


この記事では、Pythonに関する関連知識を提供します, 主に Web 画像のクロールに関連する問題を整理します. データを効率的に取得するために、クローラーは非常に使いやすく、Python を使用してクローラーを作成しますも非常に簡単で便利です。簡単な小さなクローラー プログラムを通して、クローラーを作成する基本的なプロセスを見てみましょう。一緒に見てみましょう。皆さんのお役に立てれば幸いです。

[関連する推奨事項:Python3 ビデオ チュートリアル]
この情報爆発の時代において、効率的にデータを取得したい場合は、クローラーはとても便利です。 Python を使用してクローラを作成することも非常に簡単で便利です。単純な小さなクローラ プログラムを通じて、クローラを作成する基本プロセスを見てみましょう:
Language: python
IDE: pycharm
最初に使用するライブラリは、初心者向けの最も簡単なプログラムなので、主に次の 2 つを使用します。 #
import requests //用于请求网页 import re //正则表达式,用于解析筛选网页中的信息
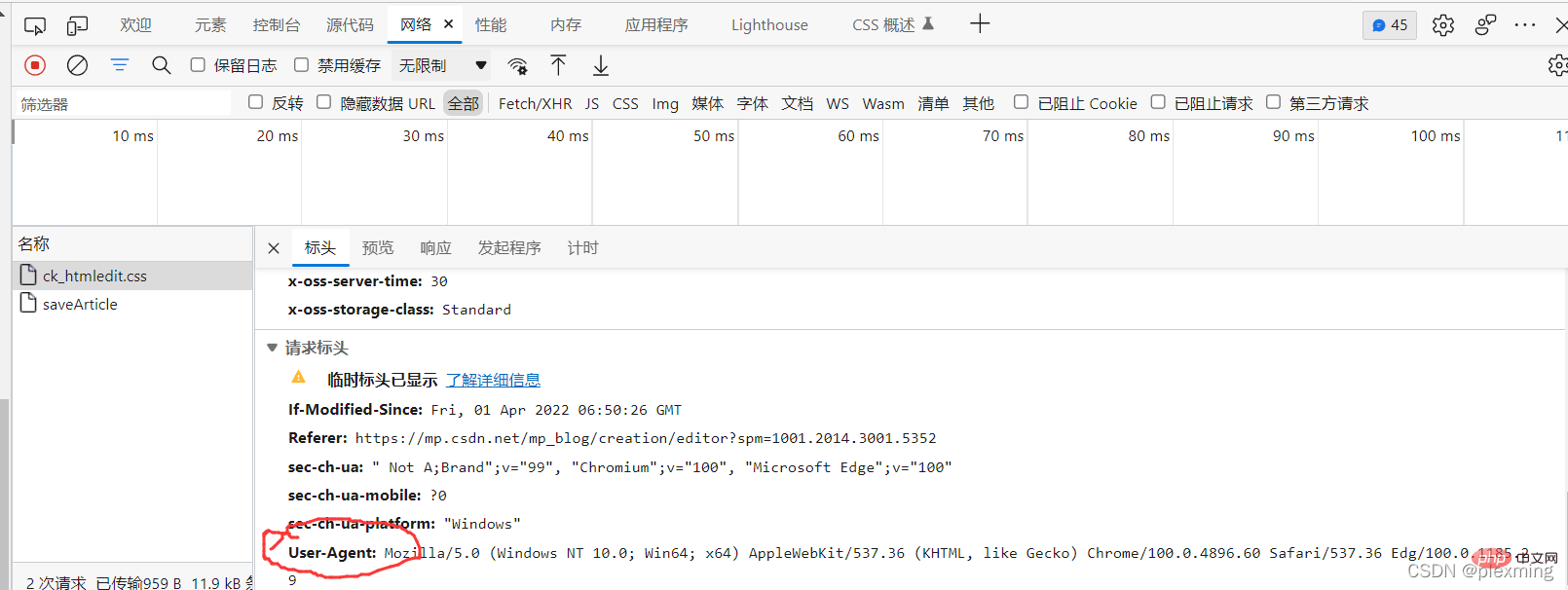
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0' } response = requests.get('https://qq.yh31.com/zjbq/',headers=headers) //请求网页
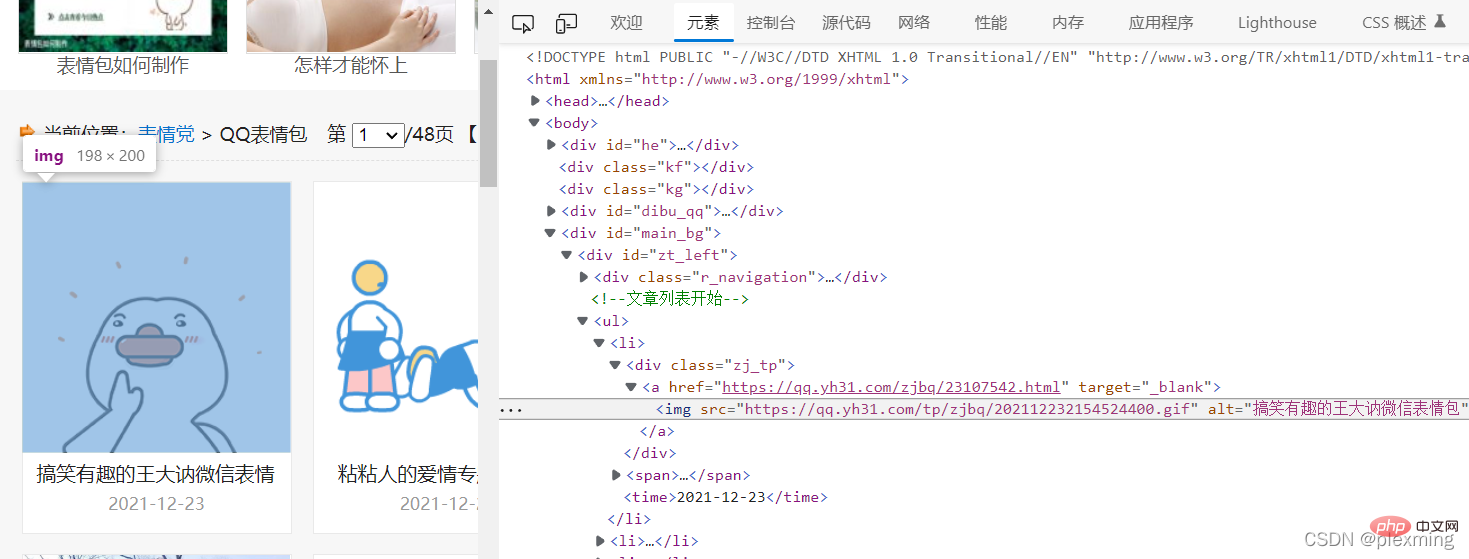 ## 次に、一致ルールを作成し、中央の文字列を正規表現に置き換えます。最も単純なものは、*?
## 次に、一致ルールを作成し、中央の文字列を正規表現に置き換えます。最も単純なものは、*?
t = ''
のようになります。
その後、re ライブラリの findall メソッドを呼び出して、関連するコンテンツをクロール ダウンできます:
result = re.findall(t, response.text)
返されたコンテンツは文字列で構成されるリストです。最後に、Python を使用してアドレスにクロールしました。画像をダウンロードしてフォルダーに保存するだけです。
プログラム コード
import requests import re import os image = '表情包' if not os.path.exists(image): os.mkdir(image) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0' } response = requests.get('https://qq.yh31.com/zjbq/',headers=headers) response.encoding = 'GBK' response.encoding = 'utf-8' print(response.request.headers) print(response.status_code) t = '' result = re.findall(t, response.text) for img in result: print(img) res = requests.get(img[0]) print(res.status_code) s = img[0].split('.')[-1] #截取图片后缀,得到表情包格式,如jpg ,gif with open(image + '/' + img[1] + '.' + s, mode='wb') as file: file.write(res.content)
##[関連する推奨事項: Python3 ビデオ チュートリアル
Python3 ビデオ チュートリアル
以上がPython クローラーの入門: Web 画像のクロールの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



