


この記事では、人気の機械学習プロジェクトであるテキスト ジェネレーターを紹介します。テキスト ジェネレーターを構築する方法と、より高速な予測モデルを実現するためのマルコフ連鎖の実装方法を学びます。

テキスト生成は、あらゆる業界、特にモバイル、アプリ、データ サイエンスの分野で人気があります。報道機関でも、執筆プロセスを支援するためにテキスト生成を使用しています。
日常生活では、いくつかのテキスト生成テクノロジに触れることがあります。テキスト補完、検索候補、スマート作成、チャット ロボットなどはすべてアプリケーションの例です。
この記事ではマルコフを使用します。テキストジェネレーターを構築するためのチェーン。これは、チェーンの前の文字を取得し、シーケンス内の次の文字を生成する文字ベースのモデルになります。
例の単語を使用してプログラムをトレーニングすることにより、テキスト ジェネレーターは一般的な文字の順序パターンを学習します。次に、テキスト ジェネレーターはこれらのパターンを不完全な単語である入力に適用し、単語を完成させる可能性が最も高い文字を出力します。
#テキスト生成は、以前に観察された言語パターンに基づいて次の文字を予測して生成する自然言語処理の分野です。
機械学習の前に、NLP は英語のすべての単語を含むテーブルを作成し、渡された文字列を既存の単語と照合することでテキスト生成を実行していました。このアプローチには 2 つの問題があります。
機械学習と深層学習の出現により、ジェネレーターがこれまでに遭遇したことのない単語を完成させることができるため、実行時間が大幅に短縮され、NLP の汎用性が向上しました。 NLP は、必要に応じて単語、フレーズ、文を予測するように拡張できます!
このプロジェクトでは、マルコフ連鎖のみを使用して実行します。マルコフ プロセスは、書き言葉や複雑な分布からのサンプルのシミュレーションを含む多くの自然言語処理プロジェクトの基礎です。
マルコフ プロセスは非常に強力であるため、サンプル ドキュメントだけを使用して、一見本物のように見えるテキストを生成することができます。
マルコフ連鎖は、各イベントの確率が前のイベントの状態に依存する一連のイベントをモデル化する確率過程です。モデルには有限の状態セットがあり、ある状態から別の状態に移行する条件付き確率は固定されています。
各遷移の確率は、イベントの履歴全体ではなく、モデルの以前の状態にのみ依存します。
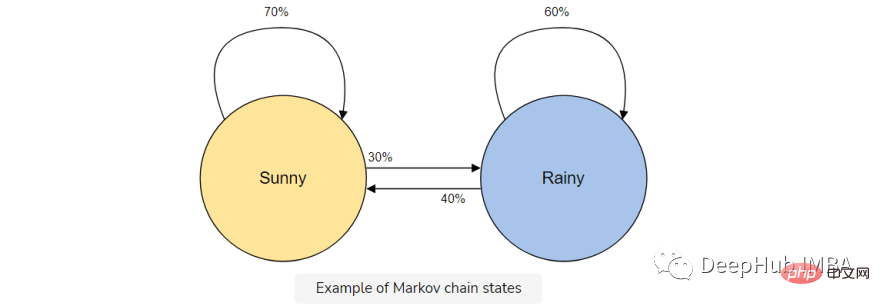
たとえば、天気を予測するためにマルコフ連鎖モデルを構築するとします。
このモデルには、晴れまたは雨の 2 つの状態があります。今日晴れた日であれば、明日は晴れる可能性が高くなります (70%)。雨も同様で、一度雨が降った場合は、さらに雨が降り続ける可能性があります。
しかし、天候によって状態が変化する可能性 (30%) があるため、それもマルコフ連鎖モデルに含めます。
マルコフ連鎖は、前の文字のみを使用して次の文字を予測するため、テキスト ジェネレーターに最適なモデルです。マルコフ連鎖を使用する利点は、正確で、必要なメモリが少なく (前の状態が 1 つだけ保存される)、実行が速いことです。
テキストジェネレーターは6つのステップで完成します:

まず、トレーニング コーパス内の各文字状態の出現を記録するテーブルを作成します。トレーニング コーパスから最後の「K」文字と「K1」文字を保存し、ルックアップ テーブルに保存します。
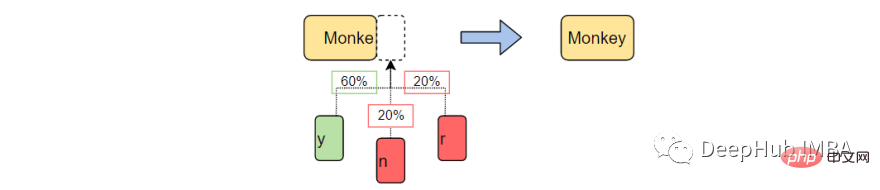
たとえば、トレーニング コーパスに「the man was, they, then, the, the」が含まれていると想像してください。この場合、単語の出現数は次のようになります。
ルックアップ テーブルの結果は次のとおりです:

上記の例では、K = 3 とします。これは、一度に 3 文字が考慮され、次の文字 (K 1) が出力として使用されることを意味します。キャラクター。最初の the の後に単語がないため、単語 (X) を上記のルックアップ テーブル内の文字として扱い、出力文字 (Y) を単一のスペース (" ") として扱います。また、このシーケンスがデータ セット内に出現する回数 (この場合は 3 回) も計算されます。
これにより、コーパス内の各単語のデータが生成されます。つまり、考えられるすべての X と Y のペアが生成されます。
コード内でルックアップ テーブルを生成する方法は次のとおりです:
def generateTable(data,k=4):
T = {}
for i in range(len(data)-k):
X = data[i:i+k]
Y = data[i+k]
#print("X %s and Y %s "%(X,Y))
if T.get(X) is None:
T[X] = {}
