。3 については後述します)、視覚認識を独立したタスクから統合タスクに移行できるようになり、視覚的プロンプトにより適したネットワーク アーキテクチャが誕生する可能性があります。
- コンボリューションとトランスフォーマーのどちらかを選択する必要がある場合は、トランスフォーマーのほうがより大きな可能性を秘めています。これは主に、さまざまなデータ モダリティ、特にテキストと画像を統合できるためです。最も一般的で重要な 2 つの方法です。
- 解釈可能性は非常に重要な研究の方向性ですが、私は個人的にディープ ニューラル ネットワークの解釈可能性については悲観的です。 NLP の成功は、解釈可能性ではなく、大規模なコーパスの過剰適合に基づいています。これは実際の AI にとっては良い兆候ではないかもしれません。
方向 1b: 視覚的な事前トレーニング
はホットなトピックです今日の履歴書分野では、この方向で事前トレーニング方法に大きな期待が寄せられています。深層学習の時代では、ビジュアル事前トレーニングは、教師あり、教師なし、クロスモーダルの 3 つのカテゴリに分類できます。一般的な説明は次のとおりです。 ##監修済み 事前トレーニングの展開は比較的明確です。画像レベルの分類データは取得が最も簡単であるため、ディープ ラーニングが普及するずっと前から、将来のディープ ラーニングの基礎となる ImageNet データ セットが存在し、現在でも使用されています。 ImageNet データ セットの合計は 1,500 万を超えており、他の非機密データ セットに上回っていないため、依然として教師あり事前トレーニングで最も一般的に使用されるデータです。もう 1 つの理由は、画像レベルの分類データによって生じるバイアスが少なく、下流への移行にとってより有益であることです。教師なし事前トレーニングによりバイアスがさらに低減されます。
- #教師なしの事前トレーニングでは、曲がりくねった開発プロセスが発生しました。 2014年からは、パッチの位置関係や画像の回転などに基づく判定など、幾何学に基づいた教師なし事前学習手法の第1世代が登場し、生成手法も継続的に開発されています(生成手法は初期に遡ることができます) 、ここでは説明しません)。現時点では、教師なし事前トレーニング方法は教師あり事前トレーニング方法よりも依然として大幅に弱いです。技術的な改善を経て、2019 年までに、対照学習法は下流のタスクにおいて教師あり事前トレーニング法を上回る可能性があることが初めて示され、教師なし学習はまさに CV の世界の焦点となっています。 2021 年以降、ビジュアル トランスフォーマーの台頭により、特殊なタイプの生成タスクである MIM が誕生し、徐々に主流の手法になりました。
- 純粋な教師あり事前トレーニングと教師なし事前トレーニングに加えて、その中間の一種の方法、クロスモーダル事前トレーニングもあります。弱いペアの画像とテキストをトレーニング素材として使用し、画像監視信号によって引き起こされるバイアスを回避する一方で、教師なし手法よりも弱い意味論をよりよく学習できます。さらに、トランスフォーマーの助けにより、視覚言語と自然言語の統合がより自然かつ合理的になります。
- 上記の検討に基づいて、私は次の判断を下します:
- 実際のアプリケーションの観点からは、さまざまな事前トレーニング タスクを組み合わせる必要があります。つまり、少量のラベル付きデータ (検出やセグメンテーションなどのさらに強力なラベル)、中量の画像とテキストのペアのデータ、およびラベルが付いていない大量の画像データを含む混合データ セットを収集する必要があります。あらゆるラベル、およびそのような混合データの事前トレーニング方法を一元的に設計します。
