


過去 70 年間に「三栄、二栄」を経験した後、基盤となるチップ、コンピューティング能力、データ、その他のインフラストラクチャーの改善と進歩により、世界の AI 業界は徐々に計算知能から知覚知能、コグニティブへと移行しつつあります。 「チップ、コンピューティング設備、AI フレームワークとアルゴリズム モデル、アプリケーション シナリオ」の産業分業とコラボレーション システム。 2019年以降、AI大型モデルは問題解決を一般化する能力を大幅に向上させ、「大型モデルと小型モデル」が徐々に業界の主流のテクノロジールートとなり、世界のAI産業の発展の全体的な加速を推進し、 「チップコンピューティングパワーインフラストラクチャAIフレームワークとアルゴリズム」「ライブラリアプリケーションシナリオ」安定した産業バリューチェーン構造。
この号のインテリジェントな社内参考資料として、人工知能業界の現状を解釈するための CITIC Securities のレポート「大型モデルが AI を総合的に加速させ、業界の黄金の 10 年投資サイクルが始まる」をお勧めします。産業発展の中核問題。出典: CITIC Securities
「人工知能」の概念と理論が 1956 年に初めて提案されて以来、AI 産業の発展&テクノロジーは主に3つの主要な発展を経験しました。
1 ) 20 世紀 50 年 ~20 世紀 70 時代: コンピューティング能力、データ量などに左右されるが、依然として理論上の レベルにとどまる。 1956 年のダートマス会議をきっかけに、世界初の人工知能の波が到来し、学界全体に楽観的な雰囲気が浸透し、強化と呼ばれる手法をはじめとするアルゴリズムの分野で世界に誇る発明が数多く生まれました。プロトタイプの形では、強化学習は Google の AlphaGo アルゴリズムの中核となるアイデアです。 1970 年代初頭、AI はボトルネックに直面しました。人々は、論理証明者、パーセプトロン、強化学習などは非常に単純で目的が狭いタスクしか実行できず、その範囲をわずかに超えたタスクは処理できないことに気づきました。当時のコンピューターの限られたメモリと処理速度では、実際の AI の問題を解決するには十分ではありませんでした。これらの計算の複雑さは指数関数的に増加し、不可能な計算タスクになります。
2 ) 20 世紀 80 年 ~20 世紀 90 時代: エキスパートシステムは人工知能の最初の商用化の試みであり、ハードウェアコストが高く、適用可能なシナリオが限られており、人工知能のさらなる開発が制限されています。市場。 1980年代、エキスパートシステムAIプログラムが世界中の企業で採用され始め、「知識処理」がAI研究の主流となった。エキスパート システムの機能は、そこに保存されている専門知識に由来しており、知識ベース システムと知識エンジニアリングが 1980 年代の AI 研究の主な方向性になりました。しかし、エキスパート システムの実用性は特定の状況に限定されており、エキスパート システムに対する人々の熱意はすぐに大きな失望に変わりました。一方、1987 年から 1993 年にかけて登場した最新の PC は、エキスパート システムで使用される Symbolics や Lisp などのマシンに比べてはるかに安価でした。最新の PC と比較すると、エキスパート システムは時代遅れであり、保守が非常に難しいと考えられています。その結果、政府の資金は減少し始め、再び冬がやって来ました。
3) 2015 YTD: 完全な産業チェーンの分業と協力システムを徐々に形成します。 人工知能の 3 番目の画期的な出来事は、2016 年 3 月に発生しました。Google DeepMind が開発した AlphaGo が、人間と機械の戦いで韓国のプロ囲碁棋士イ・セドル九段を破りました。その後、人工知能は国民に広く知られるようになり、さまざまな分野で熱意が高まりました。この事件により、DNN ニューラル ネットワーク アルゴリズムに基づいた統計的分類ディープ ラーニング モデルが確立されました。このタイプのモデルは、以前よりも汎用的であり、さまざまな特徴量抽出を通じてさまざまなアプリケーション シナリオに適用できます。同時に、2010 年から 2015 年にかけてのモバイル インターネットの普及により、ディープ ラーニング アルゴリズムに前例のないデータ栄養がもたらされました。データ量の増加、計算能力の向上、新しい機械学習アルゴリズムの出現により、人工知能は大きな調整を受け始めています。人工知能の研究分野も拡大しており、エキスパートシステム、機械学習、進化的コンピューティング、ファジーロジック、コンピュータビジョン、自然言語処理、レコメンデーションシステムなどが含まれます。ディープラーニングの発展により、人工知能は新たな開発の頂点に達しました。
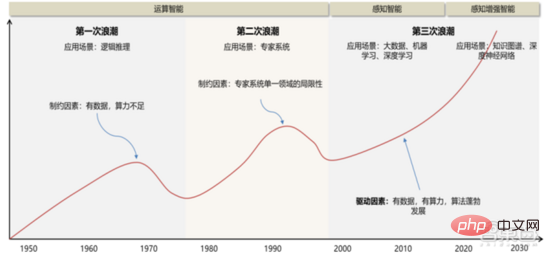 ▲ 人工知能開発の第 3 の波
▲ 人工知能開発の第 3 の波
#人工知能の第 3 波は、DNN など、商用化可能な多数のシナリオをもたらします。アルゴリズム 優れたパフォーマンスにより、音声認識と画像認識が可能になり、セキュリティと教育の分野で最初の成功したビジネス ケースに貢献しました。近年、ニューラルネットワークアルゴリズムをベースとしたTransformerなどのアルゴリズムの開発により、NLP(自然言語処理)の商用化が議題となっており、今後3~5年で商用化シナリオが成熟すると予想されています。
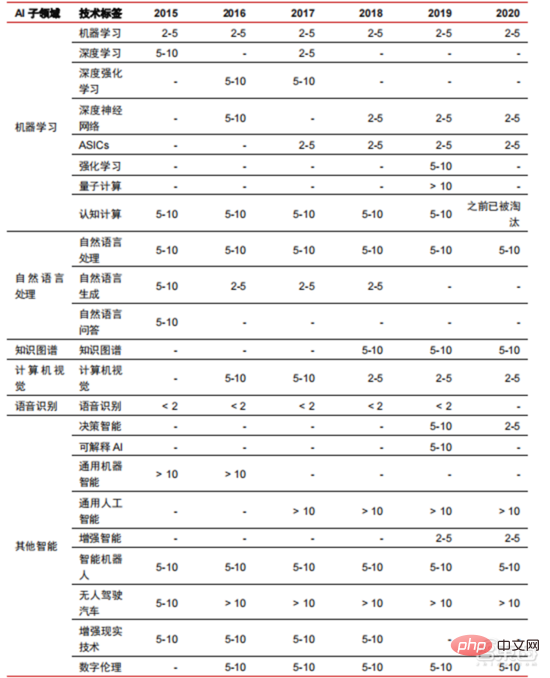
▲人工知能技術の産業化に必要な年数
