


この記事では、mysql に関する関連知識を提供します。主に、一般的なクエリの最適化に関する関連問題を紹介します。一緒に見てみましょう。皆さんのお役に立てれば幸いです。

推奨学習: mysql ビデオ チュートリアル
プログラムがオンラインになって一定期間実行された後、システムの遅延やフリーズなどが発生すると、プログラマやアーキテクトによるシステムチューニングが必要になります。 SQL チューニングの内容は依然として非常に重要な部分です。この記事では、例を組み合わせて、作業に関係する可能性のあるいくつかの SQL 最適化戦略を要約します。
大規模なシステムの場合、ほとんどのシステムでは、読み取りが多くなり、書き込みが少なくなるのが通常です。これは、クエリに含まれる SQL が非常に高頻度の操作であることを意味します。
準備、100,000 を追加します。テスト テーブルへのエントリ データ
次のストアド プロシージャを使用して、単一テーブルのデータのバッチを作成します。テーブルを独自のテーブルに置き換えるだけです
create procedure addMyData() begin declare num int; set num =1; while num <= 100000 do insert into XXX_table values( replace(uuid(),'-',''),concat('测试',num),concat('cs',num),'123456' ); set num =num +1; end while; end ;
その後、ストアド プロシージャを呼び出します
call addMyData();
この記事では、student テーブル、class (class) テーブル、account テーブルの 3 つのテーブルを用意し、それぞれにテスト用のデータが 500,000、10,000、100,000 個あります。 ;

ページング クエリは開発中によく発生します。ページングの数が非常に多い場合、クエリには非常に時間がかかることがよくあります。たとえば、次の SQL クエリを使用して Student テーブルをクエリすると、0.2 秒かかります;

# 実際の経験から、後ろになるほどページング クエリの効率が低下することがわかります。これがページング クエリの問題です。 ページング クエリを実行するときに、 を実行すると、制限 400000,10 、現時点では MySQL 4000 10 note が必要です。レコードの場合、400000 - 4 00010 レコードのみが返され、他のレコードは破棄されます。クエリの並べ替えコストは非常に高くなります。
通常、ページング クエリを実行するときは、カバー インデックスを作成することをお勧めします。パフォーマンスを向上させるには、カバー インデックスとサブクエリを通じて最適化できます。
SELECT * FROM student t1,(SELECT id FROM student ORDER BY id LIMIT 400000,10) t2 WHERE t1.id =t2.id;
执行上面的sql,可以看到响应时间有一定的提升;
2)对于主键自增的表,可以把Limit 查询转换成某个位置的查询
select * from student where id > 400000 limit 10;
执行上面的sql,可以看到响应时间有一定的提升;
2、关联查询优化
在实际的业务开发过程中,关联查询可以说随处可见,关联查询的优化核心思路是,最好为关联查询的字段添加索引,这是关键,具体到不同的场景,还需要具体分析,这个跟mysql的引擎在执行优化策略的方案选择时有一定关系;
2.1 左连接或右连接
下面是一个使用left join 的查询,可以预想到这条sql查询的结果集非常大