- CV 分野から見ると、教師なしの事前トレーニングは、ビジョンの本質を最もよく反映する研究の方向性です。クロスモーダル事前トレーニングは全体の方向性に大きな影響をもたらしましたが、私は依然として教師なし事前トレーニングが非常に重要であり、継続する必要があると考えています。視覚的な事前トレーニングの考え方は自然言語の事前トレーニングに大きく影響を受けますが、2 つの性質は異なるため、一般化することはできないことに注意してください。特に、自然言語自体は人間が作成したデータであり、すべての単語や文字は人間によって書かれ、当然意味的な意味を持っているため、NLP の事前トレーニング タスクは厳密な意味では本物とは言えません。せいぜい弱く監視された事前トレーニングです。しかし、視覚は異なります。画像信号は人間によって処理されていない客観的に存在する生のデータであり、その中での教師なしの事前トレーニング タスクはさらに困難になるはずです。つまり、クロスモーダル事前トレーニングによってエンジニアリングにおける視覚アルゴリズムが進歩し、より良い認識結果が得られたとしても、視覚の本質的な問題は依然として視覚自体によって解決される必要があります。
- #現時点では、純粋な視覚的な教師なし事前トレーニングの本質は、劣化から学ぶことです。ここでの劣化とは、画像信号から既存の情報の一部を削除し、この情報を復元するためのアルゴリズムを必要とすることを指します。幾何学的な方法では、幾何学的分布情報 (パッチの相対位置など) が削除されます。コントラスト法では、画像全体の情報が (さまざまなビューを抽出することによって) 削除されます。 ); MIM などの生成方法では、画像のローカル情報が削除されます。この劣化に基づく方法には、劣化強度と意味的一貫性との間の矛盾という克服できないボトルネックがある。教師付き信号がないため、視覚表現の学習は完全に劣化に依存するため、劣化が十分に強い必要があります。劣化が十分に強い場合、劣化前後の画像が意味的に一貫しているという保証はなく、悪条件が発生します。トレーニング前の目標。たとえば、比較学習で画像から抽出された 2 つのビューに関連性がない場合、それらの特徴を近づけることは不合理であり、MIM タスクが画像内の重要な情報 (顔など) を削除した場合、この情報を再構成することは合理的ではありません。 。 合理的。これらのタスクを強制的に完了すると、特定のバイアスが導入され、モデルの一般化能力が弱まります。将来的には、劣化を必要としない学習タスクが存在するはずであり、個人的には、圧縮による学習が実現可能なルートであると考えています。
#方向 2: モデルの微調整と生涯学習
As基礎 問題は、モデルの微調整のために多数の異なる設定が開発されていることです。異なる設定を統一したい場合は、トレーニング前のデータ セット Dpre (不可視)、ターゲット トレーニング セット Dtrain、およびターゲット テスト セット Dtest (不可視で予測不可能) の 3 つのデータ セットを考慮すると考えることができます。 3 つの関係についての仮定に応じて、より一般的な設定は次のように要約できます:
- 転移学習: Dpre または Dtrain と Dtest のデータ分布が大きく異なると仮定します;
- 弱い教師あり学習: Dtrain は不完全なアノテーション情報のみを提供すると仮定します。
-
半教師あり学習: Dtrain はデータの一部のみを提供すると仮定します。
- ノイズのある学習: Dtrain のデータ アノテーションの一部が間違っている可能性があると想定されます;
- Active学習: Dtrain がインタラクティブにラベル付け (最も困難なサンプルを選択) してラベル付けの効率を向上できると想定されます;
- 継続的学習: 新しい Dtrain が引き続き表示されるため、学習プロセス中に忘れられる可能性があります Dpre;
- ……
