


この記事では、「なぜツリーベースのモデルが表形式データの深層学習よりも優れているのか」という論文について詳しく説明しますこの論文では、さまざまな分野の世界中の機械学習の専門家によって観察された観察について説明します。観測結果 - ツリーベースのモデルは、深層学習/ニューラル ネットワークよりも表形式データの分析に優れています。
この論文には多くの前処理が施されています。たとえば、欠落データの削除などはツリーのパフォーマンスを妨げる可能性がありますが、データが非常に乱雑であり、多くの特徴とディメンションが含まれている場合には、ランダム フォレストはデータ欠落の状況に最適です。 RF の堅牢性と利点により、RF は問題が発生しやすい「高度な」ソリューションよりも優れています。

残りの作業のほとんどは非常に標準的なものです。私は個人的には、データセットの多くのニュアンスが失われる可能性があるため、あまり多くの前処理テクニックを適用するのは好きではありませんが、この論文で実行される手順は基本的に同じデータセットを生成します。ただし、最終結果を評価するときにも同じ処理方法が使用されることに注意することが重要です。
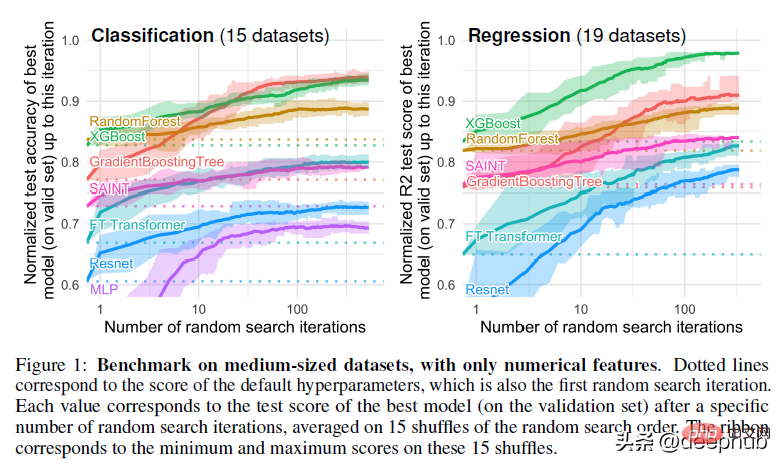
この論文では、ハイパーパラメータ調整にランダム検索も使用しています。これは業界標準でもありますが、私の経験では、ベイジアン検索の方がより広い検索空間での検索に適しています。
これを理解すると、なぜツリーベースの手法が深層学習よりも優れたパフォーマンスを発揮するのかという主要な疑問に踏み込むことができます。
これは著者が共有する最初の理由は、深層学習ニューラル ネットワークがランダム フォレストと競合できない理由です。つまり、滑らかでない関数や決定境界に関しては、ニューラル ネットワークは最適な適合を作成するのが困難です。ランダム フォレストは、奇妙な/ギザギザ/不規則なパターンでより効果的です。

理由を推測すると、ニューラル ネットワークで勾配が使用されている可能性があります。勾配は定義上滑らかな微分可能な検索空間に依存しているため、鋭い点といくつかのランダム関数を区別することは不可能です。したがって、進化的アルゴリズム、従来型検索、その他の基本的な概念などの AI の概念を学習することをお勧めします。これらの概念は、NN が失敗したときのさまざまな状況で素晴らしい結果につながる可能性があります。
