


DeepRec (PAI-TF) は、Alibaba Group の統合オープンソース レコメンデーション エンジン (https://github.com/alibaba/DeepRec) で、主にスパース モデルのトレーニングと予測に使用され、数百のモデルをサポートできます。数十億の機能、数兆のサンプルによる超大規模なスパース トレーニングには、トレーニングのパフォーマンスと効果において明らかな利点があります。現在、DeepRec は、淘宝網の検索、推奨、広告、その他のシナリオをサポートしており、淘宝網、天猫、アリママ、Amap などで広く使用されています。その他の事業。
インテルは、2019 年以来、アリババ PAI チームと緊密に連携して、インテル人工知能 (AI) テクノロジーを DeepRec に適用し、演算子、サブグラフ、ランタイム、フレームワーク層、モデルを完全にターゲットにしています。インテルのソフトウェアとハードウェアの利点を活用して、アリババが社内および社外の AI ビジネスのパフォーマンスを加速できるように支援します。
現在の主流のオープンソース エンジンには、超大規模なスパース トレーニング シナリオのサポートにおいて依然として一定の制限があります。たとえば、オンライン トレーニングがサポートされていない、機能を動的にロードできない、オンラインでの展開と反復が不便である、特にパフォーマンスがビジネス ニーズを満たすのが難しいなど、問題は特に顕著です。上記の問題を解決するために、DeepRec は TensorFlow1.15 に基づいて詳細にカスタマイズされ、スパース モデル シナリオ向けに最適化されており、主な対策には次の 3 つのカテゴリが含まれます。効果: 主に、EmbeddingVariable (EV) 動的弾性特徴機能の追加と、最適化を実現するための Adagrad Optimizer の改善によって行われました。 EV 機能は、ネイティブ変数サイズの推定の困難さや機能の競合などの問題を解決し、機能の承認および削除戦略などの高度な機能を豊富に提供すると同時に、ホット機能とコールド機能のディメンションを頻度に基づいて自動的に構成します。特徴の出現、追加高周波特徴の表現力により、過剰適合が軽減され、スパース モデルの効果が大幅に向上します。
トレーニングと推論のパフォーマンス: スパースの場合DeepRec は分散型であり、サブグラフ、演算子、ランタイム、およびその他の側面で徹底的なパフォーマンスの最適化が行われています。これには、分散戦略の最適化、自動パイプライン SmartStage、自動グラフ融合、埋め込みとアテンションおよびその他のグラフの最適化、一般的なスパース演算子の最適化、メモリが含まれます。管理の最適化により、メモリ使用量が大幅に削減され、エンドツーエンドのトレーニングと推論のパフォーマンスが大幅に高速化されます。
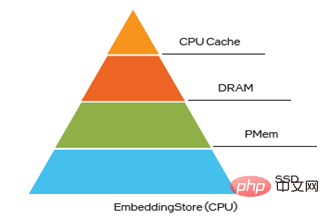
デプロイとサービス:DeepRec は、増分モデルのエクスポートと読み込みをサポートしており、 10TB レベル非常に大規模なモデルの分単位のオンライン トレーニングと更新が開始され、ビジネスの高い適時性要件を満たします。スパース モデルの機能のホット スキュー特性とコールド スキュー特性を考慮して、DeepRec はマルチレベルのハイブリッド ストレージを提供します(最大4 レベルのハイブリッド ストレージ (HBM DRAM PMem SSD) 機能を使用すると、コストを削減しながら大規模モデルのパフォーマンスを向上させることができます。
Intel テクノロジーは、DeepRec の高いパフォーマンスの実現に役立ちます Intel と Alibaba の PAI チームの緊密な協力は、上記の 3 つの独自の利点を達成する上で重要な役割を果たしました。これらの利点は、インテル テクノロジーの巨大な価値も完全に反映しています。
パフォーマンス最適化の観点から、インテルの超大規模クラウド ソフトウェア チームはアリババと緊密に連携して、次の目標を達成しています。 CPU プラットフォームは、オペレーター、サブグラフ、フレームワーク、ランタイムなどの複数のレベルから最適化され、インテル® Xeon® スケーラブル プロセッサーのさまざまな新機能を最大限に活用し、ハードウェアの利点を最大限に活用します。
CPU プラットフォームでの DeepRec の使いやすさを向上させるために、また、主流の推奨モデルのほとんどをサポートする Modelzoo を構築し、DeepRec の独自の EV 機能をこれらのモデルに適用して、アウト・オブ・ザ・開発を実現しました。 -boxのユーザーエクスペリエンス。 同時に、ストレージおよび KV ルックアップ操作用の超大規模スパース トレーニング モデル EV の特別なニーズに応えて、インテル Optane イノベーション センター チームは、以下に基づくソリューションを提供します。 Intel® Optane