過去 5 ~ 6 年の経験 発展に伴い、世界の AI 産業は分業と協力、完全な産業チェーン構造を徐々に形成しており、いくつかの分野で典型的なアプリケーション シナリオを形成し始めています。
チップは AI# の卓越した高さです## ### 業界# ##。このラウンドの人工知能産業の繁栄は、AI のコンピューティング能力が大幅に向上し、ディープ ラーニングと多層ニューラル ネットワーク アルゴリズムが可能になったことによるものです。 人 人工知能はさまざまな業界に急速に浸透しており、データは膨大に増加しており、その結果、非常に複雑なアルゴリズム モデル、異種の処理オブジェクト、および高いコンピューティング パフォーマンス要件が生じています。したがって、人工知能ディープラーニングには非常に強力な並列処理能力が必要です。AI チップは、CPU と比較して、データ処理のための論理演算ユニット (ALU) が多く、大量のデータの並列処理に適しています。主なタイプには、グラフィック プロセッサ (GPU)、フィールドプログラマブルゲートアレイ(FPGA)、特定用途向け集積回路(ASIC)など使用シナリオの観点から見ると、関連するハードウェアには、クラウド側の推論チップ、クラウド側のテスト チップ、端末処理チップ、IP コアなどが含まれます。クラウドの「トレーニング」または「学習」の部分では、NVIDIA GPU が強い競争優位性を持っており、Google TPU も積極的に市場とアプリケーションを拡大しています。 FPGA と ASIC は、最終用途の「推論」アプリケーションで利点がある可能性があります。米国はGPUやFPGAの分野で強い優位性を持っており、NVIDIA、Xilinx、AMDなどの有力企業があり、GoogleやAmazonもAIチップの開発に積極的である。
▲さまざまな AI リンクでのチップの適用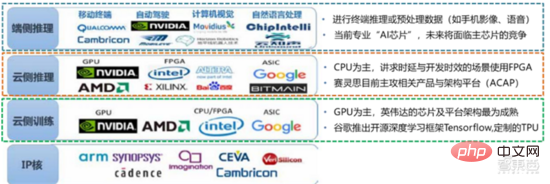
▲人工知能ニューラル ネットワーク アルゴリズム モデルの複雑さ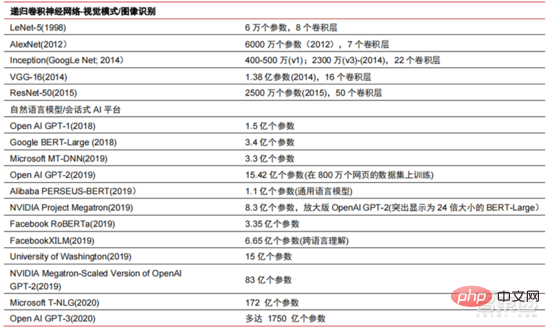
▲ チップ メーカーのレイアウト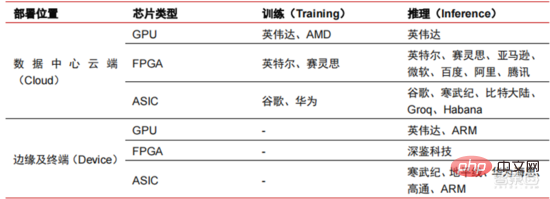
▲ エッジ コンピューティング チップ出荷数 (数百万、端末デバイス別) 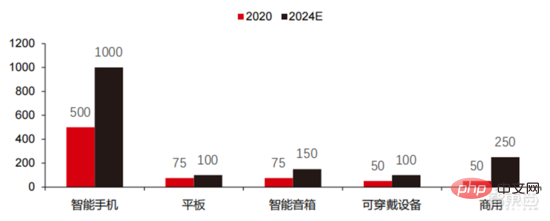
▲ 世界の人工知能チップ市場規模 ( 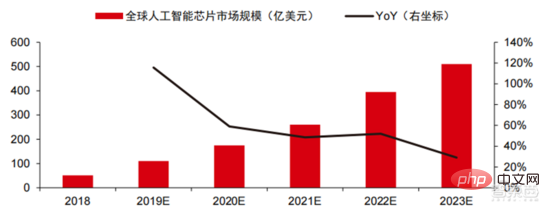
▲ GPU チップの主要企業と技術ロードマップ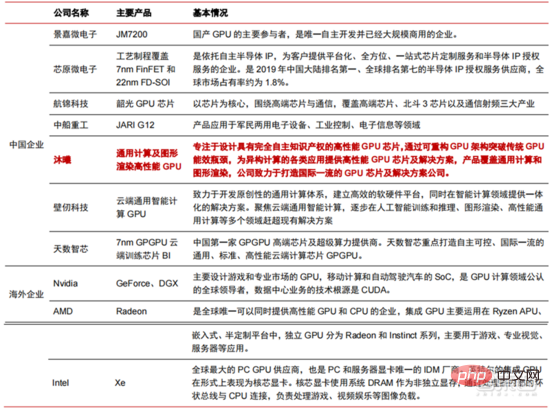
物理的な限界に近づくにつれて、コンピューティング能力の成長に関するムーアの法則は徐々に失効し、コンピューティング能力業界は多要素の包括的なイノベーションの段階に入ります。
。 これまで、コンピューティング電源は主にプロセスの縮小、つまり同じチップ内のトランジスタ スタックの数を増やしてコンピューティングのパフォーマンスを向上させることで改善されてきました。しかし、プロセスが物理的限界に近づき、コストが増加し続けると、ムーアの法則は徐々に無効になり、コンピューティングパワー業界はポストムーア時代に入り、複数の要素の包括的なイノベーションを通じてコンピューティングパワーの供給を改善する必要があります。現在、コンピューティング電源には、シングルチップ コンピューティング パワー、完全なマシン コンピューティング パワー、データ センター コンピューティング パワー、およびネットワーク コンピューティング パワーの 4 つのレベルがあり、さまざまなテクノロジーを通じて継続的に進化およびアップグレードされており、世界の多様なコンピューティング パワーの供給ニーズに応えています。スマートな時代。さらに、ソフトウェアとハードウェア システムの緊密な統合とアルゴリズムの最適化を通じてコンピューティング システムの全体的なパフォーマンスを向上させることも、コンピューティング パワー産業の進化にとって重要な方向性です。 計算能力の規模:
中国情報通信技術院が2021年に発表した「中国計算能力発展指数白書」によると、世界の計算能力の総規模は依然として2020年も成長傾向を維持し、総規模は前年比39%増の429EFlopsに達し、そのうち基本演算能力規模は313EFlops、インテリジェント演算能力規模は107EFlops、スーパーコンピューティング能力規模は9EFlopsとなった. インテリジェントなコンピューティング能力の割合が増加しました。我が国の計算能力の発展ペースは世界と同様であり、2020年に我が国の計算能力の総規模は135EFlopsに達し、世界の計算能力規模の39%を占め、55%という高い成長を達成した。 3年連続で40%を超える成長率を達成しています。
▲ 世界のコンピューティング能力規模の変化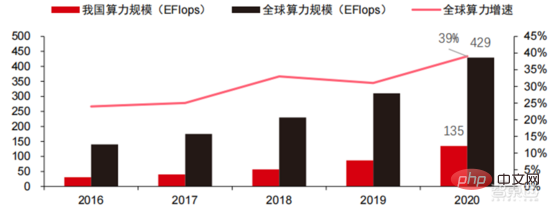
コンピューティング能力構造
: 私の国の発展状況は世界の発展状況と似ています。インテリジェント コンピューティング能力は急速に成長しており、その割合は 2016 年の 3% から 2020 年には 41% に増加しました。基本的なコンピューティング能力の割合は、2016 年の 95% から 2020 年の 57% に低下しました。下流の需要に牽引され、インテリジェント コンピューティング センターに代表される人工知能コンピューティング能力インフラストラクチャは急速に発展しました。同時に、将来の需要については、ファーウェイが2020年に発表した「ユビキタス・コンピューティング・パワー:インテリジェント社会の基礎」レポートによると、人工知能の普及に伴い、2030年までに人工知能の需要は2030年までに増加すると予想されています。知能計算能力はクアルコムチップ1,600億個に相当 Snapdragon 855にはAIチップが内蔵されており、これは2018年の約390倍、2020年の約120倍に相当します。