ツリーベースのメソッド (RandomForests) とディープラーナーの間の決定境界の違いのより具体的な例については、以下の図をご覧ください -
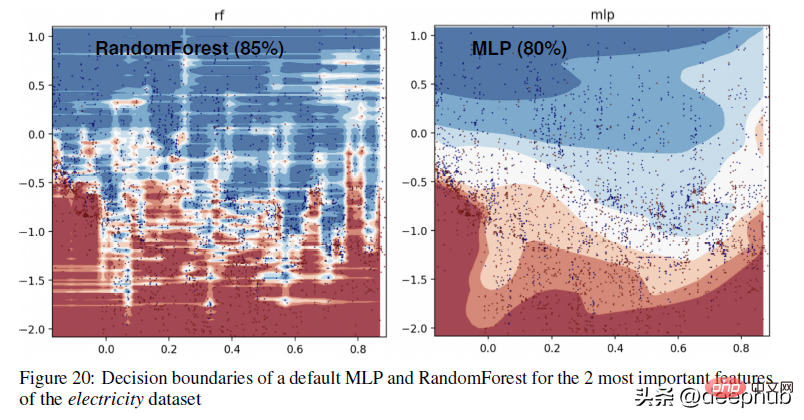
付録で、著者は上記の視覚化を次のように説明しています。
このパートでは、RandomForest が MLP では学習できない x 軸上の不規則なパターン (日付特徴に対応) を学習できることがわかります。学ぶ。この違いを、ニューラル ネットワークの典型的な動作であるデフォルトのハイパーパラメーターで示しますが、実際には、これらのパターンを適切に学習するハイパーパラメーターを見つけるのは困難です (不可能ではありません)。
もう 1 つの重要な要素は、特に複数の関係を同時にエンコードする大規模なデータ セットにとって重要です。無関係な特徴をニューラル ネットワークに供給すると、ひどい結果になります (モデルのトレーニングにより多くのリソースを無駄にすることになります)。これが、EDA/ドメイン探索に多くの時間を費やすことが非常に重要である理由です。これは機能を理解し、すべてがスムーズに実行されるようにするのに役立ちます。
論文の著者は、ランダムな機能を追加したり、不要な機能を削除したりするときのモデルのパフォーマンスをテストしました。その結果に基づいて、2 つの非常に興味深い結果が見つかりました。
多数の機能を削除すると、モデル間のパフォーマンスのギャップが減少します。これは、ツリー モデルの利点の 1 つが、特徴が有用かどうかを判断し、不要な特徴の影響を回避できることであることを明確に示しています。
データセットにランダムな特徴を追加すると、ニューラル ネットワークがツリーベースの方法よりも大幅に劣化することがわかります。 ResNet は特に、これらの役に立たない特性に悩まされています。トランスの改良は、その中のアテンション機構がある程度役に立つからかもしれません。
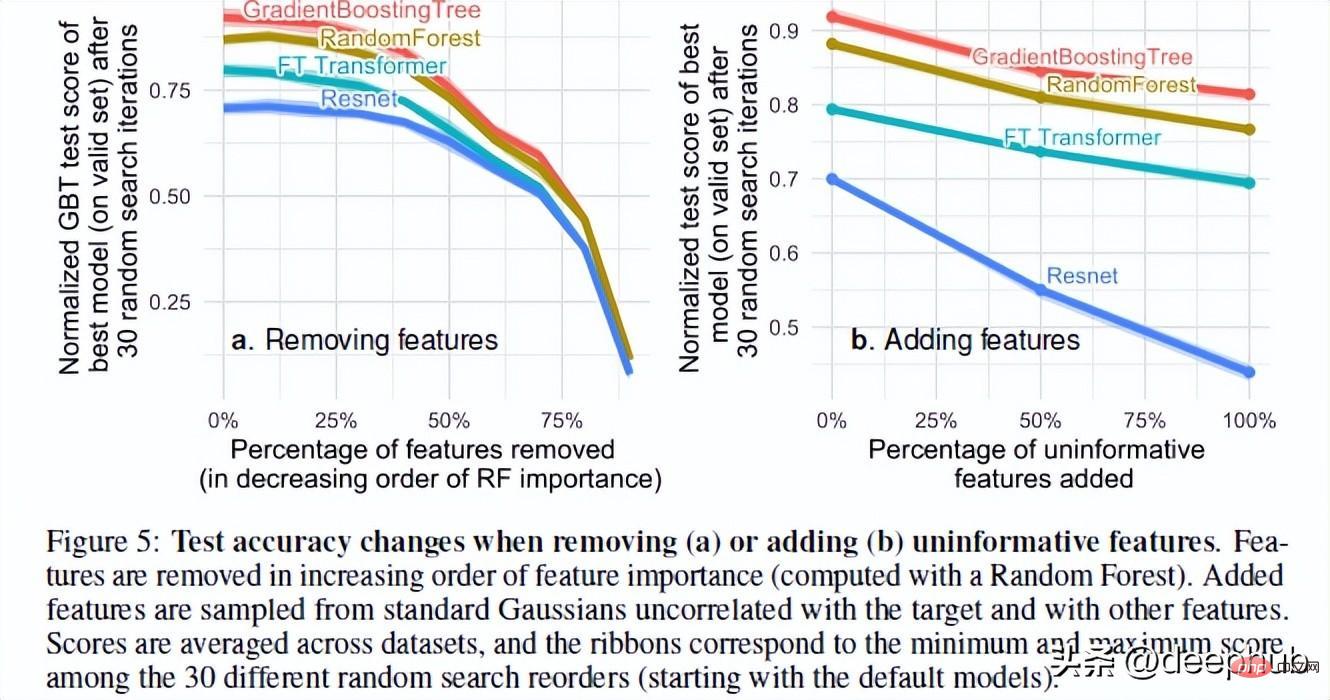
