この記事では、Python に関する関連知識をお届けします。主に、Python クローラーがどのように Web ページ データをクロールし、データを解析して、クローラーをより効果的に使用して Web ページを分析できるかを紹介します。一緒にやってみましょう。見てください、それが皆さんのお役に立てば幸いです。

#[関連する推奨事項:
Python3 ビデオ チュートリアル ]
1. Web クローラーの基本概念
Web クローラー (Web スパイダーおよびロボットとも呼ばれます) は、クライアントがネットワーク リクエストを送信し、リクエスト応答を受信することをシミュレートし、特定のルールに従ってインターネット情報を自動的に取得するプログラムです。
ブラウザができることであれば、原理的にはクローラでもできます。
2. Web クローラーの機能
Web クローラーは、検索エンジンなどの多くのものを手動で置き換えることができます。 Web サイト上の写真。たとえば、友人が特定の Web サイト上のすべての写真をクロールして、一緒に閲覧します。同時に、Web クローラーは金融投資の分野でも使用できます。たとえば、一部の金融情報や金融情報を自動的にクロールできます。投資分析等を実施します。
お気に入りのニュース Web サイトが複数ある場合がありますが、閲覧するたびにこれらのニュース Web サイトを個別に開くのは面倒です。このとき、Web クローラーを使用すると、これら複数のニュース サイトのニュース情報をクローリングして、まとめて読むことができます。
Web 上の情報を閲覧すると、大量の広告が表示されることがあります。このとき、クローラーを使用して、対応する Web ページ上の情報をクロールすることもできます。これにより、これらの広告が自動的に除外され、情報の読み取りと使用が容易になります。