▲ 2030 年の人工知能コンピューティング電力需要 (EFlops) の推定値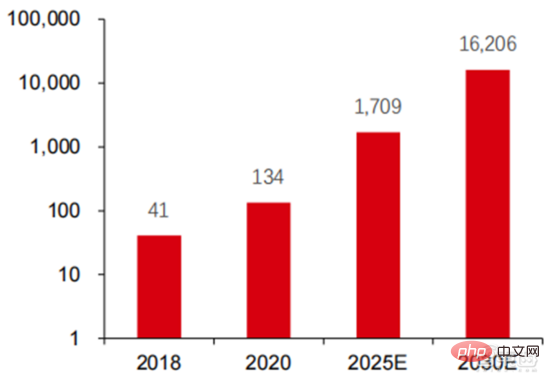
データ ストレージ: 非リレーショナル データベースであり、非リレーショナル データベースの保存と管理に使用されます。 -リレーショナル データベース 構造化データのデータ レイクの需要が爆発的に増加しています。
近年、世界のデータ量は爆発的な増加を示しています。IDC の統計によると、2019 年に世界で生成されたデータ量は 41ZB でした。過去 10 年間の CAGR は 50% 近くでした。世界のデータ量は、2025 年、2019 年から 2025 年までに 175ZB に達する可能性があります。今後も毎年 30% 近い複合成長率を維持し、データの 80% 以上がテキスト、画像、音声、データなどの非構造化データになるでしょう。処理が難しいビデオ。データ量 (特に非構造化データ) の急増により、リレーショナル データベースの弱点がますます顕著になり、データの幾何級数的な増加に直面して、伝統的に構造化データ用に設計されたリレーショナル データベースの垂直オーバーレイ データ拡張モデルを満たすことが困難になっています。非構造化データの保存と管理に使用される非リレーショナル データベースとデータ レイクは、その柔軟性と容易な拡張性により、市場のシェアを徐々に拡大しています。 IDC によると、Nosql データベースの世界市場規模は 2020 年に 56 億米ドルで、2020 年から 2025 年までの複合成長率は 27.6% となり、2025 年には 190 億米ドルに成長すると予想されています。同時にIDCによると、2020年の世界のデータレイク市場規模は62億米ドルで、2020年の市場規模成長率は34.4%でした。
▲ 世界のデータ量と前年比増加率 (ZB、%)
Tensorflow (業界)、 PyTorch (学界) が徐々に優位性を獲得します。 Google が立ち上げた Tensorflow が主流であり、Keras (Tensorflow2 は Keras モジュールを統合) や Facebook のオープンソース PyTorch などの他のオープンソース モジュールとともに、現在の AI 学習の主流のフレームワークを構成しています。 Google Brain は 2011 年の設立以来、科学研究や Google 製品開発のための大規模な深層学習応用研究を行っており、その初期の作品は TensorFlow の前身である DistBelief でした。 DistBelief は洗練されており、Google やその他の Alphabet 傘下企業の製品開発で広く使用されています。 2015 年 11 月、Google Brain は DistBelief に基づいて「第 2 世代機械学習システム」である TensorFlow の開発を完了し、コードをオープンソース化しました。 TensorFlow は、以前のバージョンと比較して、パフォーマンス、アーキテクチャの柔軟性、移植性が大幅に向上しています。
Tensorflow と Pytorch はオープンソース モジュールですが、深層学習フレームワークの巨大なモデルと複雑さのため、それらの修正と更新は基本的に Google によって完了され、その結果、Google と Facebook も Tensorflow とPyTorch: この方向性は、業界の人工知能の開発モデルを直接支配します。
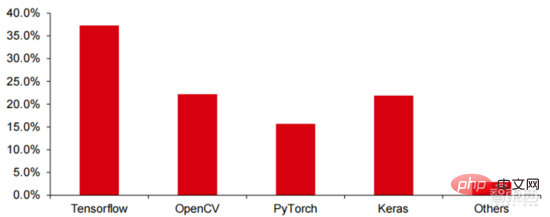
▲ 世界の商用人工知能フレームワーク市場シェア構造 (2021 年)
Microsoft は 2020 年に OpenAI に 10 億米ドルを投資し、GPT-3 言語モデルを取得しました独占的ライセンス。 GPT-3は、自然言語生成において現在最も成功しているアプリケーションで、「論文」を書くだけでなく「コードを自動生成する」こともでき、今年7月にリリースされて以来、業界では最も強力な人工知能言語モデルとみなされています。 Facebook は 2013 年には AI Research Institute を設立しました。FAIR 自体には AlphaGo や GPT-3 ほど有名なモデルやアプリケーションはありませんが、そのチームは Facebook 自体が興味を持っている分野 (コンピューター ビジョン、自然言語処理や会話型AIなど2021年、Googleは177本の論文をNeurIPS(現在、人工知能アルゴリズムに関する最高峰のジャーナル)に受理・掲載したが、Microsoftは116本の論文、DeepMindは81本の論文、Facebookは78本の論文、IBMは36本の論文、Amazonはわずか35本の論文しかなかった。