この現象について考えられる説明の 1 つは、デシジョン ツリーの設計方法です。 AI コースを受講したことのある人なら誰でも、デシジョン ツリーにおける情報ゲインとエントロピーの概念を知っているでしょう。これにより、デシジョン ツリーは残りの特徴を比較して最適なパスを選択できます。
本題に戻りますが、表形式データに関しては、RF のパフォーマンスが NN より優れていることが最後に 1 つあります。それが回転不変性です。
ニューラル ネットワークは回転不変です。これは、データ セットに対してローテーション操作を実行しても、パフォーマンスが変化しないことを意味します。データセットをローテーションした後、さまざまなモデルのパフォーマンスとランキングが大幅に変化しました。ResNets は常に最悪でしたが、ローテーション後も元のパフォーマンスを維持しましたが、他のすべてのモデルは大きく変化しました。
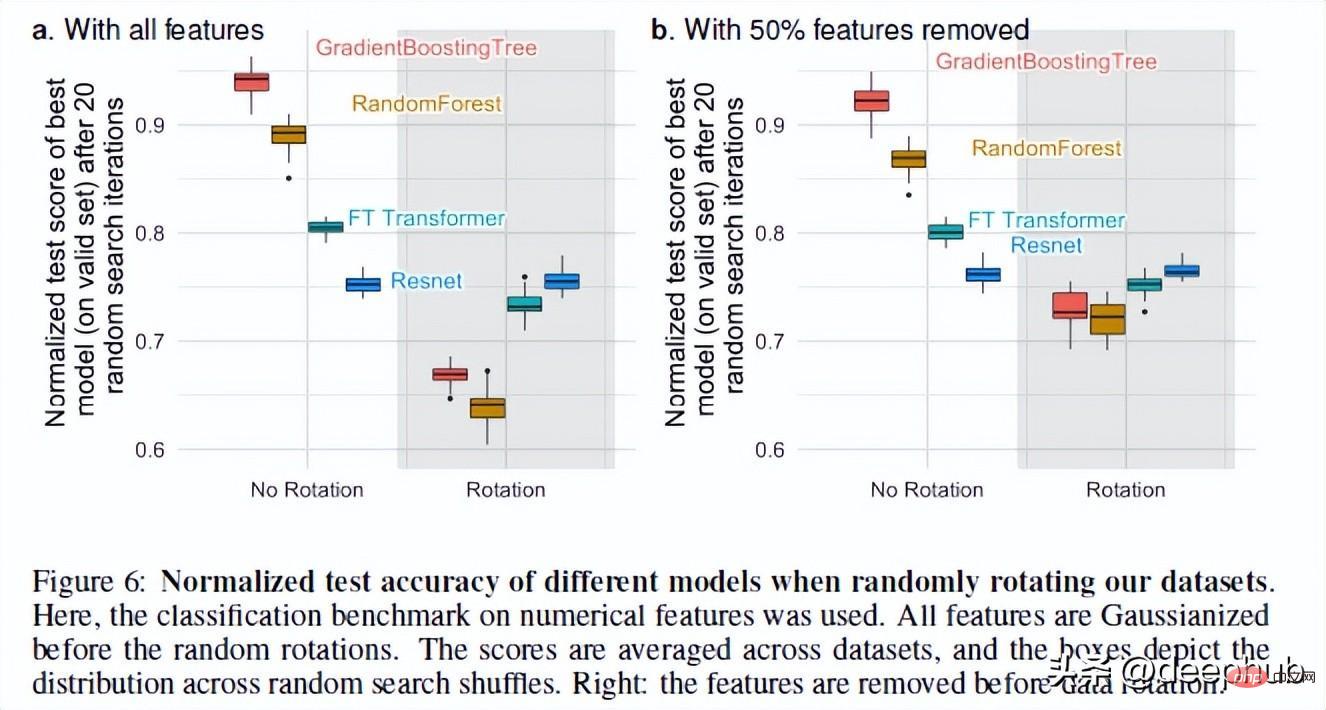
これは非常に興味深いです: データ セットを回転するとは、具体的には何を意味しますか? 論文全体には詳細な説明がありません (著者に連絡しましたので、フォローアップします)この現象)。ご意見がございましたら、コメント欄で共有してください。
しかし、この操作により、回転の分散がなぜ重要なのかがわかります。著者らによれば、特徴の線形結合 (これが ResNets を不変にする理由です) を採用すると、実際には特徴とその関係が誤って表現される可能性があります。
元のデータをエンコードして最適なデータ バイアスを取得すると、非常に異なる統計的特性を持つ特徴が混在する可能性があり、回転不変モデルでは回復できないため、モデルのパフォーマンスが向上します。
これは非常に興味深い論文です。深層学習はテキストや画像のデータセットでは大きな進歩を遂げましたが、基本的に表形式のデータではまったく利点がありません。この論文では、さまざまなドメインからの 45 のデータセットをテストに使用しており、その結果は、その優れた速度を考慮しなくても、中程度のデータ (約 10,000 サンプル) ではツリーベースのモデルが依然として最先端であることを示しています。
以上がツリーベースのモデルが依然として表形式データでの深層学習よりも優れている理由の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