から学ぶべきこと## 一般的な意味から 前述のように、モデル微調整手法の開発とジャンルを分析するための統一されたフレームワークを見つけることは困難です。エンジニアリングおよび実用的な観点から見ると、モデルの微調整の鍵は、ドメイン間の差異の大きさを事前に判断することにあります。 Dpre と Dtrain の差が非常に大きいと思われる場合は、事前トレーニング ネットワークからターゲット ネットワークに転送される重みの割合を減らすか、この差に適応する特別なヘッドを追加する必要があります。 Dtrain と Dtest の差は非常に大きい可能性があるため、微調整プロセス中に強力な正則化を追加して過剰適合を防ぐか、テスト プロセス中にオンライン統計を導入して差をできるだけ相殺する必要があります。上記のさまざまな設定については、それぞれについて大量の研究作業が行われていますが、これは非常に的を絞ったものであるため、ここでは詳しく説明しません。
# この方向性に関しては、次の 2 つの重要な問題があると考えています。 #孤立した環境から生涯学習の統一へ。学術から産業界に至るまで、「ワンタイムデリバリーモデル」という考え方を捨て、モデルを中心にデータガバナンス、モデルメンテナンス、モデル展開などの複数の機能を備えたツールチェーンとして配信内容を理解する必要があります。業界用語では、モデルまたはシステムのセットは、プロジェクトのライフサイクル全体にわたって完全にケアする必要があります。今日、カメラが変更され、明日には新しいタイプのターゲットが検出される可能性があるなど、ユーザーのニーズは変わりやすく予測できないことを考慮する必要があります。私たちは、AI がすべての問題を独立して解決することを追求するわけではありませんが、AI を理解していない人でもこのプロセスに従い、必要な要件を追加して、通常遭遇する問題を解決できるように、AI アルゴリズムには標準化された操作プロセスが必要です。 AI が実際に大衆に普及し、現実的な問題を解決するにはどうすればよいでしょうか。学術界にとっては、現実のシナリオに即した生涯学習の環境をできるだけ早く定義し、対応するベンチマークを確立し、この方向に向けた研究を推進する必要がある。
- #ドメイン間に明らかな違いがある場合、ビッグデータと小規模サンプルの間の競合を解決します。これは、CV と NLP のもう 1 つの違いです。NLP では、文法構造が一般的な単語とまったく同じであるため、基本的にトレーニング前タスクと下流タスクの間のドメイン間の違いを考慮する必要がありませんが、CV では、上流と下流のタスクが区別されていると想定する必要があります。データの分布が大きく異なるため、上流のモデルが微調整されていない場合、基礎となる特徴を下流のデータから抽出することができません (ReLU などのユニットによって直接フィルタリングされます)。したがって、小さなデータを使用して大規模なモデルを微調整することは、NLP 分野では大きな問題ではありません (現在の主流はプロンプトのみを微調整することです) が、CV 分野では大きな問題になります。ここで、視覚的にわかりやすいプロンプトをデザインすることは良い方向かもしれませんが、現在の研究はまだ核心的な問題に到達していません。
- 方向 3: 無限のきめの細かい視覚認識タスク
概要無限のきめの細かい視覚認識 (および同様の概念) に関連する研究はまだ多くありません。そこで、この問題について私なりに解説していきます。今年のVALSEレポートでは、既存の手法と私たちの提案について詳しく説明しました。以下にテキストで説明しますが、より詳細な説明については、私の特別記事または VALSE で作成したレポートを参照してください:
