


この記事では、mysql に関する関連知識を提供します。主に、マスター スレーブ遅延とは何か、マスター スレーブ遅延の原因など、マスター スレーブ遅延の解決に関連する問題を整理します。マスタースレーブ遅延の解決策などをご覧ください。皆様のお役に立てれば幸いです。

推奨される学習: mysql ビデオ チュートリアル
以前のプロジェクトでは、MySQL のマスター/スレーブ レプリケーションに基づいて読み取りと書き込みの分離が実現されました。と AOP. も、この実装プロセスを記録するブログを書きました。 MySQL のマスタースレーブレプリケーションを構成しているため、当然マスタースレーブ遅延が発生しますが、マスタースレーブ遅延によるアプリケーションシステムへの影響をいかに最小限に抑えるかが重要な考え方となります。 MySQL のマスター/スレーブ レプリケーションの本質である読み取りと書き込みの分離を実装します。
このテーマについては、実は以前からブログに書いて共有しようと思っていたのですが、議題には入れていませんでした。最近、読者が「SpringBoot Implements MySQL Read-Write Separation」でこの質問をするメッセージを残しました。これも私がこの記事を書くきっかけになりました。この件に関しては、色々な情報やブログを読み、自分自身の実践を通して、上司の肩に乗ってこのブログにまとめてみました。
マスター/スレーブ遅延の解決方法について説明する前に、まずマスター/スレーブ遅延とは何かを理解しましょう。
マスター/スレーブ レプリケーションを完了するには、スレーブ ライブラリは、I/O スレッドを通じてマスター ライブラリのダンプ スレッドによって読み取られたバイナリ ログ コンテンツを取得し、それを独自のリレー ログに書き込む必要があります。その場合、スレーブ ライブラリの SQL スレッドは、リレー ログを読み取り、リレー ログ内のログを再実行することは、SQL を再度実行し、独自のデータベースを更新して データの一貫性を実現することと同じです。
データ同期に関連する時点には、主に次の 3 つの時点が含まれます。T3 - T1です。
show smile status コマンドを実行すると、その戻り結果に 秒_behind_master が表示されます。これは、現在のスタンバイ データベースの秒数を示すために使用されます。データベースが遅れています。
seconds_behind_master 計算方法は次のとおりです。
を取得します。
T2 - T1## の値になります。 # は非常に小さいです。つまり、通常のネットワーク条件下では、マスター/スレーブ遅延の主な原因は、スレーブ ライブラリがバイナリを受信してからトランザクションを実行するまでの時間差です。 マスター/スレーブ遅延の存在により、データがマスター ライブラリに書き込まれたばかりであることがわかりますが、スレーブ ライブラリと同期されていない可能性があるため、結果が見つからないことがあります。マスターとスレーブの遅延が深刻であればあるほど、この問題はより顕著になります。
マスター/スレーブ遅延の原因
を紹介します。
semi-sync 半同期レプリケーション「非同步複製」:MySQL 預設的複製即是異步的,主庫執行完客戶端提交的交易後會立即將結果回傳給客戶端,並不關心從庫是否已經接收並處理。這樣就會有一個問題,一旦主庫宕機,此時主庫上已經提交的事務可能因為網路原因並沒有傳到從庫上,如果此時執行故障轉移,強行將從提升為主,可能導致新主上的資料不完整。
「全同步複製」:指當主庫執行完一個事務,並且所有的從庫都執行了該事務,主庫才提交事務並傳回結果給客戶端。因為需要等待所有從庫執行完該事務才能返回,所以全同步複製的效能必然會收到嚴重的影響。
「半同步複製」:是介於全同步複製與全異步複製之間的一種,主庫只需要等待至少一個從庫接收到並寫入到Relay Log檔案即可,主庫不需要等待所有從庫到主庫返回ACK。主庫收到這個 ACK 以後,才能傳回給客戶「事務完成」 的確認。