TM永続メモリ (略して「PMem」) のメモリ管理およびストレージ ソリューションは、DeepRec マルチレベル ハイブリッド ストレージ ソリューションをサポートおよび連携して、大容量メモリと低コストのニーズを満たします。 プログラマブル ソリューション部門チーム FPGA を使用してエンベディング用の KV 検索機能を実装します。これにより、エンベディング クエリ機能が大幅に向上し、より多くの CPU リソースが解放されます。 CPU、PMem、FPGA の異なるハードウェア特性を組み合わせることで、システムの観点から、インテルのソフトウェアとハードウェアの利点をさまざまなニーズに最大限に活用することができ、アリババの AI ビジネスにおける DeepRec の実装を加速し、スパース全体に対してより優れたソリューションを提供できます。シナリオ ビジネス エコシステム、優れたソリューション。
#インテル® DL ブーストは、DeepRec の重要なパフォーマンスの高速化を実現します。
インテル® DL ブースト (インテル® ディープラーニング アクセラレーション) による DeepRec の最適化は、主に フレームワーク最適化、オペレーター最適化、サブグラフ最適化、モデル最適化 の 4 つのレベルに反映されます。 インテル® Xeon® スケーラブル プロセッシングよりプロセッサの登場により、インテルは AVX 256 から AVX-512 にアップグレードすることで AVX の機能を 2 倍にし、ディープラーニングのトレーニングと推論機能を大幅に向上させました。また、第 2 世代のインテル® Xeon® スケーラブル プロセッサーは DL Boost_VNNI の導入により大幅に向上しました。 INT8 の乗算と加算の計算のパフォーマンスが向上しました。第 3 世代インテル® Xeon® スケーラブル プロセッサー以降、インテルは、深層学習のトレーニングと推論のパフォーマンスをさらに向上させるために、BFloat16 (BF16) データ型をサポートする命令セットを発売しました。ハードウェア テクノロジーの継続的な革新と開発により、インテルは次世代 Xeon® スケーラブル プロセッサーで新しい AI 処理テクノロジーを導入し、VNNI と BF16 の機能を 1 次元ベクトルから 2 次元行列にさらに向上させます。前述のハードウェア命令セット テクノロジは DeepRec の最適化に適用されており、さまざまなコンピューティング要件に応じてさまざまなハードウェア機能を使用できるようになり、インテル® AVX-512 および BF16 がスパースでのトレーニングと推論の高速化に非常に適していることも検証されました。シナリオ。 ##図 1 インテル x86 プラットフォーム AI 機能の進化グラフ DeepRec コンパイル オプションに「--config=mkl_threadpool」を追加するだけで、oneDNN の最適化を簡単に有効にできます。
ケース 1: Select 演算子の実装原理は、条件に基づいて要素を選択することです。この場合、次のようにインテル® AVX-512 のマスク ロード メソッドを使用できます。図2左図では、if条件による大量の判定による時間オーバーヘッドを削減し、一括選択によりデータの読み書き効率を向上させ、最終的なオンラインテストでは大幅な性能向上が確認されました。
##ケース 2: 同じです。インテル® AVX-512 のアンパックおよびシャッフル命令を使用して転置演算子を最適化できます。つまり、図の右の図に示すように、小さなブロックを介して行列を転置できます。 2. 最後のオンライン テストでも、パフォーマンスが非常に大幅に向上していることがわかりました。 サブグラフの最適化 tf.feature_column.embedding_column(..., do_fusion=True) API で do_fusion を True に設定すると、埋め込みサブグラフ最適化関数をオンにできます。 Intel は、CPU プラットフォームに基づいて、WDL、DeepFM、DLRM、DIEN、などをカバーする DeepRec を構築しました。 DIN、DSSM、BST、MMoE、DBMTL、ESMM などの複数の主流モデルの推奨モデルの独自のコレクションで、リコール、並べ替え、複数の目的などのさまざまな一般的なシナリオ、およびハードウェア プラットフォームのパフォーマンスの最適化が含まれます。他のフレームワークと比較して、Criteo などのオープンソース データセットに基づく CPU プラットフォーム上のこれらのモデルのパフォーマンスが大幅に向上します。 最も優れたパフォーマンスは、間違いなく、混合精度の BF16 と Float32 の最適化された実装です。 DeepRecにDNN層のデータ型をカスタマイズする機能を追加し、スパースシーンの高性能・高精度の要件を満たすことで最適化を可能にする方法は図3の通りです。勾配の累積による精度低下を防ぐために使用される Float32 を介して keep_weights を使用し、2 つのキャスト演算を使用して DNN 演算を BF16 に変換して計算します。第 3 世代インテル® Xeon® スケーラブルの BF16 ハードウェア演算ユニットに依存します。プロセッサー、DNN コンピューティングのパフォーマンスが大幅に向上すると同時に、グラフ フュージョン キャスト操作を通じてパフォーマンスがさらに向上します。 