https://zhuanlan.zhihu.com/ p/ 546510418https://zhuanlan.zhihu.com/p/555377882まず、無限に細かい視覚認識の意味を説明したいと思います。簡単に言うと、画像には非常に豊富な意味情報が含まれていますが、明確な基本的な意味単位はありません。人間はその意欲がある限り、画像からますますきめの細かい意味情報を識別できるようになります (下の図に示すように) が、この情報を限定的かつ標準化されたアノテーションを通過させるのは困難です (たとえ十分なアノテーション コストが費やされたとしても)。アルゴリズム学習用に意味的に完全なデータセットを形成します。

ADE20K のような細かく注釈が付けられたデータセットでも、人間が認識できる大量の意味論的なコンテンツが不足しています
私たちは、無限にきめの細かい視覚認識は、オープンドメインの視覚認識よりも難しく、より本質的な目標であると信じています。既存の認識手法を調査し、それらを分類ベースの手法と言語駆動型の手法の 2 つのカテゴリに分類し、それらが無限の細粒度化を達成できない理由を議論します。
- 分類ベースの手法: これには、伝統的な意味での分類、検出、セグメンテーション、その他の手法が含まれます。その基本的な特徴は、それぞれの特徴を次のように与えることです。画像 基本的な意味単位 (画像、ボックス、マスク、キーポイントなど) にはカテゴリ ラベルが割り当てられます。この方法の致命的な欠陥は、認識の粒度が高くなると必然的に認識の確実性が低下する、つまり粒度と確実性が矛盾することである。たとえば、ImageNetでは「家具」と「電化製品」という大きく2つのカテゴリがあり、当然「椅子」は「家具」、「テレビ」は「家電」に属しますが、「マッサージチェア」は「」に属しますか? 「家具」または「家電製品」を判断するのは困難です。これは、意味の粒度の増加によって引き起こされる確実性の低下です。写真の中に解像度が非常に低い「人物」が存在し、その「人物」の「頭」や「目」までが強制的にラベル付けされている場合、アノテーターによって判断が異なる可能性がありますが、現時点では、たとえそれが 1 つまたは 2 つのピクセルであっても、その偏差は IoU などの指標にも大きく影響します。これは、空間粒度の増加によって引き起こされる確実性の低下です。
- 言語駆動メソッド: これには、CLIP によって駆動されるビジュアル プロンプト クラス メソッドや、長期にわたるビジュアル グラウンディングの問題などが含まれます。その基本機能言語を使用して画像内の意味情報を参照し、それを識別することです。言語の導入は確かに認識の柔軟性を高め、自然なオープンドメイン特性をもたらします。ただし、言語自体の参照能力は限られており (数百人がいる場面で特定の個人を参照することを想像してください)、無限に細かい視覚認識のニーズを満たすことはできません。結局のところ、視覚認識の分野では、言語は視覚を補助する役割を果たすべきであり、既存の視覚的プロンプト手法はやや圧倒されるように感じられます。
上記の調査から、現在の視覚認識方法では無限の粒度の目標を達成することはできず、今後さらに多くの問題が発生することがわかります。無限のきめ細かさへの道、乗り越えられない困難に遭遇しました。したがって、私たちは人々がこれらの困難をどのように解決するかを分析したいと考えています。まず、ほとんどの場合、人間は分類タスクを明示的に実行する必要はありません。上記の例に戻ると、人はショッピング モールに「家具」の中に「マッサージ チェア」が置かれているかどうかに関係なく、何かを購入するためにショッピング モールに行きます。人間は簡単な案内で「マッサージチェア」がある場所をすぐに見つけることができます。第二に、人間は画像内のオブジェクトを参照するために言語を使用することに限定されず、より柔軟な方法 (手でオブジェクトを指すなど) を使用して参照を完了し、より詳細な分析を行うことができます。
#これらの分析を組み合わせて、無限の粒度の目標を達成するには、次の 3 つの条件を満たす必要があります。