ディープ ラーニングはディープ ニューラル ネットワークに移行しつつあります。 機械学習は、多層非線形特徴学習と階層的特徴抽出を通じて画像、音声、その他のデータを予測するコンピューター アルゴリズムです。ディープラーニングは高度な機械学習であり、ディープ ニューラル ネットワーク (DNN: Deep Neural Networks) とも呼ばれます。さまざまなシナリオ (情報) でのトレーニングと推論のために、さまざまなニューラル ネットワークとトレーニング方法が確立されており、トレーニングは大量のデータ演繹を通じて各ニューロンの重みと伝達方向を最適化するプロセスです。畳み込みニューラル ネットワークでは、単一ピクセルと周囲の環境変数を考慮してデータ抽出量を簡素化し、ニューラル ネットワーク アルゴリズムの効率をさらに向上させることができます。
ニューラル ネットワーク アルゴリズムはビッグ データ処理の中核となっています。 AI は、大量のラベル付きデータを通じて深層学習を実行し、ニューラル ネットワークとモデルを最適化し、推論と意思決定のアプリケーション リンクを導入します。 1990 年代は機械学習とニューラル ネットワーク アルゴリズムが急速に台頭した時期であり、アルゴリズムはコンピューティング能力のサポートを受けて商業的に使用されました。 1990年代以降、AI技術の実用化分野としては、データマイニング、産業用ロボット、物流、音声認識、銀行業務用ソフトウェア、医療診断、検索エンジンなどが挙げられる。関連するアルゴリズムのフレームワークが、テクノロジー大手のレイアウトの焦点となっています。
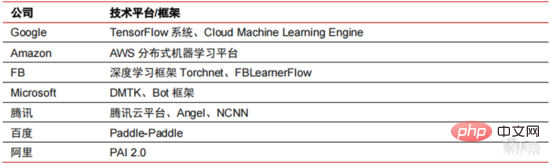
▲ 大手テクノロジー企業のアルゴリズム プラットフォーム フレームワーク
技術的な方向性では、コンピューター ビジョンと機械学習が主な技術研究開発です方向。 ARXIV データによると、理論研究の観点から、コンピューター ビジョンと機械学習の 2 つの分野が 2015 年から 2020 年にかけて急速に発展し、続いてロボット工学の分野が発展しました。 2020 年、ARXIV 上の AI 関連出版物のうち、コンピューター ビジョン分野の出版物は 11,000 件を超え、AI 関連出版物の数で第 1 位となりました。
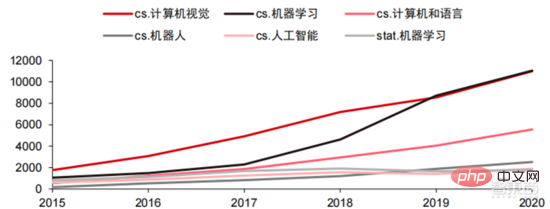
▲2015 年から 2020 年までの ARXIV 上の AI 関連出版物の数
過去 5 年間で、ニューラル ネットワーク アルゴリズム (主に CNN と DNN) が近年最も急速に成長している機械学習アルゴリズムであることがわかりました。コンピューター ビジョン、自然言語処理、その他の分野で優れたパフォーマンスを発揮するため、これは、人工知能アプリケーションの実装を加速し、コンピューター ビジョンと意思決定インテリジェンスの急速な成熟における重要な要素です。側面図からわかるように、標準 DNN 手法には、音声認識タスクにおいて従来の KNN、SVM、およびランダム フォレスト手法に比べて明らかな利点があります。
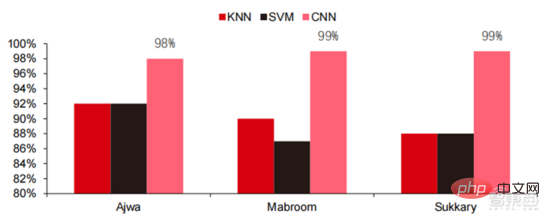
▲ 畳み込みアルゴリズムは、従来の画像処理の精度のボトルネックを打破し、初めて工業化に利用可能になりました。トレーニング コスト、ニューラル ネットワーク アルゴリズム 人工知能のトレーニング コストが大幅に削減されます。
ImageNet は、人工知能アルゴリズムのトレーニングに使用される 1,400 万枚を超える画像のデータセットです。スタンフォード大学 DAWNBench チームのテストによると、2020 年の最新の画像認識システムのトレーニング費用はわずか約 7.5 米ドルで、2017 年の 1,100 米ドルから 99% 以上減少しました。これは主にアルゴリズム設計の最適化、コストの削減によるものです。コンピューティング電力コスト、および大規模な AI トレーニング インフラストラクチャの進歩。システムのトレーニングが速くなればなるほど、システムの評価や新しいデータによる更新も速くなり、ImageNet システムのトレーニングがさらに高速化され、人工知能システムの開発と導入の生産性が向上します。トレーニング時間の分布を見ると、ニューラル ネットワーク アルゴリズムのトレーニングに必要な時間が全体的に短縮されています。
各期間のトレーニング時間の分布を分析すると、ここ数年でトレーニング時間が大幅に短縮され、トレーニング時間の分布がより集中していることがわかります。これは主にトレーニングの普及の恩恵を受けています。アクセラレータチップ。
▲ ImageNet トレーニング時間の分布 (分) 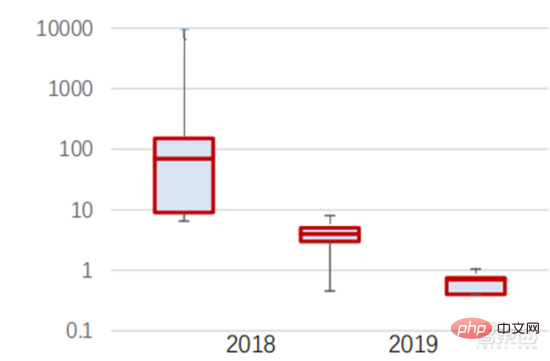
畳み込みニューラル ネットワークによって駆動され、コンピューター ビジョンの精度テストのスコアが大幅に向上しました。工業化段階にある。
コンピューター ビジョンの精度は、主に機械学習テクノロジーの応用により、過去 10 年間で大幅に進歩しました。トップ 1 精度テスト AI システムが画像に正しいラベルを割り当てる能力が高ければ高いほど、その予測 (考えられるすべてのラベルの中で) がターゲット ラベルとより一致します。追加のトレーニング データ (ソーシャル メディアからの写真など) を使用すると、2021 年 1 月のトップ 1 精度テストでは 10 回の試行あたり 1 回のエラーが発生しましたが、2012 年 12 月の場合は 10 回の試行あたり 1 回のエラーが 4 回発生します。もう 1 つの精度テストである Top-5 では、ターゲット ラベルが分類器の予測の上位 5 つに含まれるかどうかをコンピューターに回答させます。その精度は 2013 年の 85% から 2021 年には 99% に向上し、人間のレベルを超えました。スコアは 94.9% です。
▲トップ 1 の精度の変化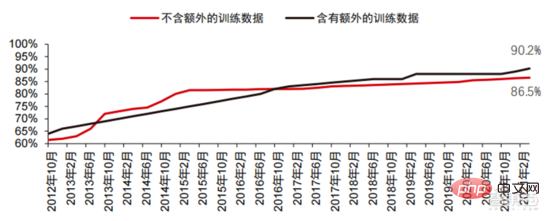