MySQL 預設的複製是異步的,所以主函式庫和從函式庫的資料會有一定的延遲,更重要的是非同步複製可能會造成資料的遺失。但是全同步複製又會使得完成一個事務的時間被拉長,帶來效能的降低。因此我把目光轉向半同步複製。 從 MySQL 5.5 開始,MySQL 以外掛程式的形式支援 semi-sync 半同步複製。
相對於非同步複製,半同步複製提高了資料的安全性,減少了主從延遲,當然它也還是有一定程度的延遲,這個延遲最少是一個 TCP/IP 往返的時間。所以,半同步複製最好在低延時的網路中使用。
要注意的是:
- 主函式庫和從函式庫都要啟用半同步複製才會進行半同步複製功能,否則主函式庫會還原為預設的異步複製。
- 如果在等待過程中,等待時間已經超過了配置的逾時時間,沒有收到任何一個從庫的 ACK,那麼此時主庫會自動轉換為非同步複製。當至少一個半同步從節點趕上來時,主庫就會自動轉換為半同步複製。
在傳統的半同步複製中(MySQL 5.5 引入),主庫寫資料到binlog,並且執行commit 提交交易後,會一直等待一個從庫的ACK,即從庫寫入Relay Log 後,並將數據落盤,再返回給主庫ACK,主庫收到這個ACK 以後,才能給客戶端返回“事務完成” 的確認。
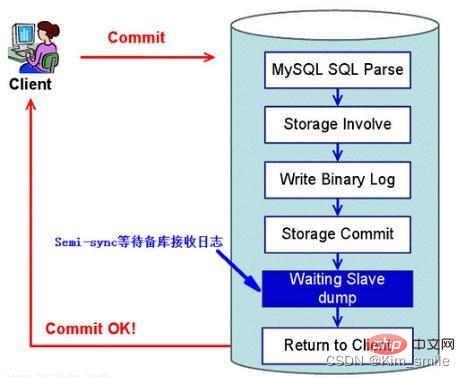
這樣會出現一個問題,就是實際上主庫已經將該事務commit 到了儲存引擎層,應用程式已經可以看到資料發生了變化,只是在等待返回而已。如果此時主庫宕機,可能從庫還沒寫入 Relay Log,就會發生主從庫資料不一致。
為了解決上述問題,MySQL 5.7 引進了增強半同步複製。針對上面這個圖,「Waiting Slave dump」 被調整到了「Storage Commit」 之前,即主庫寫資料到binlog 後,就開始等待從庫的應答ACK,直到至少一個從庫寫入Relay Log 後,並將資料落盤,然後傳回主庫ACK,通知主庫可以執行commit 操作,然後主庫再將交易提交到事務引擎層,應用程式此時才可以看到資料發生了變化。
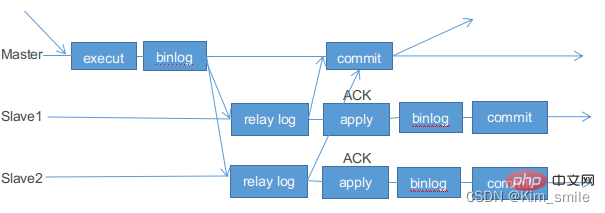
當然之前的半同步方案同樣支持,MySQL 5.7.2 引入了一個新的參數
rpl_semi_sync_master_wait_point進行控制。這個參數有兩種值:
- AFTER_SYNC:這個是新的半同步方案,Waiting Slave dump 在 Storage Commit 之前。
- AFTER_COMMIT:這個是舊的半同步方案。
在 MySQL 5.5 - 5.6 使用 after_commit 的模式下,客戶端事務在儲存引擎層提交後,在主庫等待從庫確認的過程中,主庫宕機了。此時,結果雖然沒有傳回給目前客戶端,但事務已經提交了,其他客戶端會讀取到該已提交的事務。如果從庫沒有接收到該事務或未寫入 relay log,同時主庫宕機了,之後切換到備庫,那麼之前讀到的事務就不見了,出現了幻讀,也就是資料遺失了。
MySQL 5.7 預設值則是 after_sync,主函式庫將每個交易寫入 binlog,傳給從函式庫並刷新到磁碟 (relay log)。主庫等到從庫返回 ack 之後,再提交交易並且返回 commit OK 結果給客戶端。即使主庫crash,所有在主庫上已經提交的交易都能保證已經同步到從庫的relay log 中,解決了after_commit 模式帶來的幻讀和資料遺失問題,故障切換時資料一致性將得到提升。因為從庫沒有寫入成功的話主庫也不會提交事務。並且在 commit 之前等待從庫 ACK,還可以堆積事務,有利於 group commit 群組提交,有利於提升效能。
但這樣也會有個問題,假設主庫在儲存引擎提交之前掛了,那麼很明顯這個事務是不成功的,但由於對應的Binlog 已經做了Sync 操作,從庫已經收到了這些Binlog,並且執行成功,相當於在從庫上多了數據(從庫上有該數據而主庫沒有),也算是有問題的,但多了數據一般不算嚴重的問題。它能保證的是不遺失數據,多了數據總比丟數據好。
