


混合精度は大規模な深層学習モデルをトレーニングするために必要なものとなっていますが、多くの課題ももたらします。モデルのパラメーターと勾配を低精度のデータ型 (FP16 など) に変換すると、トレーニングを高速化できますが、数値の安定性の問題も発生します。 FP16 トレーニングに使用される勾配は、オーバーフローまたは不十分になる可能性が高く、その結果、オプティマイザーによる計算が不正確になり、アキュムレーターがデータ型の範囲を超えるなどの問題が発生します。

#この記事では、混合精度トレーニングの数値安定性の問題について説明します。大規模なトレーニング ジョブは、数値の不安定性に対処するために数日間保留されることがよくあり、プロジェクトの遅延を引き起こします。したがって、Tensor Collection Hook を導入してトレーニング中に勾配条件を監視できるため、モデルの内部状態をよりよく理解し、数値的不安定性をより迅速に特定できるようになります。
これは、トレーニングの初期段階でモデルの内部状態を理解し、後のトレーニングでモデルが不安定になりやすいかどうかを判断する非常に良い方法です。トレーニングは、効率を大幅に向上させるのに役立ちます。したがって、この記事では、注意を払う価値のある一連の警告と、数値の不安定性に対する解決策を提供します。
ディープラーニングはより大きな基本モデルに向けて進化し続けています。現在、GPT や T5 などの大規模な言語モデルが NLP を支配しており、CLIP などの対照的なモデルは、CV における従来の教師ありモデルよりも一般化が優れています。特に、CLIP のテキスト埋め込みを学習する機能は、トレーニングが困難であった過去の CV モデルの機能を超えたゼロショット推論および少数ショット推論を実行できることを意味します。
これらの大規模なモデルには通常、ビジュアルとテキストの両方のトランスフォーマーの深いネットワークが含まれており、数十億のパラメーターが含まれています。 GPT3 には 1,750 億のパラメータがあり、CLIP は数百テラバイトの画像でトレーニングされます。モデルとデータのサイズにより、大規模な GPU クラスターでのモデルのトレーニングには数週間、場合によっては数か月かかることになります。トレーニングを高速化し、必要な GPU の数を減らすために、モデルは混合精度でトレーニングされることがよくあります。
Hybrid Precision Training では、一部のトレーニング操作が FP32 ではなく FP16 に配置されます。 FP16 で実行される操作は必要なメモリが少なく、最新の GPU では FP32 よりも最大 8 倍高速に処理できます。 FP16 でトレーニングされたほとんどのモデルの精度は低くなりますが、過剰なパラメーター化によるパフォーマンスの低下は見られません。
Volta アーキテクチャに NVIDIA の Tensor コアが導入されたことで、低精度浮動小数点アクセラレーション トレーニングが高速化されました。深層学習モデルには多くのパラメーターがあるため、通常は 1 つのパラメーターの正確な値は重要ではありません。数値を 32 ビットではなく 16 ビットで表すことにより、より多くのパラメーターを Tensor コア レジスターに一度に適合させることができ、各操作の並列性が向上します。


