



#マイクロサービスはドメイン駆動設計 (DDD) に従っており、開発プラットフォームとは何の関係もありません。 Python マイクロサービスも例外ではありません。 Python3 のオブジェクト指向の性質により、DDD の観点からサービスをモデル化することが容易になります。
マイクロサービス アーキテクチャの力は、その多言語性にあります。企業はその機能を一連のマイクロサービスに分割し、各チームは自由にプラットフォームを選択できます。
当社のユーザー管理システムは、追加、検索、検索、ログ サービスという 4 つのマイクロサービスに分解されています。追加されたサービスは Java プラットフォームで開発され、復元性と拡張性を確保するために Kubernetes クラスターにデプロイされます。これは、残りのサービスも Java で開発しなければならないという意味ではなく、個々のサービスに適したプラットフォームを自由に選択することができます。
検索サービスを開発するプラットフォームとして Python を選択しましょう。サービスを見つけるためのモデルは設計されているので (2022 年 3 月の記事を参照)、このモデルをコードと構成に変換するだけです。
Python は、約 30 年前から存在する汎用プログラミング言語です。初期の段階では、これは自動化スクリプトの主な選択肢でした。しかし、DjangoやFlaskといったフレームワークの登場により人気が高まり、エンタープライズアプリケーション開発などさまざまな分野で利用されるようになりました。データ サイエンスと機械学習によりその成長がさらに促進され、Python は現在、トップ 3 プログラミング言語の 1 つとなっています。
多くの人は、Python の成功はコーディングの容易さによるものだと考えています。これは理由の一部にすぎません。小さなスクリプトを開発することが目的である限り、Python は本当に楽しめるおもちゃのようなものです。ただし、本格的な大規模アプリケーション開発の領域に入ると、多くのifとelseに対処する必要があります。 Python は他のプラットフォームと同じくらい良くても悪くても変わります。たとえば、オブジェクト指向のアプローチを採用してください。多くの Python 開発者は、Python がクラスや継承などをサポートしていることさえ知らないかもしれません。 Python は本格的なオブジェクト指向開発をサポートしていますが、Python 独自の方法で、Python 的です。調べてみましょう!
AddServiceデータを MySQL データベースに保存することにより、システムにユーザーを追加します。FindService目標は、ユーザー名でユーザーを検索するための REST API を提供することです。ドメイン モデルを図 1 に示します。これは主に、UserエンティティのName、PhoneNumber、などのいくつかの値オブジェクトで構成されます。ユーザーリポジトリ。
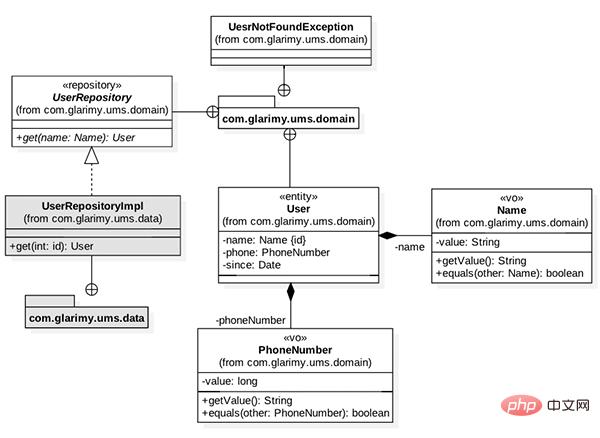
図 1: サービスを見つけるためのドメイン モデル
名前から始めましょう。これは値オブジェクトであるため、作成時に検証され、不変のままでなければなりません。基本的な構造は次のとおりです。
class Name:value: strdef __post_init__(self):if self.value is None or len(self.value.strip()) < 8 or len(self.value.strip()) > 32:raise ValueError("Invalid Name")
ご覧のとおり、Nameには文字列型の値が含まれています。これは初期化後の一環として検証されます。
Python 3.7 提供了@dataclass装饰器,它提供了许多开箱即用的数据承载类的功能,如构造函数、比较运算符等。如下是装饰后的Name类:
from dataclasses import dataclass@dataclassclass Name:value: strdef __post_init__(self):if self.value is None or len(self.value.strip()) < 8 or len(self.value.strip()) > 32:raise ValueError("Invalid Name")
以下代码可以创建一个Name对象:
name = Name("Krishna")
value属性可以按照如下方式读取或写入:
name.value = "Mohan"print(name.value)
可以很容易地与另一个Name对象比较,如下所示:
other = Name("Mohan")if name == other:print("same")
如你所见,对象比较的是值而不是引用。这一切都是开箱即用的。我们还可以通过冻结对象使对象不可变。这是Name值对象的最终版本:
from dataclasses import dataclass@dataclass(frozen=True)class Name:value: strdef __post_init__(self):if self.value is None or len(self.value.strip()) < 8 or len(self.value.strip()) > 32:raise ValueError("Invalid Name")
PhoneNumber也遵循类似的方法,因为它也是一个值对象:
@dataclass(frozen=True)class PhoneNumber:value: intdef __post_init__(self):if self.value < 9000000000:raise ValueError("Invalid Phone Number")
User类是一个实体,不是一个值对象。换句话说,User是可变的。以下是结构:
from dataclasses import dataclassimport datetime@dataclassclass User:_name: Name_phone: PhoneNumber_since: datetime.datetimedef __post_init__(self):if self._name is None or self._phone is None:raise ValueError("Invalid user")if self._since is None:self.since = datetime.datetime.now()
你能观察到User并没有冻结,因为我们希望它是可变的。但是,我们不希望所有属性都是可变的。标识字段如_name和_since是希望不会修改的。那么,这如何做到呢?