▲トップ 5 の精度の変化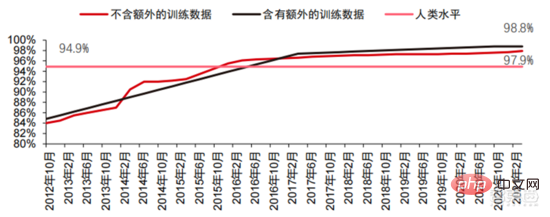
ニューラル ネットワーク アルゴリズムの開発の過程では、過去 5 年間で、
Transformer モデルが主流となり、これまで散在していたさまざまな小型モデルを統合しました。 Transformer モデルは、2017 年に Google によって開始された古典的な NLP モデルです (Bert は Transformer を使用しています)。モデルのコア部分は通常、エンコーダーとデコーダーの 2 つの部分で構成されます。エンコーダ/デコーダは主に 2 つのモジュールで構成されています: フィードフォワード ニューラル ネットワーク (図の青い部分) とアテンション メカニズム (図のバラ色の部分)。機構。エンコーダとデコーダは、ニューラル ネットワークを模倣してデータを分類し、再フォーカスします。モデルのパフォーマンスは、機械翻訳タスクにおいて RNN および CNN を上回ります。エンコーダ/デコーダのみが良好な結果を達成するために必要であり、効率的に並列化できます。
AI 大規模モデル化は、過去 2 年間に出現した新しいトレンドです。自己教師あり学習 事前トレーニング モデルの詳細-チューニングと適応のソリューションは徐々に が主流になり、 AI ビッグデータのサポートによりモデルを一般化することが可能になります。 従来の小規模モデルは、特定のフィールドのラベル付きデータを使用してトレーニングされており、汎用性が低く、別のアプリケーション シナリオに適用できないことが多く、再トレーニングが必要です。大規模な AI モデルは通常、大規模なラベルなしデータでトレーニングされ、さまざまなアプリケーション タスクのニーズを満たすように大規模なモデルを微調整できます。 OpenAI、Google、Microsoft、Facebook、NVIDIA などの組織に代表されるように、大規模インテリジェント モデルの展開は世界的な主要なトレンドとなっており、GPT-3 や Switch Transformer などの大きなパラメータを持つ基本モデルが形成されています。
NVIDIA と Microsoft が 2021 年末に共同開発した Megatron-LM のパラメータ数は 83 億個ですが、Facebook が開発した Megatron のパラメータ数は 110 億個です。これらのパラメータのほとんどは、reddit、wikipedia、ニュース Web サイトなどから取得されます。大量のデータの保存と分析に必要なデータ レイクなどのツールは、研究開発の次のステップの焦点の 1 つになります。
現在、アプリケーション側で最も成熟したテクノロジは、音声認識、画像認識などです。これらの分野を中心に、中国、米国両国で多数の企業が上場し、一定の産業クラスターが形成されている。 音声認識の分野では、比較的成熟した上場企業として、iFlytek や、以前 Microsoft に 290 億米ドルで買収された Nuance などがあります。
スマート医療:AI 医療は主に医療支援シナリオで使用されます。 医療および健康分野の AI 製品には、インテリジェントな診察、病歴収集、音声電子医療記録、医療音声入力、医用画像診断、インテリジェントなフォローアップ、医療クラウド プラットフォームなどの複数のアプリケーション シナリオが含まれます。病院の診療プロセスの観点から見ると、診断前製品は医療指導や病歴収集などの音声アシスタント製品が多く、診断中製品は音声電子症例や画像支援診断が多く、診断後製品は主に音声電子症例や画像支援診断などです。商品は主に追跡追跡商品です。医療プロセス全体におけるさまざまな製品を考慮すると、AI 医療の現在の主な適用分野は依然として補助的なシナリオであり、医師の肉体的および反復的な労働に代わるものです。 AI医療の海外大手企業ニュアンス社は、事業の50%がインテリジェント医療ソリューションであり、医療事業の主な収益源はカルテなどの臨床医療文書転記ソリューションである。
スマートシティ: 大都市病と新たな都市化は、都市ガバナンスに新たな課題をもたらし、AI 都市ガバナンスの需要を刺激します。 大中都市では人口や自動車台数の増加に伴い、都市渋滞などの問題が顕在化しています。新たな都市化の進展に伴い、スマートシティが中国都市の主要な発展モデルとなるだろう。スマートシティに関わるAIセキュリティとAI交通管理がGサイドの主要な実装ソリューションとなる。 2016 年、杭州市は初の都市データ ブレイン変革を実施し、ピーク時の混雑指数は 1.7 未満に低下しました。現在、アリババに代表される都市データブレインは、主にインテリジェントセキュリティーやインテリジェント交通などの分野に15億元以上を投資している。我が国のスマートシティ産業の規模は拡大を続けており、先進産業研究院は、2022年には25兆元に達し、2014年から2022年までの年平均複合成長率は55.27%に達すると予測している。
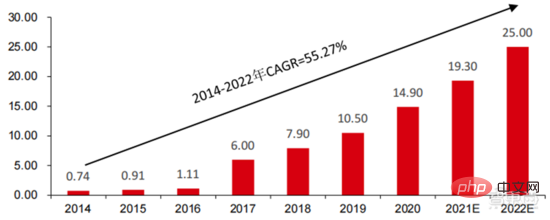 ▲ 2014-2022 スマートシティ市場規模と予測(単位:兆元)
▲ 2014-2022 スマートシティ市場規模と予測(単位:兆元)