マーケティングを実施する必要がある場合、ターゲット顧客とその連絡先情報をどのように見つけるかが重要な問題になります。インターネットで手動で検索することもできますが、これは非常に非効率的です。現時点では、クローラーを使用して対応するルールを設定し、マーケティング利用のためにターゲット ユーザーの連絡先情報やその他のデータをインターネットから自動的に収集できます。
ウェブサイトのユーザーアクティビティ、コメント数、人気記事、その他の情報の分析など、特定のウェブサイトのユーザー情報を分析したい場合があります。ウェブサイト管理者ではない場合は、手動統計を使用してください。非常に困難な仕事になるでしょう、巨大なプロジェクトです。現時点では、クローラを使用すると、さらなる分析のためにこれらのデータを簡単に収集できます。すべてのクローリング操作は自動的に実行されます。対応するクローラを作成し、対応するルールを設計するだけで済みます。
さらに、クローラーは多くの強力な機能も実現できます。つまり、クローラの登場により、手動によるWebページへのアクセスがある程度代替できるため、これまで手動でインターネット情報にアクセスしていた作業をクローラによって自動化することができ、インターネット上の有効な情報をより効率的に利用できるようになります。 。
3. サードパーティ ライブラリのインストール
データをクロールしてデータを解析する前に、Python 実行環境にサードパーティ ライブラリ リクエストをダウンロードしてインストールする必要があります。