HuggingFace の T5 実装では、モデル バリアントはトレーニング後でも INF 値を生成します。非常に深い T5 モデルでは、アテンション値が層全体に蓄積され、最終的には FP16 範囲外に達し、その結果、BN 層の nan などの値が無限になります。彼らは、FP16 で INF 値を最大値に変更することでこの問題を解決しましたが、これが推論に与える影響はごくわずかであることがわかりました。
もう 1 つの一般的な問題は、ADAM オプティマイザーの制限です。小規模な更新として、ADAM は勾配の 1 番目と 2 番目のモーメントの移動平均を使用して、モデル内の各パラメーターの学習率を調整します。
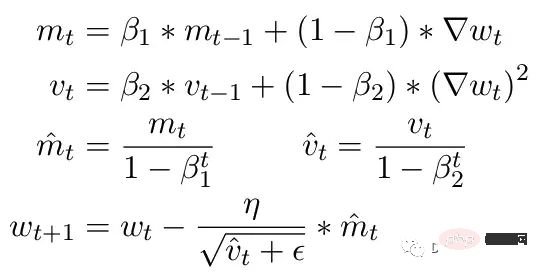
ここで、Beta1 と Beta2 は各瞬間の移動平均パラメータで、通常はそれぞれ .9 と .999 に設定されます。ベータ パラメーターをステップ数の累乗で割ると、更新の初期バイアスが除去されます。更新ステップ中に、ゼロによる除算エラーを避けるために、小さなイプシロンが 2 番目のモーメント パラメーターに追加されます。イプシロンの一般的なデフォルト値は 1e-8 です。ただし、FP16 の最小値は 5.96e-8 です。これは、2 番目のモーメントが小さすぎる場合、更新はゼロで除算されることを意味します。したがって、PyTorch では、トレーニングが分岐しないように、更新によってこのステップの変更がスキップされます。しかし問題は依然として存在しており、特に Beta2=.999 の場合、5.96e-8 より小さい勾配ではパラメータの重みの更新が長時間停止し、オプティマイザが不安定な状態になる可能性があります。
ADAM の利点は、これら 2 つの瞬間を使用することで、各パラメーターの学習率を調整できることです。学習パラメータが遅い場合は学習速度を加速し、学習パラメータが速い場合は学習速度を遅くすることができます。しかし、複数のステップで勾配がゼロになるように計算された場合、小さな正の値であっても、学習率が下方に調整される前にモデルが発散してしまいます。
また、PyTorch には現在、混合精度を使用するときにイプシロンが 1e-7 に自動的に変更される問題があり、これは正の値に戻るときに勾配が発散するのを防ぐのに役立ちます。しかし、そうすると新たな問題が発生し、勾配が同じ範囲にあることがわかっている場合、ε を増加させると、学習率に適応するオプティマイザーの能力が低下します。したがって、やみくもにイプシロンを増加しても、勾配ゼロによるトレーニングの停滞の問題を解決することはできません。
トレーニング中に発生する可能性のある不安定性をさらに実証するために、CLIP 画像モデルで一連の実験を構築しました。 CLIP は、ビジュアル トランスフォーマーとこれらの画像を説明するテキスト埋め込みを通じて画像を同時に学習する、対比学習ベースのモデルです。比較コンポーネントは、データの各バッチ内の元の説明と画像を照合しようとします。損失はバッチで計算されるため、より大きなバッチでトレーニングするとより良い結果が得られることが示されています。
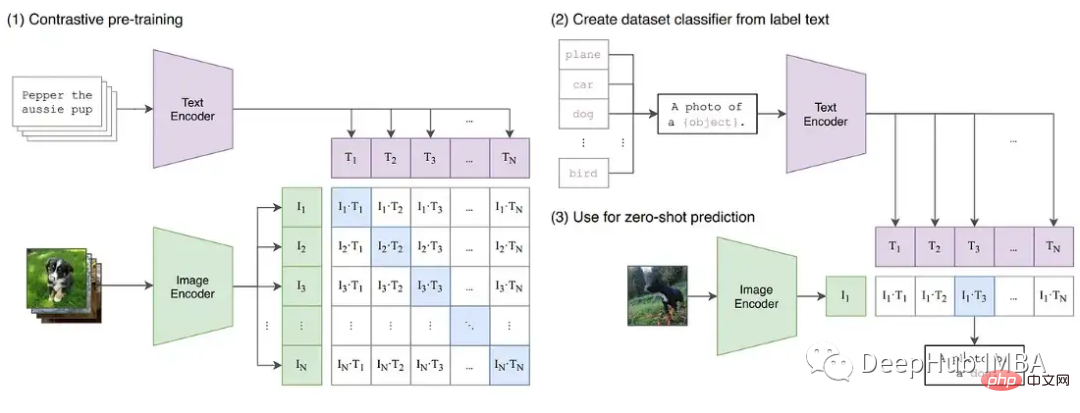
CLIP は、GPT に似た言語モデルと ViT 画像モデルという 2 つのトランスフォーマー モデルを同時にトレーニングします。両方のモデルの深さにより、勾配が FP16 の制限を超える可能性が生じます。 OpenClip (arxiv 2212.07143) の実装では、FP16 を使用した場合のトレーニングの不安定性について説明しています。
トレーニング中の内部モデルの状態をより深く理解するために、Tensor Collection Hook (TCH) を開発しました。 TCH はモデルをラップし、重み、勾配、損失、入力、出力、およびオプティマイザーのステータスに関する概要情報を定期的に収集できます。
たとえば、この実験では、トレーニング中に勾配条件を見つけて記録したいと考えています。たとえば、10 ステップごとに各レイヤーから勾配のノルム、最小値、最大値、絶対値、平均値、標準偏差を収集し、その結果を TensorBoard で視覚化することができます。