2020年 、市場規模は 5,710 十億に達し、スマート ウェアハウジングは数千億の市場をもたらすでしょう。 物流業界における高コストとデジタル変革の状況において、倉庫物流と製品製造は、製造と流通の効率を向上させるための自動化、デジタル化、インテリジェントな変革の緊急のニーズに直面しています。中国物流購買連合会のデータによると、中国のスマート物流市場は2020年に5,710億元に達し、2013年から2020年までの年間平均複合成長率は21.61%となる見込みだ。モノのインターネット、ビッグデータ、クラウド コンピューティング、人工知能などの新世代の情報技術は、スマート ロジスティクス業界の発展を促進するだけでなく、スマート ロジスティクス業界のサービス要件をさらに高めています。物流市場は今後も拡大が見込まれます。 GGIIの推計によると、2019年の中国のスマート倉庫市場規模は900億元近くで、前進研究所はこの数字が2025年には1500億元以上に達すると予測している。
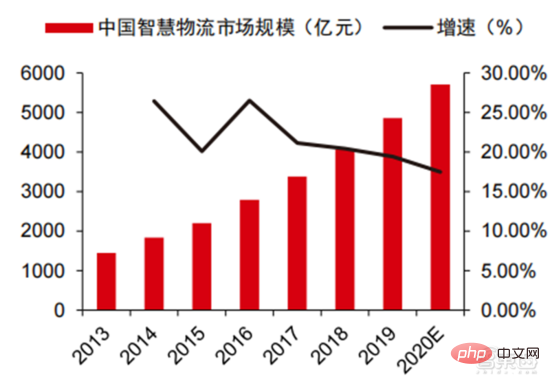 ▲ 2013年から2020年までの中国のスマート物流市場規模と成長率
▲ 2013年から2020年までの中国のスマート物流市場規模と成長率
新しい小売: 人工知能は人件費の削減と業務効率の向上をもたらします。 Amazon Go は Amazon が提唱する無人店舗コンセプトで、2018 年 1 月 22 日に米国シアトルに正式オープンしました。 AmazonGo はクラウド コンピューティングと機械学習を組み合わせ、Just Walk Out テクノロジーと Amazon Rekognition を適用します。店内のカメラ、センサーモニター、そしてそれらを支える機械アルゴリズムが消費者が持ち去った商品を識別し、客が店を出るときに自動的にチェックアウトするという、小売業の分野における全く新しい革命です。
クラウドベースの人工知能モジュール コンポーネントは、現在、人工知能の商業化における大手インターネット大手の主な方向性です。 人工知能テクノロジーをパブリック クラウド サービスに統合して販売します。 Google Cloud Platform の AI テクノロジーは常に業界の最前線にあり、高度な AI テクノロジーをクラウド コンピューティング サービス センターに統合することに尽力しています。近年、Googleは多くのAI企業を買収し、そのレイアウトを完成させるためにAI専用チップTPUやクラウドサービスCloud AutoMLなどの製品を発売している。現在、Google の AI 機能は、コグニティブ サービス、機械学習、ロボティクス、データ分析とコラボレーション、その他の分野をカバーしています。 AI 分野における一部のクラウド ベンダーの比較的分散した製品とは異なり、Google は AI 製品の運用においてより完全かつ体系的であり、垂直アプリケーションを基本的な AI コンポーネントに統合し、Tensorflow と TPU コンピューティングをインフラストラクチャに統合して、完全なAIプラットフォームサービス。
Baidu は、中国の AI で最も有能なパブリック クラウド ベンダー、Baidu AI の中核です。戦略 それはオープンなエンパワーメントです。 Baidu は、エコシステムをオープンにし、データとシナリオの前向きな反復を形成するために、DuerOS や Apollo に代表される AI プラットフォームを構築しました。 Baidu インターネット検索のデータ基盤に基づいて、自然言語処理、ナレッジ グラフ、ユーザー ポートレート技術が徐々に成熟してきました。プラットフォームと生態レベルでは、Baidu Cloud はすべてのパートナーにオープンな大規模なコンピューティング プラットフォームであり、Baidu Brain のさまざまな機能を備えた基本的なサポート プラットフォームになります。自然言語ベースの人間とコンピューターの対話に基づく新世代オペレーティング システムや、インテリジェント運転に関連する Apollo など、垂直ソリューションもいくつかあります。自動車メーカーは必要な機能を呼び出すことができ、自動車エレクトロニクスメーカーも、プラットフォーム全体とエコシステム全体を共同で構築するために必要な対応する機能を呼び出すことができます。
近年、AI産業の技術進化ルートは、主に以下の特性が示されています: 基礎となるモジュールのパフォーマンスが向上し続けており、モデルの汎化能力に焦点を当てた改善により、AI アルゴリズムの汎用性の最適化とデータ収集のフィードバックに役立ちます。 AI テクノロジーの持続可能な開発は、基礎となるアルゴリズムのブレークスルーに依存しており、そのためには、コンピューティング能力を核とした基本的な機能の構築と、知識と経験を学習するためのビッグデータによってサポートされる環境も必要です。業界における大規模モデルの急速な人気、大規模モデルと小規模モデルの動作モード、チップやコンピューティング インフラストラクチャなどの基礎となるリンクの機能の継続的な改善、およびその結果としてのアプリケーション シナリオ カテゴリとシナリオの継続的な改善最終的には、基本的な産業能力と応用シナリオの間で継続的な相互促進をもたらし、フォワード サイクル ロジックの下で世界の AI 産業の発展が加速し続けることになります。
大規模なモデルは、強力な一般的な問題解決能力をもたらします。 現在、ほとんどの人工知能は「手作業によるワークショップ形式」であり、さまざまな業界の下流アプリケーションに直面して、AIは徐々に断片化と多様化の特性を示しており、モデルの汎用性は高くありません。一般的な解決能力を向上させるために、大規模モデルは、「大規模モデルの事前トレーニングと下流タスクの微調整」という実現可能な解決策を提供します。このソリューションは、大量のラベル付きデータとラベルなしデータから知識を取得し、知識を多数のパラメーターに保存して特定のタスクを微調整することでモデルの汎化機能を向上させることを指します。
