


この記事では、デシジョン ツリーとランダム フォレスト モデルについて詳しく紹介します。さらに、デシジョン ツリーとランダム フォレストのどのハイパーパラメータがパフォーマンスに大きな影響を与えるかを示し、過小適合と過適合の間の最適な解決策を見つけることができます。デシジョン ツリーとランダム フォレストの背後にある理論を理解した後。 、Scikit-Learnを使用して実装していきます。
デシジョン ツリーは、機械学習の予測モデリングにとって重要なアルゴリズムです。古典的なデシジョン ツリー アルゴリズムは何十年も前から存在しており、ランダム フォレストなどの最新のアルゴリズムは利用可能な最も強力な手法の 1 つです。
通常、このようなアルゴリズムは「デシジョン ツリー」と呼ばれますが、R などの一部のプラットフォームでは CART と呼ばれます。 CART アルゴリズムは、バギング デシジョン ツリー、ランダム フォレスト、ブースティング デシジョン ツリーなどの重要なアルゴリズムの基礎を提供します。
線形モデルとは異なり、デシジョン ツリーはノンパラメトリック モデルです。数学的な決定関数によって制御されず、最適化する重みや切片がありません。実際、デシジョン ツリーは特徴を考慮して空間を分割します。
CART モデルの表現はバイナリ ツリーです。これはアルゴリズムとデータ構造からなるバイナリ ツリーです。各ルート ノードは、入力変数 (x) とその変数の分割点を表します (変数が数値であると仮定します)。
ツリーのリーフ ノードには、予測を行うために使用される出力変数 (y) が含まれています。新しい入力が与えられると、ツリーのルート ノードから開始して特定の入力を計算することによってツリーが走査されます。
デシジョン ツリーの利点は次のとおりです。
デシジョン ツリーの欠点は次のとおりです:
ランダム フォレストは、最も人気があり強力な機械学習アルゴリズムの 1 つです。これは、ブートストラップ集約またはバギングと呼ばれる統合機械学習アルゴリズムです。
デシジョン ツリーのパフォーマンスを向上させるために、ランダムな特徴サンプルを含む多数のツリーを使用できます。
デシジョン ツリーとランダム フォレストを使用して、貴重な従業員の損失を予測します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set_style("whitegrid")
plt.style.use("fivethirtyeight")
df = pd.read_csv("WA_Fn-UseC_-HR-Employee-Attrition.csv")
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
df.drop(['EmployeeCount', 'EmployeeNumber', 'Over18', 'StandardHours'], axis="columns", inplace=True)
categorical_col = []
for column in df.columns:
if df[column].dtype == object and len(df[column].unique()) 50:
categorical_col.append(column)
df['Attrition'] = df.Attrition.astype("category").cat.codes
categorical_col.remove('Attrition')
label = LabelEncoder()
for column in categorical_col:
df[column] = label.fit_transform(df[column])
X = df.drop('Attrition', axis=1)
y = df.Attrition
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
def print_score(clf, X_train, y_train, X_test, y_test, train=True):
if train:
pred = clf.predict(X_train)
print("Train Result:n================================================")
print(f"Accuracy Score: {accuracy_score(y_train, pred) * 100:.2f}%")
print("_______________________________________________")
print(f"Confusion Matrix: n {confusion_matrix(y_train, pred)}n")
elif train==False:
pred = clf.predict(X_test)
print("Test Result:n================================================")
print(f"Accuracy Score: {accuracy_score(y_test, pred) * 100:.2f}%")
print("_______________________________________________")
print(f"Confusion Matrix: n {confusion_matrix(y_test, pred)}n")
from sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=True)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=False)
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
params = {
"criterion":("gini", "entropy"),
"splitter":("best", "random"),
"max_depth":(list(range(1, 20))),
"min_samples_split":[2, 3, 4],
"min_samples_leaf":list(range(1, 20)),
}
tree_clf = DecisionTreeClassifier(random_state=42)
tree_cv = GridSearchCV(tree_clf, params, scoring="accuracy", n_jobs=-1, verbose=1, cv=3)
tree_cv.fit(X_train, y_train)
best_params = tree_cv.best_params_
print(f"Best paramters: {best_params})")
tree_clf = DecisionTreeClassifier(**best_params)
tree_clf.fit(X_train, y_train)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=True)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=False)
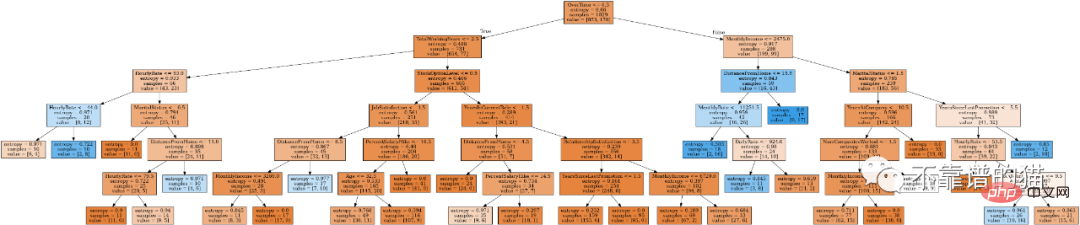
from IPython.display import Image
from six import StringIO
from sklearn.tree import export_graphviz
import pydot
features = list(df.columns)
features.remove("Attrition")
dot_data = StringIO()
export_graphviz(tree_clf, out_file=dot_data, feature_names=features, filled=True)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
Image(graph[0].create_png())
随机森林是一种元估计器,它将多个决策树分类器对数据集的不同子样本进行拟合,并使用均值来提高预测准确度和控制过拟合。
随机森林算法参数:
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=100)
rf_clf.fit(X_train, y_train)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=True)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=False)
调优随机森林的主要参数是n_estimators参数。一般来说,森林中的树越多,泛化性能越好,但它会减慢拟合和预测的时间。
我们还可以调优控制森林中每棵树深度的参数。有两个参数非常重要:max_depth和max_leaf_nodes。实际上,max_depth将强制具有更对称的树,而max_leaf_nodes会限制最大叶节点数量。
n_estimators = [100, 500, 1000, 1500]
max_features = ['auto', 'sqrt']
max_depth = [2, 3, 5]
max_depth.append(None)
min_samples_split = [2, 5, 10]
min_samples_leaf = [1, 2, 4, 10]
bootstrap = [True, False]
params_grid = {'n_estimators': n_estimators, 'max_features': max_features,
'max_depth': max_depth, 'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf, 'bootstrap': bootstrap}
rf_clf = RandomForestClassifier(random_state=42)
rf_cv = GridSearchCV(rf_clf, params_grid, scoring="f1", cv=3, verbose=2, n_jobs=-1)
rf_cv.fit(X_train, y_train)
best_params = rf_cv.best_params_
print(f"Best parameters: {best_params}")
rf_clf = RandomForestClassifier(**best_params)
rf_clf.fit(X_train, y_train)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=True)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=False)
本文主要讲解了以下内容:
以上がデシジョン ツリーとランダム フォレストの理論、実装、ハイパーパラメータ調整の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