- オープン性: オープン ドメイン認識は、無限の詳細な認識のサブ目標です。現時点では、言語を導入することがオープン性を達成するための最良の解決策の 1 つです。
- # 具体性: 言語を導入するときは、その言語に束縛されるべきではありませんが、視覚的にわかりやすい参照スキーム (つまり、認識タスク) を設計する必要があります。
- 可変粒度: 必ずしも最も細かい粒度を識別する必要はありませんが、認識の粒度はニーズに応じて柔軟に変更できます。
これら 3 つの条件に基づいて、オンデマンドの視覚認識タスクを設計しました。従来の意味での統合視覚認識とは異なり、オンデマンド視覚認識は、注釈、学習、評価の単位としてリクエストを使用します。現在システムはインスタンスからセマンティックへのセグメンテーションとセマンティックからインスタンスへのセグメンテーションの2種類のリクエストをサポートしているため、両者を組み合わせることで任意の細かさの画像セグメンテーションを実現できます。オンデマンド視覚認識のもう 1 つの利点は、任意の数のリクエストを完了した後で停止しても (大量の情報に注釈が付けられない場合でも) 注釈の精度に影響を与えないことです。これは、オープン ドメインのスケーラビリティ (追加など) に有益です。新しいセマンティック カテゴリ) には大きな利点があります。具体的な詳細については、オンデマンド視覚認識に関する記事を参照してください (上記のリンクを参照)。
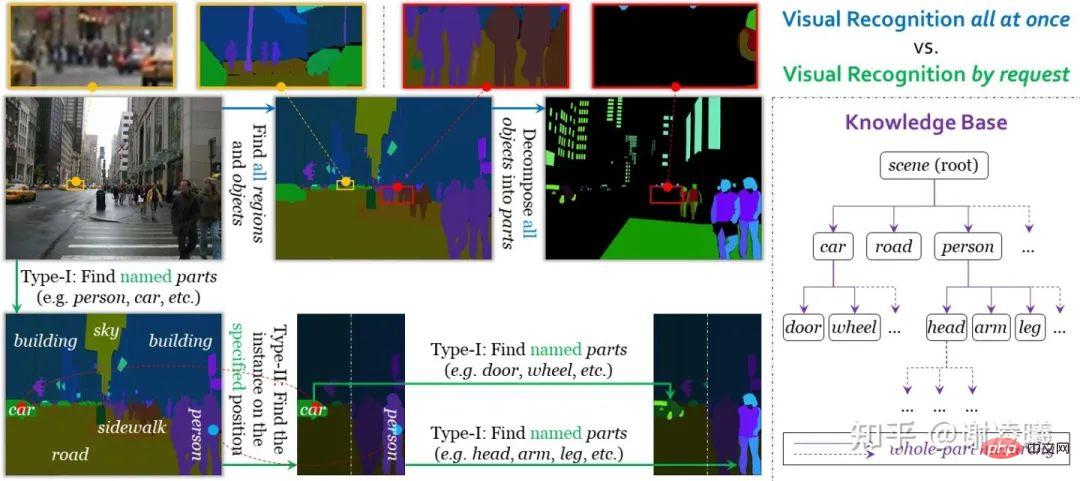
統合ビジュアル アイデンティティとオンデマンド ビジュアル アイデンティティの比較
##この記事を書き終えた後も、オンデマンド視覚認識が他の方向に与える影響について考え続けています。ここでは 2 つの観点を示します。
- オンデマンド視覚認識におけるリクエストは、基本的に視覚的にわかりやすいプロンプトです。これにより、視覚モデルを調べるという目的を達成できるだけでなく、純粋な言語プロンプトによって引き起こされる参照の曖昧さを回避することもできます。より多くの種類のリクエストが導入されるにつれて、このシステムはより成熟することが予想されます。
- #オンデマンド視覚認識は、さまざまな視覚タスクをフォームに統合する可能性を提供します。たとえば、分類、検出、セグメンテーションなどのタスクは、このフレームワークの下で統合されます。これは視覚的な事前トレーニングにインスピレーションをもたらす可能性があります。現時点では、視覚的な事前トレーニングと下流の微調整の境界は明確ではなく、事前トレーニングされたモデルがさまざまなタスクに適しているのか、それとも特定のタスクの改善に重点を置いているのかはまだ不明です。しかし、正式に統一された認識タスクが出現した場合、この議論はもはや意味がなくなるかもしれません。ところで、下流タスクの正式な統合も、NLP 分野が享受できる大きな利点です。
上記の方向以外の
CV分野の問題を、認識、生成、インタラクション、識別はその中で最も単純なものです。これら 3 つのサブフィールドに関する簡単な分析は次のとおりです。
- 認識の分野では、従来の認識指標は明らかに時代遅れであるため、人々は最新の評価指標を必要としています。現在、視覚認識への自然言語の導入は明らかかつ不可逆的な傾向ですが、それだけでは十分ではなく、業界はタスク レベルでのさらなる革新を必要としています。