大規模モデルは、既存のモデル構造の精度限界をさらに突破することが期待されており、ネストされた小規模モデルのトレーニングと組み合わせることで、 特定のシナリオにおけるモデルの効率がさらに向上します。 過去 10 年間、モデルの精度向上は主にネットワークの構造変更に依存していましたが、ニューラル ネットワークの構造設計技術が徐々に成熟し収束するにつれて、精度向上がボトルネックに達し、大型モデルはこのボトルネックを突破すると期待されています。 Google の視覚転送モデル Big Transfer、BiT を例に挙げると、ILSVRC-2012 (128 万画像、1000 カテゴリ) と JFT-300M (3 億画像、18291 カテゴリ) の 2 つのデータセットが ResNet50 のトレーニングに使用されます。それぞれ 77% と 79% であり、大きなモデルを使用するとボトルネックの精度がさらに向上します。さらに、JFT-300M を使用して ResNet152x4 をトレーニングすると、精度が 87.5% まで向上し、ILSVRC-2012 ResNet50 構造より 10.5% 高くなります。
大きなモデル 小さなモデル: 一般化された大規模モデル人工知能の推進と、特定のシナリオでのデータ最適化との組み合わせが、人工知能の商用化になります。中期のキーとなる業界。特定のシナリオに合わせてデータを再抽出するオリジナルのモデルは、モデルの再トレーニングのコストが高すぎ、得られたモデルの汎用性が低く、再利用が困難であるため、収益を上げることが難しいことが判明しています。チップのコンピューティング能力の継続的な向上を背景に、大きなモデルを小さなモデルにネストする試みは、メーカーに別のアイデアを提供します。大量のデータを分析することで汎用モデルを取得し、特定の小さなモデルをネストしてソリューションを提供できます。さまざまなシナリオに合わせて最適化され、コストが大幅に節約されます。 Alibaba Cloud、Huawei Cloud、Tencent Cloud などのパブリック クラウド ベンダーは、モデルの汎用性を向上させるために、自社開発の大規模モデル プラットフォームの開発を積極的に行っています。
AI Nvidia に代表される大手チップ企業の新世代チップでは、 AI が一般的に使用されています。業界 モデルの新しいエンジンは、コンピューティング能力を大幅に向上させるために特別に設計されています。 NVIDIA の Hopper アーキテクチャには、AI トレーニングを大幅に加速する Transformer エンジンが導入されています。 Transformer エンジンは、ソフトウェアとカスタム NVIDIA Hopper Tensor Core テクノロジを使用します。これは、Transformer として知られる一般的な AI モデル構築ブロックに基づいて構築されたモデルのトレーニングを高速化するように設計されています。これらの Tensor コアは、FP8 と FP16 の混合精度を適用して、Transformer モデルの AI 計算を大幅に高速化できます。 FP8 を使用した Tensor コア操作は、16 ビット操作の 2 倍のスループットを備えています。 Transformer エンジンは、FP8 と FP16 の計算を動的に選択し、各レイヤーでこれらの精度間の再投影とスケーリングを自動的に処理する、NVIDIA が調整したカスタムのヒューリスティックでこれらの課題に対処します。 NVIDIA が提供するデータによると、Transformer モデルをトレーニングする場合、Hopper アーキテクチャは Ampere モデルよりも 9 倍効率的です。 大規模モデル テクノロジのトレンドの下で、クラウド ベンダーは徐々にコンピューティング パワー市場の中心的なプレーヤーになりつつあります。人工知能テクノロジ フレームワークが大規模モデルを通じて一般化に向けて発展した後、クラウド ベンダーは PaaS 機能を使用して、クラウド ベンダーを統合することもできます。基盤となる IaaS 機能を PaaS と組み合わせて、市場にユニバーサル ソリューションを提供します。大規模なモデルの出現に伴い、人工知能が処理および分析する必要があるデータの量は日に日に増加しており、同時に、データのこの部分は過去の専門的なデータセットから次のデータセットに変換されています。汎用ビッグデータ。クラウド コンピューティングの巨人は、その強力な PaaS 機能と基盤となる IaaS 基盤を組み合わせて、人工知能メーカーにワンストップのデータ処理を提供できます。これは、クラウド コンピューティングの巨人が、この一連の人工知能の波の主な受益者の 1 つになるのにも役立ちました。
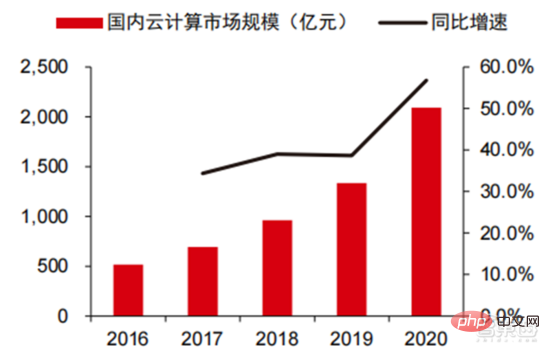 ▲ 国内クラウドコンピューティング市場規模
▲ 国内クラウドコンピューティング市場規模
現在、AWS や Azure などの国際主流クラウドベンダーが、Alibaba Cloud や Tencent Cloud などの国内有力クラウドと競合しています。メーカーは、データ ストレージやデータ処理などの PaaS 機能に焦点を当て始めています。ストレージ機能の点では、データ型がますます複雑になるにつれて、NoSQL データベースには今後さらに多くの機会が訪れるでしょう。たとえば、Google Cloud は、レイアウトをオブジェクト クラス、従来のリレーショナル データベース、NoSQL データベースに分散させています。データ処理の観点からは、データ レイクとデータ ウェアハウスの重要性がますます高まっており、製品ラインのこの部分を改善することで、クラウド コンピューティングの巨人は完全なデータ サイクル モデルを構築し、それを基盤となる IaaS の基本機能と組み合わせました。完全な製品ラインとクローズド データ サイクル モデルは、クラウド コンピューティングの巨人が将来 AI 中間層で競争する上で最大の利点となります。