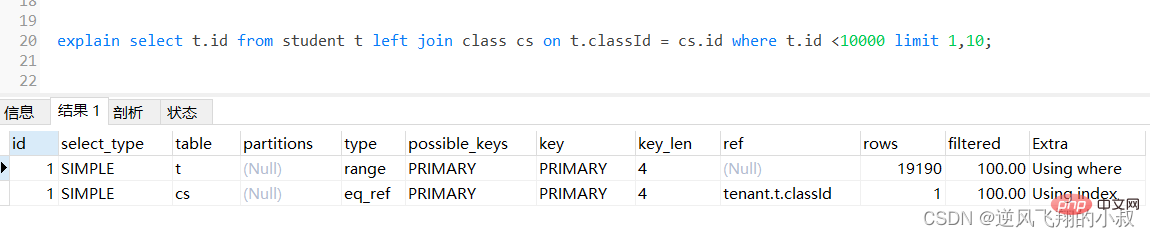
select t.* from student t left join class cs on t.classId = cs.id;ログイン後にコピー为了检查下sql的执行效率,使用explain做一下分析,可以看到,第一张表即left join左边的表student走了全表扫描,而class表走了主键索引,尽管结果集较大,还是走了索引;
针对这种场景的查询,思路如下:
- 让查询的字段尽量包含在主键索引或者覆盖索引中;
- 查询的时候尽量使用分页查询;
关于左连接(右连接)的explain结果补充说明
- 左连接左边的表一般为驱动表,右边的表为被驱动表;
- 尽可能让数据集小的表作为驱动表,减少mysql内部循环的次数;
- 两表关联时,explain结果展示中,第一栏一般为驱动表;
2.2 关联查询关联的字段建立索引
看下面的这条sql,其关联字段非表的主键,而是普通的字段;
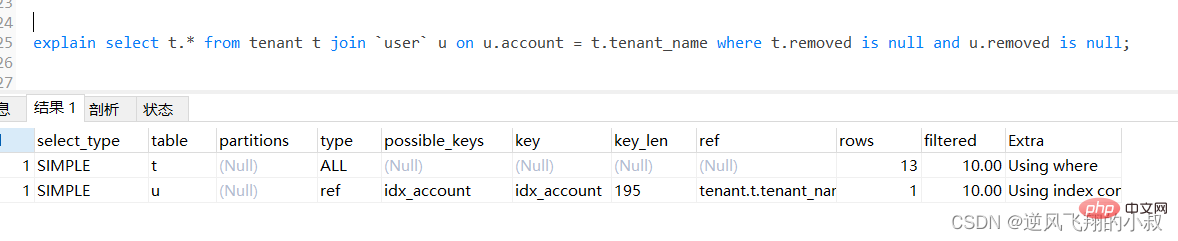
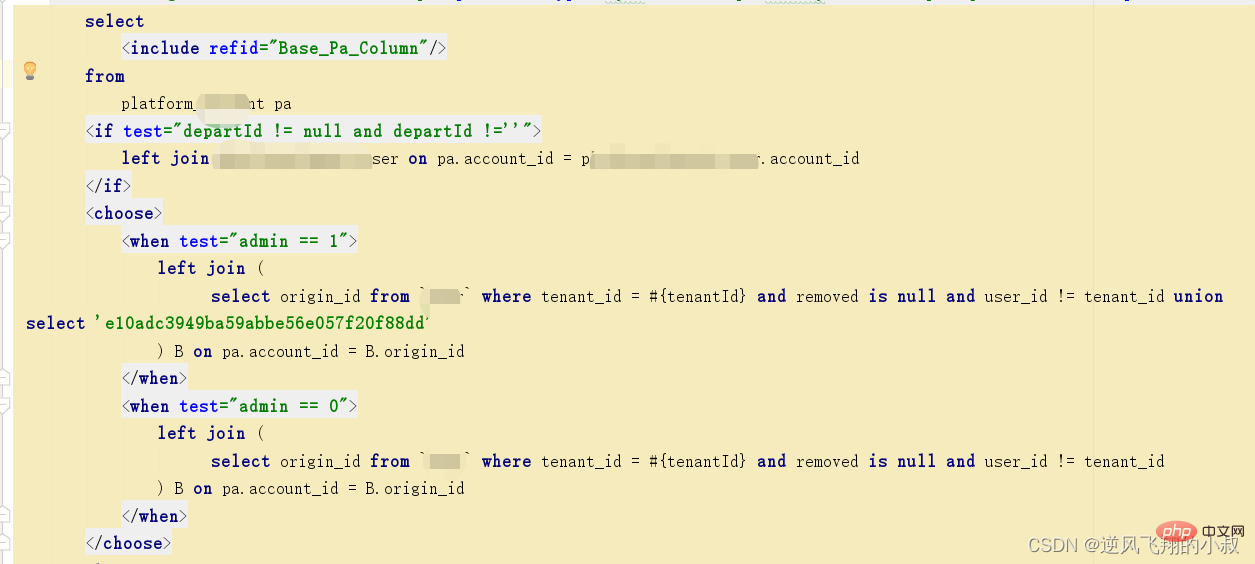
explain select u.* from tenant t left join `user` u on u.account = t.tenant_name where t.removed is null and u.removed is null;ログイン後にコピー
通过explain分析可以发现,左边的表走了全表扫描,可以考虑给左边的表的tenant_name和user表的account 各自创建索引;
create index idx_name on tenant(tenant_name);
create index idx_account on `user`(account);
再次使用explain分析结果如下
可以看到第二行type变为ref,rows的数量优化比较明显。这是由左连接特性决定的,LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引 。
2.3 内连接关联的字段建立索引
我们知道,左连接和右连接查询的数据分别是完全包含左表数据,完全包含右表数据,而内连接(inner join 或join) 则是取交集(共有的部分),在这种情况下,驱动表的选择是由mysql优化器自动选择的;
在上面的基础上,首先移除两张表的索引
ALTER TABLE `user` DROP INDEX idx_account;
ALTER TABLE `tenant` DROP INDEX idx_name;使用explain语句进行分析
然后给user表的account字段添加索引,再次执行explain我们发现,user表竟然被当作是被驱动表了;
此时,如果我们给tenant表的tenant_name加索引,并移除user表的account索引,得出的结果竟然都没有走索引,再次说明,使用内连接的情况下,查询优化器将会根据自己的判断进行选择;
3、子查询优化
子查询在日常编写业务的SQL时也是使用非常频繁的做法,不是说子查询不能用,而是当数据量超出一定的范围之后,子查询的性能下降是很明显的,关于这一点,本人在日常工作中深有体会;
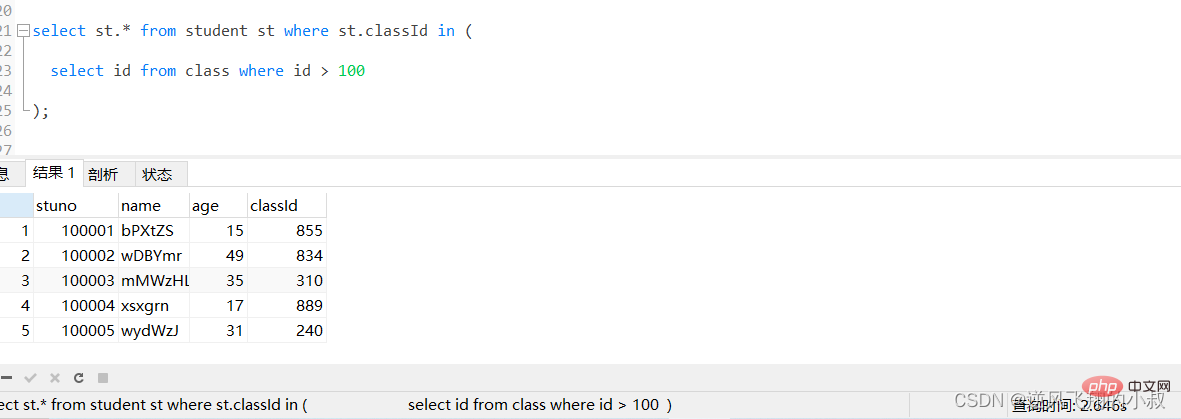
比如下面这条sql,由于student表数据量较大,执行起来耗时非常长,可以看到耗费了将近3秒;
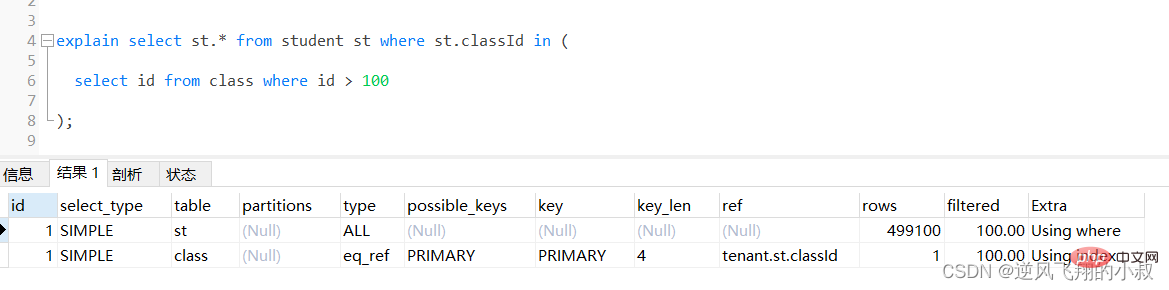
select st.* from student st where st.classId in ( select id from class where id > 100 );ログイン後にコピー