- #生成は、認識よりも高度な能力です。人間はさまざまな一般的な物体を容易に認識できますが、現実的な物体を描くことができる人はほとんどいません。統計学習の言葉で言えば、これは、生成モデルは同時分布 p(x,y) をモデル化する必要があるのに対し、判別モデルは条件付き分布 p(y|x) のみをモデル化する必要があるためです。前者は次の結果を導き出すことができます。後者から前者を導き出すことはできませんが、後者から前者を導き出すことはできません。業界の発展から判断すると、画像生成の品質は向上し続けていますが、(明らかに非現実的なコンテンツを生成せずに)生成されたコンテンツの安定性と制御性は依然として改善する必要があります。同時に、生成されたコンテンツは認識アルゴリズムを支援する機能がまだ比較的弱く、人々が仮想データや合成データを十分に活用して実際のデータトレーニングに匹敵する結果を達成することは困難です。これら 2 つの問題について、私たちの観点は、既存の指標 (生成タスクでは FID、IS など) に代わる、より適切でより本質的な評価指標を設計する必要がある一方、生成タスクと識別タスクを組み合わせて統一された評価を定義する必要があるということです。索引)。
- 1978 年、コンピューター ビジョンのパイオニアである David Marr は、ビジョンの主な機能は環境の 3 次元モデルを構築し、インタラクションを通じて知識を学習することであると構想しました。認識や生成と比較すると、インタラクションは人間の学習に近いものですが、業界での研究は比較的少ないです。インタラクションに関する研究の主な困難は、実際のインタラクション環境を構築することにあります。正確に言うと、視覚データセットの現在の構築方法は環境のまばらなサンプリングから得られますが、インタラクションには連続的なサンプリングが必要です。視覚という本質的な問題を解決するには、明らかにインタラクションが不可欠です。業界では多くの関連研究(身体化知能など)が行われていますが、普遍的なタスク駆動型の学習目標はまだ現れていません。コンピューター ビジョンの先駆者である David Marr が提唱したアイデアをもう一度繰り返します。ビジョンの主な機能は、環境の 3 次元モデルを構築し、インタラクションを通じて知識を学習することです。他の AI の方向性を含むコンピューター ビジョンは、真に実用的なものになるために、この方向に発展する必要があります。
#つまり、さまざまなサブ分野で、統計学習 (特に深層学習) のみに依存して強力なフィッティング機能を実現する試みが行われています。結実への限界。今後の開発はCVをより本質的に理解し、さまざまな課題に対してより合理的な評価指標を確立することが第一歩となります。
結論
数回の集中的な学術交流を経て、少なくとも視覚(認識)に関しては業界の混乱をはっきりと感じます。一般に、興味深く価値のある研究課題はますます少なくなり、敷居はますます高くなっています。このままでは、近い将来、CV 研究が NLP の道を歩み、徐々に 2 つのカテゴリーに分かれる可能性があります。
1 つのタイプは巨大なデータを使用します。計算量 リソースは事前にトレーニングされており、SOTA は常に無駄に更新されますが、もう 1 つのタイプは、革新を強制するために斬新だが意味のない設定を常に設計しています。これは履歴書分野にとって明らかに良いことではありません。このようなことを避けるために、業界は常にビジョンの本質を探求し、より価値のある評価指標を作成することに加えて、寛容性、特に非主流方向への寛容性を高める必要があります。 SOTA に到達しない提出物は厄介な問題です。現在のボトルネックは誰もが直面する課題であり、AI の開発が停滞すれば誰もが免れることはできません。最後までご覧いただきありがとうございました。フレンドリーな議論を歓迎します。
著者の声明
すべての内容は著者自身の見解のみを表しており、覆される可能性があります。二次転載は声明とともに転載する必要があります。ありがとう!
以上がファーウェイの若き天才、謝玲熙氏:視覚認識分野の発展についての個人的見解の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