図 3 混合精度の最適化を有効にする方法 モデル精度 AUC (曲線下面積) およびパフォーマンス Gsteps/s に対する BF16 の影響を実証するために、上記の混合精度最適化手法を既存の modelzoo モデルに適用します。 Alibaba Cloud プラットフォーム上で DeepRec を使用した Alibaba PAI チームの評価では、Criteo データセットに基づき、次の方法で最適化された [1] が示されました。 BF16 では、モデルの WDL 精度または AUC が FP32 に近づくことができ、BF16 モデルのトレーニング パフォーマンスが最大 1.4 倍向上しており、これは大きな効果です。 将来的には、CPU プラットフォームのハードウェアの利点を最大限に活用するために、特に新しいハードウェア機能の効果を最大化するために、DeepRec はさらに最適化を実装します。オプティマイザー オペレーター、アテンション サブグラフ、多目的モデルの追加など、さまざまな角度から分析を行って、まばらなシーン向けのより高性能な CPU ソリューションを作成します。 PMem を使用して埋め込みストレージを実装する 非常に大規模なスパース モデルのトレーニングおよび予測エンジン (数千億の特徴、数兆のサンプル、および 10 TB のモデル レベル) がすべてダイナミック ランダム アクセス メモリ (DynamicRandomAccessMemory、DRAM) に保存されている場合、総所有コスト (Total Cost of Ownership) は、TCO)が大幅に増加すると同時に、企業の IT 運用と管理に大きな圧力がかかり、AI ソリューションの導入が課題に直面します。 PMem には、より高いストレージ密度とデータ永続性、I/O パフォーマンスが DRAM に近く、コストがより手頃であるという利点があり、高性能と要求を完全に満たすことができます。超大規模なスパーストレーニングと予測のための高性能、両方の面で大容量が必要です。 PMem は、メモリ モードとアプリ ダイレクト モードという 2 つの動作モードをサポートしています。メモリ モードでは、通常の揮発性 (非永続) システム ストレージと同じですが、コストが低く、システム予算を維持しながら大容量化が可能になり、単一サーバーでテラバイトのメモリを提供できます。直接アクセス モードでは、PMem の永続化機能を利用できます。アプリケーション ダイレクト アクセス モードでは、PMem とそれに隣接する DRAM メモリはバイト アドレス指定可能なメモリとして認識されます。オペレーティング システムは、PMem ハードウェアを 2 つの異なるデバイスとして使用できます。1 つは FSDAX モードで、PMem はブロック デバイスとして構成されており、ユーザーは使用するためにファイル システムにフォーマットします。もう 1 つは DEVDAX モードで、PMem は単一のキャラクタ デバイスとして駆動され、カーネル (5.1 以降) によって提供される KMEM DAX 機能に依存し、PMem を揮発性として扱います。 DRAM と同様に、低速で大容量のメモリ NUMA ノードとして、アプリケーションは透過的にアクセスできます。 非常に大規模な特徴量トレーニングでは、埋め込み変数ストレージがメモリの 90% 以上を占有し、メモリ容量がボトルネックの 1 つになります。 EV を PMem に保存すると、このボトルネックを打破し、大規模な分散トレーニングのメモリ ストレージ容量の向上、より大きなモデルのトレーニングと予測のサポート、複数のマシン間の通信の削減、モデル トレーニングのパフォーマンスの向上など、複数の価値を生み出すことができます。 TCO を削減します。 マルチレベル ハイブリッド ストレージの組み込みにおいて、PMem は DRAM ボトルネックを解消する優れた選択肢でもあります。現在、PMem に EV を保存するには 3 つの方法があり、次の 3 つの方法でマイクロベンチマーク、WDL モデル、および WDL プロキシ モデルを実行すると、パフォーマンスは EV を DRAM に保存する場合に非常に近くなり、間違いなく TCO が向上します。大きな利点: Alibaba PAI チームは、Alibaba Cloud のメモリ強化インスタンス ecs.re7p.16xlarge で EV を保存する 3 つの方法を使用して、WDL スタンドアロン モデルの比較テストを実施しました。 Modelzoo [2] では、これら 3 つの方法は、EV を DRAM に保存し、Libpmem ライブラリに基づくアロケータを使用して EV を保存し、使用することです。 EV を保存するための Libpmem ライブラリに基づくアロケータ、EV を保存するための Memkind ライブラリ アロケータのテスト結果は、EV を PMem に保存するパフォーマンスが EV を DRAM に保存するパフォーマンスに非常に近いことを示しています。 図 4 マルチレベル ハイブリッド ストレージの組み込み FPGA アクセラレーテッド エンベディング ルックアップ 大規模なストレージ容量要件 (最大 10 TB 以上); TCP/RDMA ベースの rpc によってもたらされるオーバーヘッドにより、分散拡張中にパラメータ サーバーがボトルネックになります。