Python3 提供了所谓的描述符协议,它会帮助我们正确定义 getter 和 setter。让我们使用@property装饰器将 getter 添加到User的所有三个字段中。
@propertydef name(self) -> Name:return self._name@propertydef phone(self) -> PhoneNumber:return self._phone@propertydef since(self) -> datetime.datetime:return self._since
phone字段的 setter 可以使用@<字段>.setter来装饰:
@phone.setterdef phone(self, phone: PhoneNumber) -> None:if phone is None:raise ValueError("Invalid phone")self._phone = phone
通过重写__str__()函数,也可以为User提供一个简单的打印方法:
def __str__(self):return self.name.value + " [" + str(self.phone.value) + "] since " + str(self.since)
这样,域模型的实体和值对象就准备好了。创建异常类如下所示:
class UserNotFoundException(Exception):pass
域模型现在只剩下UserRepository了。Python 提供了一个名为abc的有用模块来创建抽象方法和抽象类。因为UserRepository只是一个接口,所以我们可以使用abc模块。
任何继承自abc.ABC的类都将变为抽象类,任何带有@abc.abstractmethod装饰器的函数都会变为一个抽象函数。下面是UserRepository的结构:
from abc import ABC, abstractmethodclass UserRepository(ABC):@abstractmethoddef fetch(self, name:Name) -> User:pass
UserRepository遵循仓储模式。换句话说,它在User实体上提供适当的 CRUD 操作,而不会暴露底层数据存储语义。在本例中,我们只需要fetch()操作,因为FindService只查找用户。
因为UserRepository是一个抽象类,我们不能从抽象类创建实例对象。创建对象必须依赖于一个具体类实现这个抽象类。数据层UserRepositoryImpl提供了UserRepository的具体实现:
class UserRepositoryImpl(UserRepository):def fetch(self, name:Name) -> User:pass
由于AddService将用户数据存储在一个 MySQL 数据库中,因此UserRepositoryImpl也必须连接到相同的数据库去检索数据。下面是连接到数据库的代码。注意,我们正在使用 MySQL 的连接库。
from mysql.connector import connect, Errorclass UserRepositoryImpl(UserRepository):def fetch(self, name:Name) -> User:try:with connect(host="mysqldb",user="root",password="admin",database="glarimy",) as connection:with connection.cursor() as cursor:cursor.execute("SELECT * FROM ums_users where name=%s", (name.value,))row = cursor.fetchone()if cursor.rowcount == -1:raise UserNotFoundException()else:return User(Name(row[0]), PhoneNumber(row[1]), row[2])except Error as e:raise e
在上面的片段中,我们使用用户root/ 密码admin连接到一个名为mysqldb的数据库服务器,使用名为glarimy的数据库(模式)。在演示代码中是可以包含这些信息的,但在生产中不建议这么做,因为这会暴露敏感信息。
fetch()操作的逻辑非常直观,它对ums_users表执行 SELECT 查询。回想一下,AddService正在将用户数据写入同一个表中。如果 SELECT 查询没有返回记录,fetch()函数将抛出UserNotFoundException异常。否则,它会从记录中构造User实体并将其返回给调用者。这没有什么特殊的。
最终,我们需要创建应用层。此模型如图 2 所示。它只包含两个类:控制器和一个 DTO。
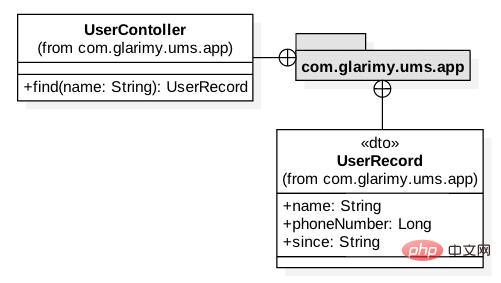
图 2: 添加服务的应用层
众所周知,一个 DTO 只是一个没有任何业务逻辑的数据容器。它主要用于在FindService和外部之间传输数据。我们只是提供了在 REST 层中将UserRecord转换为字典以便用于 JSON 传输:
class UserRecord:def toJSON(self):return {"name": self.name,"phone": self.phone,"since": self.since}
控制器的工作是将 DTO 转换为用于域服务的域对象,反之亦然。可以从find()操作中观察到这一点。