これで、out_dir を --logdir 入力として TensorBoard を起動できます。

CLIP でのトレーニングの不安定性を再現するために、Laion の 50 億画像データセットを OpenCLIP のサブセットのトレーニングに使用しました。モデルを TCH でラップし、モデルの勾配、重み、オプティマイザー モーメントの状態を定期的に保存します。これにより、不安定性が発生したときにモデル内で何が起こるかを観察できます。
vvi-h-14 バリアントから始めて、OpenCLIP の作成者はトレーニング中の安定性の問題について説明しています。トレーニング前のチェックポイントから開始して、CLIP トレーニングの後半の学習率と同様に、学習率を 1-e4 まで増加させます。トレーニングが 300 ステップに達すると、より難しいトレーニング バッチが 10 個連続して意図的に導入されます。
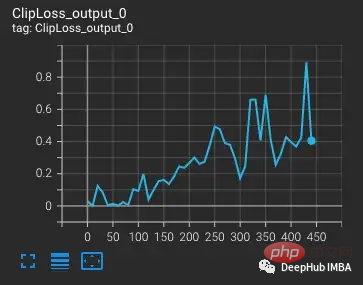
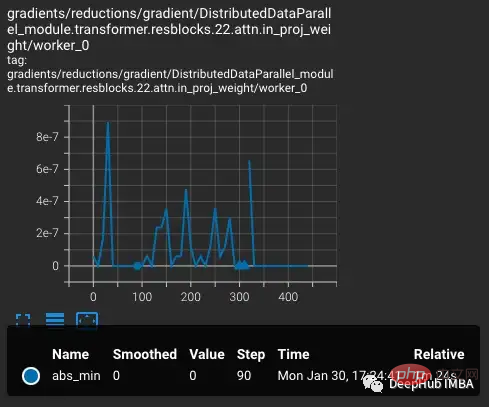
学習率が増加するにつれて損失も増加しますが、これは予想通りです。ステップ300でより困難な状況が導入されると、わずかではあるが損失が増加する。モデルは困難なケースを見つけますが、nan が勾配内に現れるため (2 番目のプロットでは三角形として示されています)、これらのステップでは重みのほとんどは更新されません。この困難な一連のケースを通過すると、勾配はゼロに下がります。
ここで何が起こっていますか?勾配が 0 なのはなぜですか?問題は PyTorch の勾配スケーリングにあります。勾配スケーリングは、混合精度トレーニングにおける重要なツールです。数百万または数十億のパラメータを持つモデルでは、1 つのパラメータの勾配が小さく、FP16 の最小範囲を下回ることがよくあるためです。
ハイブリッド高精度トレーニングが最初に提案されたとき、深層学習の科学者は、モデルがトレーニングの初期段階では予想どおりにトレーニングされることが多いが、最終的には発散することが多いことに気づきました。トレーニングが進行するにつれて、勾配が小さくなる傾向があり、一部のアンダーフロー FP16 がゼロになり、トレーニングが不安定になります。

