



オンラインでダウンロードした一部の PDF 学習教材には透かしが入っており、読むのに大きな影響を与えます。たとえば、下の図は pdf ファイルから切り出したものですが、今日は Python を使ってこの問題を解決してみます。

PIL: Python Imaging Library は、Python 上の非常に強力な画像処理標準ライブラリですが、Python 2.7 のみをサポートしているため、ボランティア 著者は、PIL に基づいて Python 3 をサポートする枕を作成し、いくつかの新機能を追加しました。
pip install pillow
pymupdf Python を使用して、拡張子が *.pdf、.xps、.oxps、.epub、.cbz、または *.fb2 のファイルにアクセスできます。複数ページの TIFF 画像など、多くの一般的な画像形式もサポートされています。
pip install PyMuPDF
必要なモジュールをインポートします
from PIL import Image from itertools import product import fitz import os
pdf 透かし除去の原理は、画像の透かし除去の原理と似ています。エディターは最初に透かしを除去します。上記の画像の透かしから始めます。
コンピュータを勉強したことがある人なら誰でも、コンピュータで赤、緑、青を表すのに RGB が使用され、赤を表すのに (255, 0, 0) が使用され、赤を表すのに (0, 255, 0) が使用されることを知っています。緑、(0, 0 , 255) は青、(255, 255, 255) は白、(0, 0, 0) は黒を表します。ウォーターマーク除去の原理は、ウォーターマークの色を白 (255, 255, 255) に変更することです。 255、255)。
まず画像の幅と高さを取得し、itertools モジュールを使用して幅と高さのデカルト積をピクセルとして取得します。各ピクセルの色は、RGB の最初の 3 ビットとアルファ チャネルの 4 番目のビットで構成されます。アルファ チャネルは必要ありません。RGB データのみが必要です。
def remove_img():
image_file = input("请输入图片地址:")
img = Image.open(image_file)
width, height = img.size
for pos in product(range(width), range(height)):
rgb = img.getpixel(pos)[:3]
print(rgb)
WeChat スクリーンショットを使用して、ウォーターマーク ピクセルの RGB を確認します。
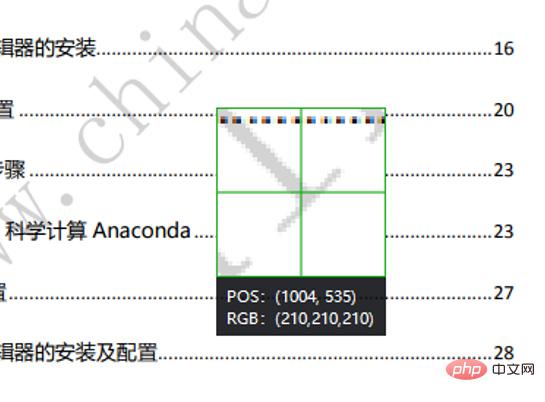
ウォーターマークのRGBが(210, 210, 210)であることがわかりますが、ここではRGBの合計が620を超えた場合にウォーターマークと判定されます。このとき、ピクセルの色を白に置き換えます。最後に画像を保存します。
rgb = img.getpixel(pos)[:3]
if(sum(rgb) >= 620):
img.putpixel(pos, (255, 255, 255))
img.save('d:/qsy.png')
結果の例:

PDF 透かし除去の原理は、画像の透かし除去の原理とほぼ同じです。 PyMuPDF を使用します PDF ファイルを開いた後、PDF の各ページをピックスマップ画像に変換します。ピックスマップには独自の RGB があります。PDF ウォーターマークの RGB を (255, 255, 255) に変更し、最後に次のように保存するだけです。画像。
def remove_pdf():
page_num = 0
pdf_file = input("请输入 pdf 地址:")
pdf = fitz.open(pdf_file);
for page in pdf:
pixmap = page.get_pixmap()
for pos in product(range(pixmap.width), range(pixmap.height)):
rgb = pixmap.pixel(pos[0], pos[1])
if(sum(rgb) >= 620):
pixmap.set_pixel(pos[0], pos[1], (255, 255, 255))
pixmap.pil_save(f"d:/pdf_images/{page_num}.png")
print(f"第{page_num}水印去除完成")
page_num = page_num + 1
結果の例:
画像を PDF に変換画像の順序、数値ファイル名は、最初に int 型に変換してからソートする必要があります。 PyMuPDF モジュールで画像を開いた後、convertToPDF() 関数を使用して画像を単一ページの PDF に変換します。新しい PDF ファイルに挿入します。
def pic2pdf():
pic_dir = input("请输入图片文件夹路径:")
pdf = fitz.open()
img_files = sorted(os.listdir(pic_dir),key=lambda x:int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
pdf.insertPDF(imgpdf)
pdf.save("d:/demo.pdf")
pdf.close()
PDF や写真上の迷惑な透かしは、強力な Python の前でついに消えることができます。皆さんは十分に勉強しましたか?
以上が超シンプル! Python を使用して画像と PDF から透かしを削除するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