明らかな遅延とパフォーマンスのボトルネック。 TM I シリーズ FPGA は、1 つのハードウェア プラットフォーム上で上記のシナリオをすべてサポートできるため、パフォーマンスが大幅に向上します。アクセス待ち時間を短縮しながら、スループットを向上させます。 前回の記事では、CPU、PMem、FPGA のさまざまなハードウェア上での DeepRec の最適化実装スキームを紹介し、それを複数の社内および社外のビジネス シナリオにうまく導入しました。また、実際のビジネスにおいてエンドツーエンドのパフォーマンスの大幅な高速化を実現し、超大規模なスパース シナリオが直面する問題や課題をさまざまな角度から解決しました。周知のとおり、インテルは AI アプリケーションに多様なハードウェア オプションを提供し、顧客がよりコスト効率の高い AI ソリューションを選択できるようにしています。同時に、インテル、アリババ、およびその顧客は協力して、次のようなソフトウェアとハードウェアのイノベーションを実装しています。多様なハードウェアを連携し、最適化することで、インテルのテクノロジーとプラットフォームの価値をより完全に実現します。インテルはまた、業界パートナーと協力して協力を深め、AI テクノロジーの展開に貢献し続けたいと考えています。 インテルはサードパーティのデータを管理または監査しません。このコンテンツを確認し、他の情報源を参照し、記載されているデータが正確であることを確認してください。 パフォーマンス テストの結果は、2022 年 4 月 27 日と 2022 年 5 月 23 日に実施されたテストに基づいており、公開されているすべてのセキュリティ更新プログラムを反映しているわけではありません。詳細については、構成の開示を参照してください。完全に安全な製品やコンポーネントはありません。 ここで説明するコスト削減シナリオは、特定のインテル製品が将来のコストにどのような影響を及ぼし、特定の状況や構成でコスト削減を実現できるかを示すことを目的としています。状況はそれぞれ異なります。インテルはコストやコスト削減を保証しません。 インテル テクノロジーの機能と利点はシステム構成によって異なり、有効なハードウェア、ソフトウェア、またはサービスをアクティブ化する必要がある場合があります。製品のパフォーマンスはシステム構成によって異なります。完全に安全な製品やコンポーネントはありません。詳細については、OEM メーカーまたは小売店から入手するか、intel.com を参照してください。 Intel、Intel ロゴ、およびその他の Intel の商標は、米国およびその他の国における Intel Corporation またはその子会社の商標です。 © Intel Corporation All Rights Reserved [1] Ifパフォーマンス テストの詳細については、https://github.com/alibaba/DeepRec/tree/main/modelzoo/WDL [2] をご覧ください。 パフォーマンス テストの詳細については、https://help.aliyun.com/document_detail/25378.html?spm=5176.2020520101.0.0.787c4df5FgibRE#re7p## をご覧ください。 #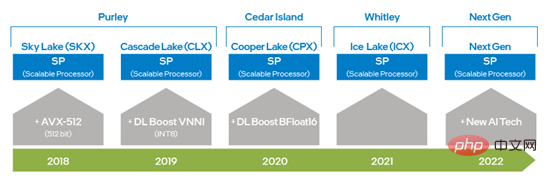
DeepRec は、Intel のオープンソース クロスプラットフォーム ディープ ラーニング パフォーマンス アクセラレーション ライブラリ oneDNN (oneAPI Deep Neural Network Library) を統合します。 )、oneDNN の元のスレッド プールを変更して DeepRec の Eigen スレッド プールに統合しました。これにより、スレッド プールの切り替えオーバーヘッドが削減され、異なるスレッド プール間の競合によって引き起こされるパフォーマンスの低下が回避されました。 oneDNN は、MatMul、BiasAdd、LeakyReLU、およびスパース シナリオでのその他の一般的な演算子を含む、多数の主流演算子に対してパフォーマンスの最適化を実装しています。これにより、検索およびプロモーション モデルに強力なパフォーマンス サポートを提供できます。また、oneDNN の演算子は、BF16 データ型もサポートしています。 BF16 命令セットを搭載した第 3 世代インテル® Xeon® スケーラブル プロセッサーと併用すると、モデルのトレーニングと推論のパフォーマンスが大幅に向上します。 #オペレーターの最適化
 #図 2 オペレーター最適化のケースの選択
#図 2 オペレーター最適化のケースの選択

インテル® Agilex に基づくアクセラレーション ソリューション
以上がインテル、オープンソースの大規模スパース モデル トレーニング/予測エンジン DeepRec の構築を支援の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