勾配アンダーフローを解決するために、初期の手法では、単純に損失に固定量を乗算し、より大きな勾配を計算してから、重みの更新を調整します。同じ固定量 (混合精度トレーニング中、重みは依然として FP32 に保存されます)。しかし、この固定金額ではまだ不十分な場合もあります。また、PyTorch の勾配スケーリングなどの新しい技術は、より大きな乗数 (通常は 65536) から始まります。ただし、これが非常に高いため、大きな勾配が FP16 値をオーバーフローする可能性があるため、勾配スケーラーはオーバーフローする nan 勾配を監視します。 nan が観察された場合は、このステップでの重みの更新をスキップして乗数を半分にし、次のステップに進みます。これは、勾配内にナンが観察されなくなるまで続きます。勾配スケーラーがステップ 2000 で nan を検出しない場合、乗数を 2 倍にしようとします。
上記の例では、グラデーション スケーラーは期待どおりに正確に機能します。損失が予想より大きく、オーバーフローにつながる大きな勾配が作成される一連のケースを渡します。しかし、問題は、乗数が低くなり、より小さい勾配がゼロに低下し、勾配スケーラーがゼロ勾配を監視しないのは nan だけであることです。
上記の例は、難しい例を意図的にグループ化しているため、最初はいくぶん意図的に見えるかもしれません。しかし、数日間のトレーニングの後、大規模なバッチの場合、nan 異常が生成される確率は確実に増加します。したがって、勾配をゼロに押し上げるのに十分なナンに遭遇する可能性は非常に高いです。実際、たとえ困難なサンプルが導入されていなくても、数千のトレーニング ステップの後、勾配が常にゼロになることがよくあります。
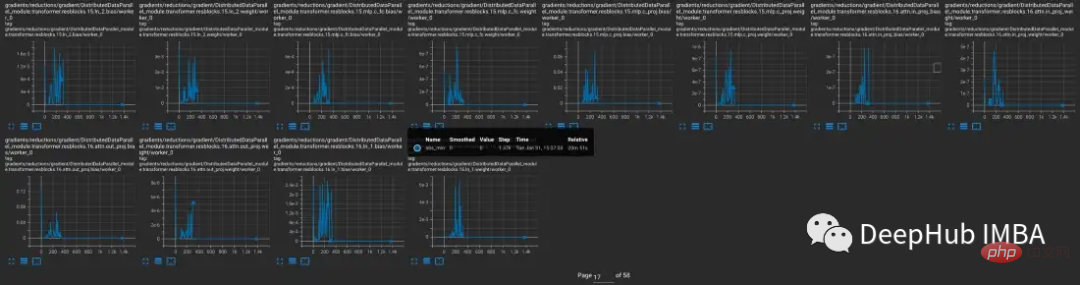
問題がいつ発生するのか、いつ発生しないのかをさらに調査するために、CLIP を、通常は次の条件でトレーニングされる CLIP と比較しました。混合精度。より小さい CV モデル YOLOV5 が比較されます。どちらの場合も、トレーニング中に各層のゼロ勾配の頻度が追跡されました。

トレーニングの最初の 9000 ステップ中に、CLIP のレイヤーの 5 ~ 20% で勾配アンダーフローが発生しますが、Yolo のレイヤーではたまにアンダーフローが発生するだけです。 。 CLIP のアンダーフロー レートも時間の経過とともに増加し、トレーニングの安定性が低下します。
CLIP 範囲の勾配振幅が YOLO 範囲の勾配振幅よりもはるかに大きいため、勾配スケーリングを使用してもこの問題は解決されません。 CLIP の場合、FP16 では、勾配スケーラーが大きな勾配を最大値に近づけますが、最小勾配は最小値を下回ったままになります。
場合によっては、勾配スケーラーのパラメーターを調整すると、アンダーフローを防ぐことができます。 CLIP の場合、より大きな乗数から始めて増加間隔を短くするように変更を試みることができます。

しかし、オーバーフローを防ぐために乗数がすぐに低下し、小さな勾配が強制的にゼロに戻されることがわかります。

スケーリングを改善する 1 つの解決策は、パラメーター範囲により適応できるようにすることです。たとえば、論文「混合精度トレーニングのための適応損失スケーリング」では、モデル全体ではなく層ごとに損失スケーリングを実行することを推奨しています。これにより、アンダーフローを防ぐことができます。私たちの実験は、より適応的なアプローチの必要性を示しています。 CLIP レイヤー内の勾配は依然として FP16 範囲全体をカバーしているため、トレーニングの安定性を確保するには、スケーリングを個々のパラメーターに適合させる必要があります。ただし、このような詳細なスケーリングには大量のメモリが必要となり、トレーニング バッチ サイズが減少します。
新しいハードウェアは、より効率的なソリューションを提供します。たとえば、BFloat16 (BF16) は、精度を犠牲にして範囲を拡大するもう 1 つの 16 ビット データ型です。 FP16 は 5.96e-8 ~ 65,504 を処理しますが、BF16 は FP32 と同じ範囲の 1.17e-38 ~ 3.39e38 を処理できます。ただし、BF16 の精度は FP16 よりも低いため、一部のモデルは収束しません。しかし、大型の変圧器モデルの場合、BF16 が収束を低減することは示されていません。
困難な観測のバッチを挿入して同じテストを実行します。BF16 では、NaN からの勾配スケーリングの変化が勾配で観察されないため、ハードケースが導入されると勾配が急上昇し、その後通常のトレーニングに戻ります。