AI産業チェーン構造が徐々に明確になり、大規模モデルによってもたらされる産業運営効率と技術深度の大幅な向上により、中期的にはAI技術が飛躍的に進歩しないと仮定すると、順方向移行により、AI 産業はチェーンの価値が徐々に両端に近づき、中間リンクの価値は引き続き弱まり、徐々に「チップコンピューティング」の典型的な産業チェーン構造を形成すると予想されます。同時に、このような産業構造の取り決めの下では、上流のチップ企業、クラウドインフラストラクチャのメーカー、下流のアプリケーションメーカーが、電力インフラの急速な発展の中核的受益者となることが徐々に予想されます。 AI業界。
大規模なモデルは、AI の基礎となる技術アーキテクチャの統合とコンピューティング能力への膨大な需要をもたらします。これは当然、クラウド コンピューティング企業がこのプロセスで基本的な役割を果たすのに役立ちます。クラウド コンピューティングは、世界的に最も広く分布し、最も強力です。一方、AI フレームワークと一般的なアルゴリズムは最も典型的な PaaS 機能であり、クラウド ベンダーのプラットフォーム機能に統合される傾向があります。したがって、技術的な多様性と実際のビジネス ニーズの観点から、大規模なモデルによって推進され、クラウド コンピューティングの巨人が徐々にコンピューティング施設における基本的なアルゴリズム フレームワーク機能の主要なプロバイダーとなり、既存の AI アルゴリズム プラットフォーム プロバイダーのビジネスを侵食し続けると予想されます。 。 空間。過去のクラウドベンダーのさまざまな製品の見積書からもわかりますが、AWSやGoogleの製品を例に挙げると、米国東部におけるLinusのオンデマンド利用料金は段階的に下がっています。
図からわかるように、2 つの vCPU、2 つの ECU、7.5 GiB を備えた m1.large 製品の価格は、2008 年の約 0.4 ドル/時間から、2022 年の約 0.18 ドル/時間まで下がり続けています。 8 個の vCPU と 30 GB のメモリを備えた Google Cloud の n1-standard-8 製品のオンデマンド価格も、2014 年の 0.5 米ドル/時間から 2022 年には 0.38 米ドル/時間に下がりました。クラウド コンピューティングの価格は上昇傾向にあることがわかります。全体的には下降傾向。今後 3 ~ 5 年間で、AI-as-a-Service (AIaaS) サービスがさらに登場するでしょう。前述した大規模モデルのトレンド、特に GPT-3 の誕生がこの傾向を引き起こしましたが、GPT-3 はパラメーターが膨大であるため、Azure 規模のコンピューティング施設などの巨大なパブリック クラウド コンピューティング能力で実行する必要があります。 Microsoft が Web API を通じて取得できるサービスにすることで、より大規模なモデルの出現も促進されます。
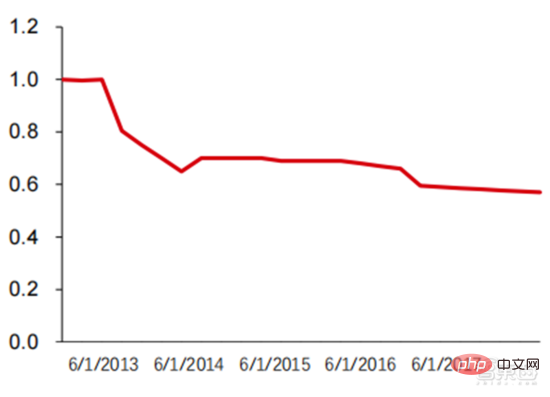
▲ AWS EC2 の過去の標準化価格 (USD/時間)
現在のコンピューティング能力の状況と予測可能な技術能力のサポートにより、アプリケーション エンドは継続します。データ取得を通じてアルゴリズムの反復と最適化を実現し、現在の認知知能(画像認識方向)にまだ存在する欠点を改善し、意思決定知能への発展を試みます。現在の技術的能力とハードウェアのコンピューティング能力サポートによると、完全な意思決定インテリジェンスを達成するにはまだ長い時間がかかると考えられ、既存のシナリオの継続的な深化に基づいてローカル インテリジェンスを作成することが 3 ~ 5 年以内の主な方向性となるでしょう。現在の AI アプリケーション レベルはまだ単一点すぎており、ローカル接続を完了することが意思決定インテリジェンスを実現するための第一歩となります。人工知能ソフトウェア アプリケーションには、ビジネス指向 (製造、金融、物流、小売、不動産など) から人間 (メタバース、医療、ヒューマノイド ロボットなど) まで、下位レベルのドライバーから上位レベルのアプリケーションとアルゴリズム フレームワークが含まれます。 )、自動運転などの分野。
Zhidongxi 氏は、AI チップ、コンピューティング能力設備、データなどの基本要素が継続的に改善され、大規模モデルによってもたらされる問題解決を一般化する能力が大幅に向上することで、AI が完成すると信じています。業界は「チップコンピューティングパワー基盤」を形成しつつある 「施設AIフレームワーク&アルゴリズムライブラリアプリケーションシナリオ」の安定した産業バリューチェーン構造により、AIチップメーカー、クラウドコンピューティングメーカー(コンピューティング施設アルゴリズムフレームワーク)、AIアプリケーションシナリオメーカー、プラットフォームアルゴリズムフレームワークメーカーなどは今後も業界の中核的受益者となることが予想されます。
以上が詳細レポート: 大規模なモデル駆動型 AI が全面的に高速化!黄金の10年が始まるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