Windows システムでは、cmd (コマンド プロンプト) インターフェイスを開き、インターフェイスに pip install リクエストを入力し、Enter キーを押してインストールします。 (ネットワーク接続に注意してください) 以下に示すように
写真に示すように、インストールは完了です
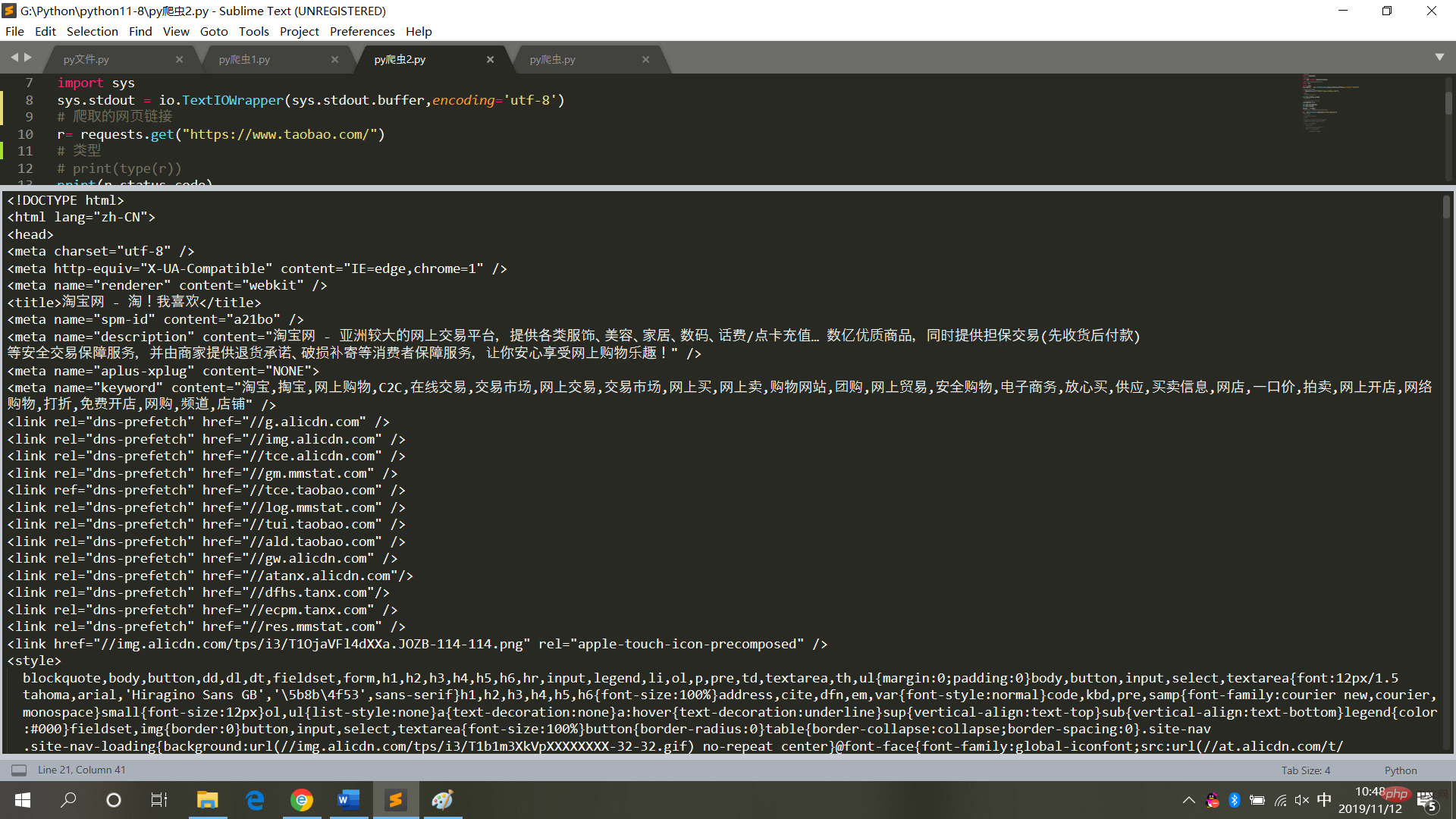
4. タオバオのホームページをクロールします# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.textログイン後にコピー
実行結果は図に示すとおりです
5. クロールタオバオのホームページを解析します# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)ログイン後にコピー
図
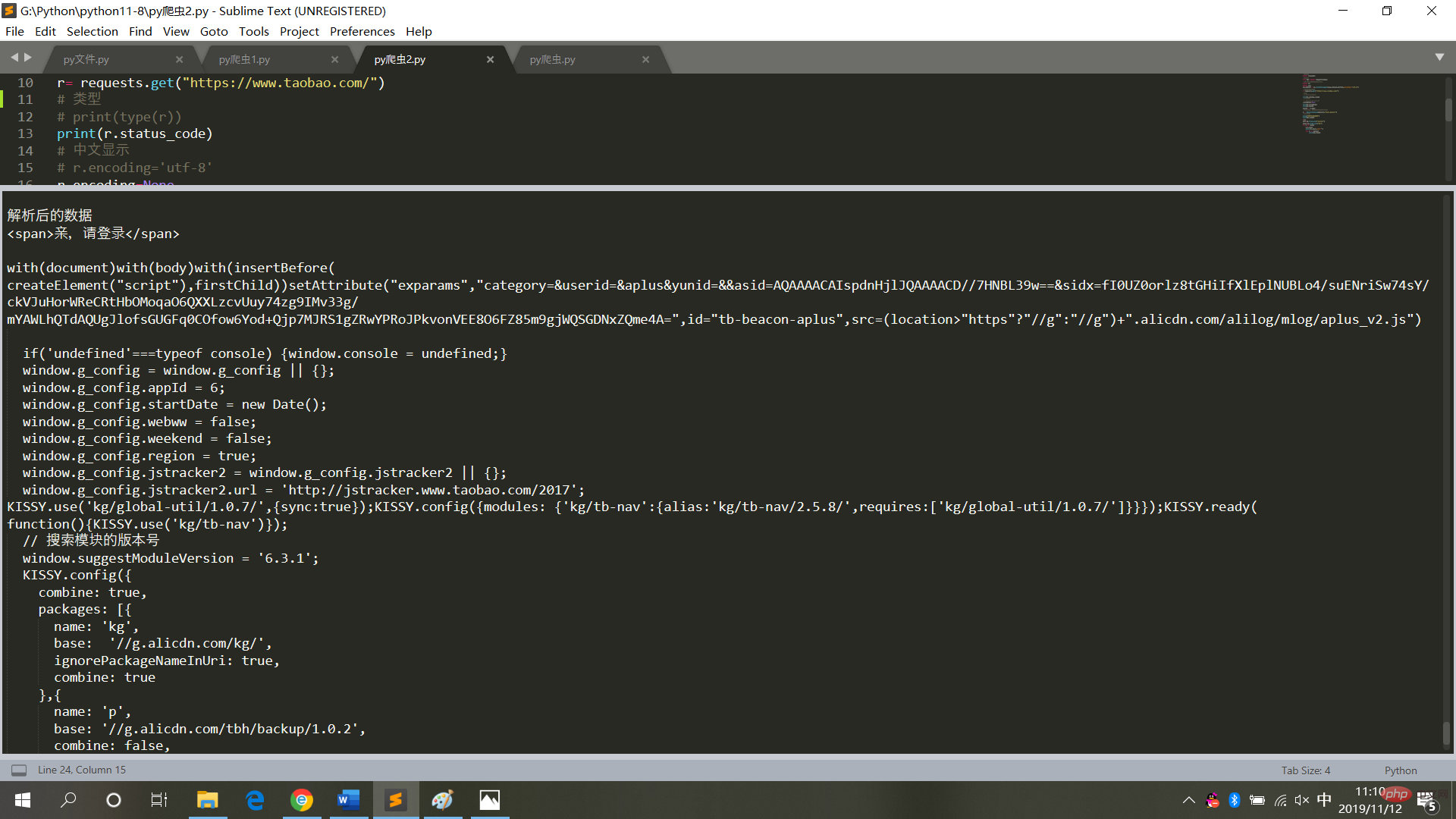
6に示すように、実行結果が表示されます。 Web ページのコードをクロールするときは、頻繁に操作を行わず、無限ループ モードに設定しないでください (各クロールは Web ページへのアクセスであり、頻繁に操作するとシステムがクラッシュし、法的責任が発生します)追求される)。
したがって、Web ページ データを取得した後、それをローカル テキスト モードで保存し、解析します (Web ページにアクセスする必要はなくなります)。
【関連する推奨事項:
Python3 ビデオ チュートリアル
]
以上がPython クローラーは Web ページのデータをクロールし、データを解析しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