T[X][Y] = 1
else:
if T[X].get(Y) is None:
T[X][Y] = 1
else:
T[X][Y] += 1
return T
T = generateTable("hello hello helli")
print(T)
#{'llo ': {'h': 2}, 'ello': {' ': 2}, 'o he': {'l': 2}, 'lo h': {'e': 2}, 'hell': {'i': 1, 'o': 2}, ' hel': {'l': 2}}コードの簡単な説明:
3 行目で、X とその値を格納する辞書が作成されます。対応する Y 値と周波数値。行 9 から 17 は、X と Y の出現をチェックします。ルックアップ辞書にすでに X と Y のペアがある場合は、それを 1 だけ増やします。
このテーブルと出現回数を取得したら、特定の x の出現後に Y が出現する確率を取得できます。式は次のとおりです:
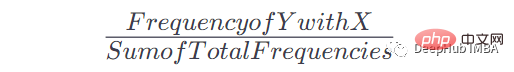
たとえば、X = the、Y = n の場合、式は次のようになります:
X =the Y = n の場合頻度: 2、テーブル内の合計頻度: 8、したがって: P = 2/8= 0.125= 12.5%
この式を適用してルックアップ テーブルを使用可能な確率を持つマルコフ連鎖に変換する方法を次に示します。
def convertFreqIntoProb(T):
for kx in T.keys():
s = float(sum(T[kx].values()))
for k in T[kx].keys():
T[kx][k] = T[kx][k]/s
return T
T = convertFreqIntoProb(T)
print(T)
#{'llo ': {'h': 1.0}, 'ello': {' ': 1.0}, 'o he': {'l': 1.0}, 'lo h': {'e': 1.0}, 'hell': {'i': 0.3333333333333333, 'o': 0.6666666666666666}, ' hel': {'l': 1.0}}簡単な説明:
特定のキーの頻度値を加算し、このキーの各頻度値を加算した値で除算して確率を取得します。
次に実際のトレーニング コーパスがロードされます。任意の長いテキスト (.txt) ドキュメントを使用できます。
わかりやすくするために、モデルを教えるのに十分な語彙を提供するために政治的演説が使用されます。
text_path = "train_corpus.txt"
def load_text(filename):
with open(filename,encoding='utf8') as f:
return f.read().lower()
text = load_text(text_path)
print('Loaded the dataset.')このデータ セットは、サンプル プロジェクトがかなり正確な予測を行うのに十分なイベントを提供できます。すべての機械学習と同様、トレーニング コーパスが大きいほど、より正確な予測が生成されます。
マルコフ連鎖を構築し、確率を各文字に関連付けましょう。ここでは、手順 1 と 2 で作成したgenerateTable() 関数とconvertFreqIntoProb() 関数を使用してマルコフ モデルを構築します。
def MarkovChain(text,k=4): T = generateTable(text,k) T = convertFreqIntoProb(T) return T model = MarkovChain(text)
1 行目では、マルコフ モデルを生成するメソッドが作成されます。このメソッドは、テキスト コーパスと K 値を受け入れます。K 値は、マルコフ モデルに K 文字を考慮して次の文字を予測するように指示する値です。 2 行目、ルックアップ テーブルは、前のセクションで作成したメソッドgenerateTable() にテキスト コーパスと K を提供することによって生成されます。 3 行目では、convertFreqIntoProb() メソッドを使用して周波数を確率値に変換します。このメソッドも前のレッスンで作成しました。
未完成の単語 (ctx)、ステップ 4 のマルコフ連鎖モデル (モデル)、および単語を形成するためのベースを使用するサンプリング関数を作成します文字数(k)。
この関数を使用して、渡されたコンテキストをサンプリングし、次に考えられる文字を返し、それが正しい文字である確率を判断します。
import numpy as np
def sample_next(ctx,model,k):
ctx = ctx[-k:]
if model.get(ctx) is None:
return " "