class UserController:def __init__(self):self._repo = UserRepositoryImpl()def find(self, name: str):try:user: User = self._repo.fetch(Name(name))record: UserRecord = UserRecord()record.name = user.name.valuerecord.phone = user.phone.valuerecord.since = user.sincereturn recordexcept UserNotFoundException as e:return None
find()操作接收一个字符串作为用户名,然后将其转换为Name对象,并调用UserRepository获取相应的User对象。如果找到了,则使用检索到的User`` 对象创建UserRecord`。回想一下,将域对象转换为 DTO 是很有必要的,这样可以对外部服务隐藏域模型。
UserController不需要有多个实例,它也可以是单例的。通过重写__new__,可以将其建模为一个单例。
class UserController:def __new__(self):if not hasattr(self, ‘instance’):self.instance = super().__new__(self)return self.instancedef __init__(self):self._repo = UserRepositoryImpl()def find(self, name: str):try:user: User = self._repo.fetch(Name(name))record: UserRecord = UserRecord()record.name = user.name.getValue()record.phone = user.phone.getValue()record.since = user.sincereturn recordexcept UserNotFoundException as e:return None
我们已经完全实现了FindService的模型,剩下的唯一任务是将其作为 REST 服务公开。
FindService只提供一个 API,那就是通过用户名查找用户。显然 URI 如下所示:
GET /user/{name}
此 API 希望根据提供的用户名查找用户,并以 JSON 格式返回用户的电话号码等详细信息。如果没有找到用户,API 将返回一个 404 状态码。
我们可以使用 Flask 框架来构建 REST API,它最初的目的是使用 Python 开发 Web 应用程序。除了 HTML 视图,它还进一步扩展到支持 REST 视图。我们选择这个框架是因为它足够简单。 创建一个 Flask 应用程序:
from flask import Flaskapp = Flask(__name__)
然后为 Flask 应用程序定义路由,就像函数一样简单:
@app.route('/user/')def get(name):pass
注意@app.route映射到 API/user/,与之对应的函数的get()。
如你所见,每次用户访问 API 如http://server:port/user/Krishna时,都将调用这个get()函数。Flask 足够智能,可以从 URL 中提取Krishna作为用户名,并将其传递给get()函数。
get()函数很简单。它要求控制器找到该用户,并将其与通常的 HTTP 头一起打包为 JSON 格式后返回。如果控制器返回None,则get()函数返回合适的 HTTP 状态码。
from flask import jsonify, abortcontroller = UserController()record = controller.find(name)if record is None:abort(404)else:resp = jsonify(record.toJSON())resp.status_code = 200return resp
最后,我们需要 Flask 应用程序提供服务,可以使用waitress服务:
from waitress import serveserve(app, host="0.0.0.0", port=8080)
在上面的片段中,应用程序在本地主机的 8080 端口上提供服务。最终代码如下所示:
from flask import Flask, jsonify, abortfrom waitress import serveapp = Flask(__name__)@app.route('/user/')def get(name):controller = UserController()record = controller.find(name)if record is None:abort(404)else:resp = jsonify(record.toJSON())resp.status_code = 200return respserve(app, host="0.0.0.0", port=8080)
FindService的代码已经准备完毕。除了 REST API 之外,它还有域模型、数据层和应用程序层。下一步是构建此服务,将其容器化,然后部署到 Kubernetes 上。此过程与部署其他服务妹有任何区别,但有一些 Python 特有的步骤。
在继续前进之前,让我们来看下文件夹和文件结构:
+ ums-find-service+ ums- domain.py- data.py- app.py- Dockerfile- requirements.txt- kube-find-deployment.yml
如你所见,整个工作文件夹都位于ums-find-service下,它包含了ums文件夹中的代码和一些配置文件,例如Dockerfile、requirements.txt和kube-find-deployment.yml。
