


この記事では、mysql に関する関連知識を提供し、主に mysql ディープ ページングの問題に対するエレガントなソリューションを紹介します。この記事では、mysql テーブルに大量のデータがある場合にディープ ページングを最適化する方法について説明します。ページネーションの問題、および遅い SQL の問題を最適化する最近の事例の疑似コードを添付します。

推奨学習: mysql ビデオ チュートリアル
日々の需要の開発プロセスでは、制限については誰もがよく知っていると思いますが、制限を使用すると、オフセット (オフセット) が非常に大きい場合、クエリの効率がどんどん遅くなることがわかります。最初の制限が 2000 の場合、必要なデータのクエリに 200 ミリ秒かかる場合がありますが、制限が 4000 オフセット 100000 の場合、クエリの効率はすでに約 1 秒を必要としていることがわかります。ますます悪くなり、遅い。
この記事では、mysql テーブルに大量のデータがある場合にディープ ページング問題を最適化する方法について説明し、遅い SQL 問題を最適化する最近の事例の疑似コードを添付します。 。
最初にテーブル構造を見てみましょう (例を挙げるだけです。テーブル構造は不完全で、無駄なフィールドは表示されません)
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
クエリしたいディープ ページング SQL が次のようになっているとします。
select * from p2p_detail_record ppdr where ppdr .start_time_stamp >1656666798000 limit 0,2000

クエリ効率は 94 ミリ秒ですが、非常に高速です。したがって、100000 または 2000 に制限すると、クエリ効率は 1.5 秒となり、これはすでに非常に遅いことになります。

 もインデックスに到達しましたが、それでも遅いのはなぜですか?まず、mysql の関連知識ポイントを確認しましょう。
もインデックスに到達しましたが、それでも遅いのはなぜですか?まず、mysql の関連知識ポイントを確認しましょう。
クラスター化インデックスと非クラスター化インデックス
クラスター化インデックス:リーフ ノードにはデータの行全体が格納されます。
非クラスター化インデックス:リーフ ノードには、データ行全体に対応する主キー値が格納されます。
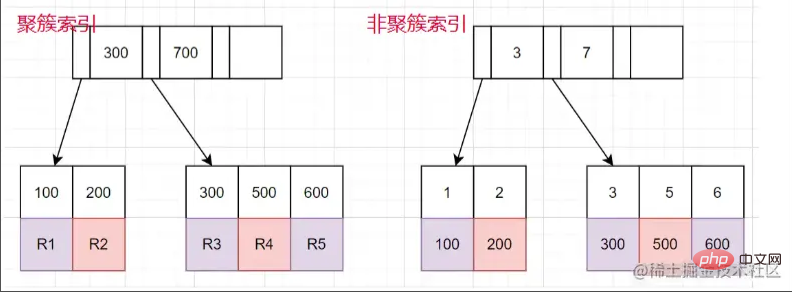 #非クラスター化インデックス クエリを使用するプロセス
#非クラスター化インデックス クエリを使用するプロセス
非クラスター化インデックスを使用して、対応するリーフ ノードを検索します。 Tree 、主キーの値を取得します。
limit 100000,10
は 100010 行をスキャンしますが、limit 0,10 は 10 行のみをスキャンします。ここでは 100010 回テーブルに戻る必要があり、テーブルを返すのに多くの時間がかかります。 ソリューションの核となるアイデア:
共通ソリューション
サブクエリによる最適化select * from p2p_detail_record ppdr where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1) limit 2000
タグ記録方法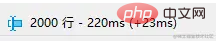
ブックマークの効果と同様です
select * from p2p_detail_record ppdr where ppdr.id > 'bb9d67ee6eac4cab9909bad7c98f54d4' order by id limit 2000 备注:bb9d67ee6eac4cab9909bad7c98f54d4是上次查询结果的最后一条ID
欠点があります。 1. クエリは連続したページでのみ実行でき、ページをまたいで実行することはできません。
欠点:
はタグ記録方法 ほど効率的ではありません。 理由: たとえば、100,000 個のデータをチェックする必要がある場合、最初に非クラスター化インデックスに対応する 1000 番目のデータをクエリしてから、100,000 番目から始まる ID を取得する必要もあります。クエリ用の部分。
タグ記録方式を使用します欠点:
关于第二点的说明: 该点一般都好解决,可使用任意不重复的字段进行排序即可。若使用可能重复的字段进行排序的字段,由于mysql对于相同值的字段排序是无序,导致如果正好在分页时,上下页中可能存在相同的数据。
需求: 需要查询查询某一时间段的数据量,假设有几十万的数据量需要查询出来,进行某些操作。
需求分析 1、分批查询(分页查询),设计深分页问题,导致效率较慢。
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
伪代码实现:
//最小ID
String lastId = null;
//一页的条数
Integer pageSize = 2000;
List<P2pRecordVo> list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id
lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录
//对数据的操作逻辑
XXXXX();
}while(isNotEmpty(list));
<select id ="listP2pRecordByPage">
select *
from p2p_detail_record ppdr where 1=1
<if test = "lastId != null">
and ppdr.id > #{lastId}
</if>
order by id asc
limit #{pageSize}
</select>这里有个小优化点: 可能有的人会先对所有数据排序一遍,拿到最小ID,但是这样对所有数据排序,然后去min(id),耗时也蛮长的,其实第一次查询,可不带lastId进行查询,查询结果也是一样。速度更快。
1、当业务需要从表中查出大数据量时,而又项目架构没上ES时,可考虑使用标签记录法的方式,对查询效率进行优化。
2、从需求上也应该尽可能避免,在大数据量的情况下,分页查询最后一页的功能。或者限制成只能一页一页往后划的场景。
推荐学习:mysql视频教程
以上がmysqlのディープページング問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