FP16 と BF16 の CLIP を比較すると、BF16 では勾配アンダーフローがたまに発生するだけであることがわかりました。

PyTorch 1.12 以降では、AMP を少し変更するだけで BF16 を有効にすることができます。

より高い精度が必要な場合は、Tensorfloat32 (TF32) データ型を試すことができます。 Nvidia が Ampere GPU に導入した TF32 は、FP16 の精度を維持しながら、BF16 の範囲ビットを追加する 19 ビット浮動小数点です。 FP16 や BF16 とは異なり、混合精度で有効にするのではなく、FP32 を直接置き換えるように設計されています。 PyTorch で TF32 を有効にするには、トレーニングの先頭に 2 行を追加します。

ここで注意してください: PyTorch 1.11 より前は、このデータ型をサポートする GPU では TF32 がデフォルトで有効でした。 PyTorch 1.11 以降では、手動で有効にする必要があります。 TF32 のトレーニング速度は BF16 や FP16 よりも遅く、理論上の FLOPS は FP16 の半分に過ぎませんが、それでも FP32 のトレーニング速度よりははるかに高速です。
Amazon AWS を使用している場合: BF16 および TF32 は、P4d、P4de、G5、Trn1、および DL1 インスタンスで利用できます。
上の例は、FP16 全体の制限を特定して修正する方法を示しています。しかし、これらの問題はトレーニングの後半に現れることがよくあります。 OpenCLIP トレーニングで発生するように、トレーニングの初期段階でモデルが生成する損失が大きく、外れ値に対する感度が低い場合、問題が発生するまでに数日かかり、高価な計算時間が無駄になることがあります。
FP16 と BF16 にはどちらも長所と短所があります。 FP16 の制限により、トレーニングが不安定になり、停滞する可能性があります。ただし、BF16 は精度が低く、収束性も劣る可能性があります。そのため、トレーニングの早い段階で FP16 の不安定性の影響を受けやすいモデルを確実に特定し、不安定性が発生する前に情報に基づいた意思決定を行えるようにしたいと考えています。したがって、その後のトレーニングの不安定性を示すモデルと示さないモデルを再度比較すると、2 つの傾向が見つかります。

FP16 でトレーニングされた YOLO モデルと BF16 でトレーニングされた CLIP モデルはどちらも、勾配アンダーフロー率が通常 1% 未満であることを示しています。グラジエントのアンダーフロー率は通常 1% 未満であり、時間が経っても安定しています。

FP16 でトレーニングされた CLIP モデルのアンダーフロー率は、トレーニングの最初の 1000 ステップで 5 ~ 10% であり、時間の経過とともに上昇傾向にあります。
したがって、TCH を使用して勾配のアンダーフロー レートを追跡することで、トレーニングの最初の 4 ~ 6 時間以内に勾配の不安定性が高まる傾向を特定できます。この傾向が見られる場合は、BF16 に切り替えます。
ハイブリッド精度トレーニングは、既存の大規模ベース モデルのトレーニングの重要な部分ですが、数値の安定性には特別な注意が必要です。モデルの内部状態を理解することは、モデルが混合精度データ型の制限に遭遇した場合を診断するために重要です。モデルを TCH でラップすることで、パラメーターまたは勾配が数値制限に近づいているかどうかを追跡し、不安定が発生する前にトレーニングの変更を実行できるため、トレーニングの実行が失敗する日数が削減される可能性があります。
以上が大規模モデルの混合精度トレーニングの制限を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