通过执行explain进行分析得知,内层查询 id > 100的子查询尽管用上了主键索引,但是由于结果集太大,带入到外层查询,即作为in的条件时,查询优化器还是走了全表扫描;
针对上面的情况,可以考虑下面的优化方式
select st.id from student st join class cl on st.classId = cl.id where cl.id > 100;
子查询性能低效的原因
- 子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表 ,然后外层查询语句从临时表中查询记录,查询完毕后,再撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询;
- 子查询结果集存储的临时表,不论是内存临时表还是磁盘临时表都不能走索引 ,所以查询性能会受到一定的影响;
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大;
使用mysql查询时,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表 ,其速度比子查询要快 ,如果查询中使用索引的话,性能就会更好,尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代;
一个真实的案例
在下面的这段sql中,优化前使用的是子查询,在一次生产问题的性能分析中,发现某个tenant_id下的数据达到了35万多,这样直接导致某个列表页面的接口查询耗时达到了5秒左右;
找到了问题的根源后,尝试使用上面的优化思路进行解决即可,优化后的sql大概如下,
4、排序(order by)优化
在mysql,排序主要有两种方式
- Using filesort : 通过表索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort
buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序;- Using index : 通过有序的索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高;
对于以上两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index
4.1 使用age字段进行排序
由于age字段未加索引,查询结果按照age排序的时候发现使用了filesort,排序性能较低;
给age字段添加索引,再次使用order by时就走了索引;
4.2 使用多字段进行排序
通常在实际业务中,参与排序的字段往往不只一个,这时候,就可以对参与排序的多个字段创建联合索引;
如下根据stuno和age排序
给stuno和age添加联合索引
create index idx_stuno_age on `student`(stuno,age);
再次分析时结果如下,此时排序走了索引
关于多字段排序时的注意事项
1)排序时,需要满足最左前缀法则,否则也会出现 filesort;
上で作成した結合インデックスの順序は stuno と age です。つまり、stuno が前で、age が後ろです。クエリ中に並べ替え順序が変更された場合はどうなりますか?結果を分析したところ、filesort が使用されていることがわかりました。
2) 並べ替えの際、並べ替えの種類は一貫したままです
フィールドの並べ替えを維持しながら、順序が変更されない場合、デフォルトでは、両方が昇順または降順であれば、order by でインデックスを使用できます。一方が昇順で、もう一方が降順の場合はどうなりますか?分析の結果、この場合にも filesort が使用されることが判明しました;