如果從庫承擔了大量查詢請求,那麼從庫上的查詢操作將耗費大量的CPU 資源,從而影響了同步速度,造成主從延遲。那我們可以多接幾個從函式庫,讓這些從庫來共同分擔讀的壓力。
簡而言之,就是加機器,方法簡單粗暴,但也會帶來一定成本。
如果某些操作對數據的即時性要求比較苛刻,需要反映即時最新的數據,比如說涉及金錢的金融類系統、線上即時系統、又或者是寫入之後馬上又讀的業務,這時我們就得放棄讀寫分離,讓此類的讀取請求也走主庫,這就不存延遲問題了。
當然這也失去了讀寫分離帶給我們的效能提升,需要適當取捨。
一般 MySQL 主從複製有三個執行緒參與,都是單一執行緒:Binlog Dump 執行緒、IO 執行緒、SQL 執行緒。複製出現延遲一般出在兩個地方:
日誌在備庫上的執行,就是備庫上 SQL 執行緒執行中繼日誌(relay log)更新資料的邏輯。
在 MySQL 5.6 版本之前,MySQL 只支援單執行緒複製,由此在主函式庫並發高、TPS 高時就會出現嚴重的主備延遲問題。 從 MySQL 5.6 開始有了多個 SQL 執行緒的概念,可以並發還原數據,也就是並行複製技術。這可以很好的解決 MySQL 主從延遲問題。
從單執行緒複製到最新版本的多執行緒複製,中間的演化經歷了好幾個版本。其實說到底,所有的多線程複製機制,都是要把只有一個線程的sql_thread,拆成多個線程,也就是都符合下面的這個多線程模型:
coordinator 就是原來的sql_thread,不過現在它不再直接更新資料了,只負責讀取中轉日誌和分發事務。真正更新日誌的,變成了 worker 執行緒。而 worker 執行緒的個數,就是由參數 slave_parallel_workers 決定的。
由於worker 執行緒是並發運行的,為了確保事務的隔離性以及不會出現更新覆蓋問題,coordinator 在分發的時候,需要滿足以下這兩個基本要求:
各個版本的多執行緒複製,都遵循了這兩個基本原則。
以下是按表分發策略和按行分發策略,可以幫助理解 MySQL 官方版本並行複製策略的迭代:
MySQL 5.6 版本,支援了平行複製,只是支援的粒度是按程式庫並行(基於Schema)。
其核心思想是:不同schema 下的表並發提交時的資料不會相互影響,即從庫可以對relay log 中不同的schema各分配一個類似SQL 線程功能的線程,來重播relay log 中主庫已經提交的事務,保持資料與主庫一致。
如果在主函式庫上有多個 DB,使用這個策略對於從函式庫複製的速度可以有比較大的提升。但通常情況下都是單庫多表,那基於函式庫的並發也就沒有什麼作用,根本無法並行重播,所以這個策略用得併不多。
MySQL 5.7 引入了基於群組提交的平行複製,參數slave_parallel_workers 設定並行執行緒數,由參數slave-parallel-type 來控制並行複製原則:
利用binlog 的群組提交(group commit) 機制,可以得出一個群組提交的交易都是可以並行執行的,原因是:能夠在同一組裡提交的事務,一定不會修改同一行(由於MySQL 的鎖定機制),因為事務已經通過鎖定衝突的檢驗了。
基於群組提交的平行複製具體流程如下:
所有處於 prepare 和 commit 狀態的交易都是可以在備庫上並行執行的。
binlog 的群組提交的兩個相關參數:
這兩個參數是用來故意拉長 binlog 從 write 到 fsync 的時間,以此減少 binlog 的寫盤次數。在 MySQL 5.7 的平行複製策略裡,它們可以用來製造更多的「同時處於 prepare 階段的事務」。可以考慮調整這兩個參數值,來達到提升備庫複製並發度的目的。
推薦學習:mysql影片教學
#以上がMySQL マスタースレーブ遅延の解決策を完全にマスターするの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