possible_Chars = list(model[ctx].keys())
possible_values = list(model[ctx].values())
print(possible_Chars)
print(possible_values)
return np.random.choice(possible_Chars,p=possible_values)
sample_next("commo",model,4)
#['n']
#[1.0]コードの説明:
関数sample_nextは、ctx、model、k値の3つのパラメータを受け取ります。
ctx は、新しいテキストを生成するために使用されるテキストです。ただし、ここでは、ctx の最後の K 文字のみが、シーケンス内の次の文字を予測するためにモデルによって使用されます。たとえば、common、K = 4 を渡します。マルコフ モデルは前の履歴のみを使用するため、モデルが次の文字を生成するために使用するテキストは ommo です。
行 9 と 10 には、使用可能な文字とその確率値が出力されます。これらの文字はモデルにも存在するためです。次に予測される文字は n であり、確率は 1.0 です。 12 行目で次の文字
を生成した後は、commo という単語がより一般的になる可能性が高いため、上で説明した確率値に基づいて文字を返します。
最後に、上記の関数をすべて組み合わせてテキストを生成します。
def generateText(starting_sent,k=4,maxLen=1000):
sentence = starting_sent
ctx = starting_sent[-k:]
for ix in range(maxLen):
next_prediction = sample_next(ctx,model,k)
sentence += next_prediction
ctx = sentence[-k:]
return sentence
print("Function Created Successfully!")
text = generateText("dear",k=4,maxLen=2000)
print(text)結果は次のとおりです:
dear country brought new consciousness. i heartily great service of their lives, our country, many of tricoloring a color flag on their lives independence today.my devoted to be oppression of independence.these day the obc common many country, millions of oppression of massacrifice of indian whom everest. my dear country is not in the sevents went was demanding and nights by plowing in the message of the country is crossed, oppressed, women, to overcrowding for years of the south, it is like the ashok chakra of constitutional states crossed, deprived, oppressions of freedom, i bow my heart to proud of our country.my dear country, millions under to be a hundred years of the south, it is going their heroes.
上記の関数は、生成されるテキストの開始単語、K の値、および必要なテキストの最大文字長という 3 つのパラメーターを受け取ります。コードを実行すると、「dear」で始まる 2000 文字のテキストが生成されます。
このスピーチはあまり意味をなさないかもしれませんが、言葉は完全であり、よく知られた言葉のパターンを模倣していることがよくあります。
これは、単純なテキスト生成プロジェクトです。このプロジェクトを使用して、自然言語処理とマルコフ連鎖が実際にどのように機能するかを学び、深層学習の取り組みを続けるときに使用できます。
この記事はマルコフ連鎖による実験プロジェクトを紹介するだけであり、実際のアプリケーションでは何の役にも立ちませんので、より良いテキスト生成効果を得たい場合は、GPT-3 などのツールを学習してください。 。
以上がマルコフ連鎖を使用したテキストジェネレーターの構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