5. Group by 最適化
group by の最適化戦略と order の最適化戦略by 最適化戦略は非常に似ており、主な点は次のとおりです:
5.1 group by フィールドにインデックスを追加します。インデックスが作成されていない場合の分析結果は次のとおりです この結果のパフォーマンスは明らかに非常に非効率です
- group by インデックスを使用するフィルター条件がない場合でも、インデックスを直接使用することもできます。
group by 最初にソートし、次にグループ化します。インデックス構築には最も左のプレフィックス ルールに従います。- インデックス列が使用できない場合は、max_length_for_sort_data パラメータと sort_buffer_size パラメータの設定を増やします。
- where は、have よりも効率的で、where 制限内に記述できますhave に条件を記述しないでください;
- order by の使用を減らし、可能であればソートしない、またはソートを入れますプログラム内で。 Order by、group by、distinct などのステートメントはより多くの CPU を消費し、データベースの CPU リソースは非常に貴重です。
- SQL に order by、group by、distinct などのクエリ ステートメントが含まれる場合、 where 条件でフィルタリングされた結果セット 1000 行以内にしてください、そうしないと SQL が非常に遅くなります;
# stuno にインデックスを追加した後
## stuno と age にジョイント インデックスを追加
最適な左のプレフィックスに従わない場合、パフォーマンスによるグループ化は比較的非効率になります
## 最も左のプレフィックスをたどる状況は以下のようになります
6. カウントの最適化
使用法: count (*)、count (主キー)、count (フィールド)、count (数値)
count() は集計関数です返された結果セットは行ごとに判定され、 count 関数のパラメータが NULL でない場合は累積値に 1 が加算され、それ以外の場合は加算されず、最終的に累積値が返されます。
以下は、count を記述するいくつかの方法の詳細な説明です
#使用法#手順
効率の良い順に、 count(field) 推奨学習:
count (主キー) InnoDB はテーブル全体を走査します。各行の主キー ID 値を取り出してサービス層に返します。サービス層は主キーを取得した後、それを行ごとに直接蓄積します (主キーは null です); count(*) InnoDB はすべてのフィールドを取得するわけではありませんが、特別に最適化されています。値を取得せずに、サービス層が直接 を押します。行が蓄積されます。 count (field) not null 制約なし: InnoDB エンジンはテーブル全体を走査し、各行のフィールド値を取り出してサービス層に返します。 , サービス層が null かどうかを判断し、カウントが累積されます。not null 制約があります。InnoDB エンジンはテーブル全体を走査し、各行のフィールド値を取り出し、それを返します。サービス層を検索し、それを行ごとに直接蓄積します; count (数値) InnoDB エンジンは、値を取得せずにテーブル全体を走査します。サービス層は返された各行に数値「1」を入れ、行ごとに直接累積します; 経験値の概要
mysql ビデオ チュートリアル以上がMySql の一般的なクエリ最適化戦略の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