domain.py包含域模型,data.py包含UserRepositoryImpl,app.py包含剩余代码。我们已经阅读过代码了,现在我们来看看配置文件。
第一个是requirements.txt,它声明了 Python 系统需要下载和安装的外部依赖项。我们需要用查找服务中用到的每个外部 Python 模块来填充它。如你所见,我们使用了 MySQL 连接器、Flask 和 Waitress 模块。因此,下面是requirements.txt的内容。
Flask==2.1.1Flask_RESTfulmysql-connector-pythonwaitress
第二步是在Dockerfile中声明 Docker 相关的清单,如下:
FROM python:3.8-slim-busterWORKDIR /umsADD ums /umsADD requirements.txt requirements.txtRUN pip3 install -r requirements.txtEXPOSE 8080ENTRYPOINT ["python"]CMD ["/ums/app.py"]
总的来说,我们使用 Python 3.8 作为基线,除了移动requirements.txt之外,我们还将代码从ums文件夹移动到 Docker 容器中对应的文件夹中。然后,我们指示容器运行pip3 install命令安装对应模块。最后,我们向外暴露 8080 端口(因为 waitress 运行在此端口上)。
为了运行此服务,我们指示容器使用使用以下命令:
python /ums/app.py
一旦Dockerfile准备完成,在ums-find-service文件夹中运行以下命令,创建 Docker 镜像:
docker build -t glarimy/ums-find-service
它会创建 Docker 镜像,可以使用以下命令查找镜像:
docker images
尝试将镜像推送到 Docker Hub,你也可以登录到 Docker。
docker logindocker push glarimy/ums-find-service
最后一步是为 Kubernetes 部署构建清单。
在之前的文章中,我们已经介绍了如何建立 Kubernetes 集群、部署和使用服务的方法。我假设仍然使用之前文章中的清单文件来部署添加服务、MySQL、Kafka 和 Zookeeper。我们只需要将以下内容添加到kube-find-deployment.yml文件中:
apiVersion: apps/v1kind: Deploymentmetadata:name: ums-find-servicelabels:app: ums-find-servicespec:replicas: 3selector:matchLabels:app: ums-find-servicetemplate:metadata:labels:app: ums-find-servicespec:containers:- name: ums-find-serviceimage: glarimy/ums-find-serviceports:- containerPort: 8080---apiVersion: v1kind: Servicemetadata:name: ums-find-servicelabels:name: ums-find-servicespec:type: LoadBalancerports:- port: 8080selector:app: ums-find-service
上面清单文件的第一部分声明了glarimy/ums-find-service镜像的FindService,它包含三个副本。它还暴露 8080 端口。清单的后半部分声明了一个 Kubernetes 服务作为FindService部署的前端。请记住,在之前文章中,mysqldb 服务已经是上述清单的一部分了。
运行以下命令在 Kubernetes 集群上部署清单文件:
kubectl create -f kube-find-deployment.yml
部署完成后,可以使用以下命令验证容器组和服务:
kubectl get services
输出如图 3 所示:

图 3: Kubernetes 服务
它会列出集群上运行的所有服务。注意查找服务的外部 IP,使用curl调用此服务:
curl http://10.98.45.187:8080/user/KrishnaMohan
注意:10.98.45.187 对应查找服务,如图 3 所示。
如果我们使用AddService创建一个名为KrishnaMohan的用户,那么上面的curl命令看起来如图 4 所示:

图 4: 查找服务
用户管理系统(UMS)的体系结构包含AddService和FindService,以及存储和消息传递所需的后端服务,如图 5 所示。可以看到终端用户使用ums-add-service的 IP 地址添加新用户,使用ums-find-service的 IP 地址查找已有用户。每个 Kubernetes 服务都由三个对应容器的节点支持。还要注意:同样的 mysqldb 服务用于存储和检索用户数据。
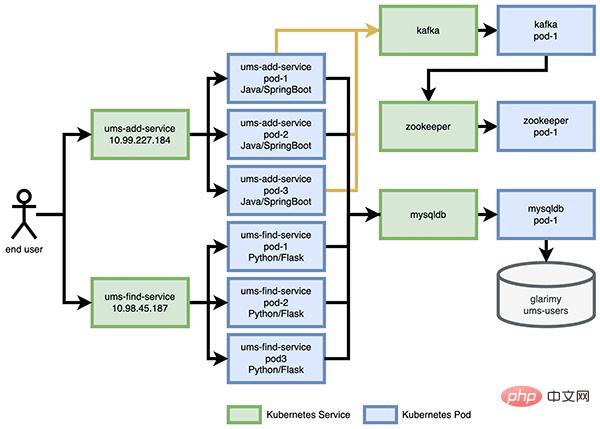
图 5: UMS 的添加服务和查找服务
UMS 系统还包含两个服务:SearchService和JournalService。在本系列的下一部分中,我们将在 Node 平台上设计这些服务,并将它们部署到同一个 Kubernetes 集群,以演示多语言微服务架构的真正魅力。最后,我们将观察一些与微服务相关的设计模式。
以上がFlask を使用して Kubernetes 上に Python マイクロサービスを構築するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



