


この記事では、mysql に関する関連知識を提供します。主にマスターとスレーブの遅延と読み書きの分離に対する解決策を紹介します。いくつかの方法を見て、まとめてみましょう。皆さんのご協力を願っています。

推奨される学習: mysql ビデオ チュートリアル
インターネット データには特性があり、ほとんどのシナリオは次のようなものであることは誰もが知っています。 Weibo、WeChat、淘宝網などの では、書き込みを減らし、書き込みを少なくします。28 原則 によれば、読み取りトラフィックの割合は 90% に達する可能性もあります。
読み取り/書き込み分離の使用
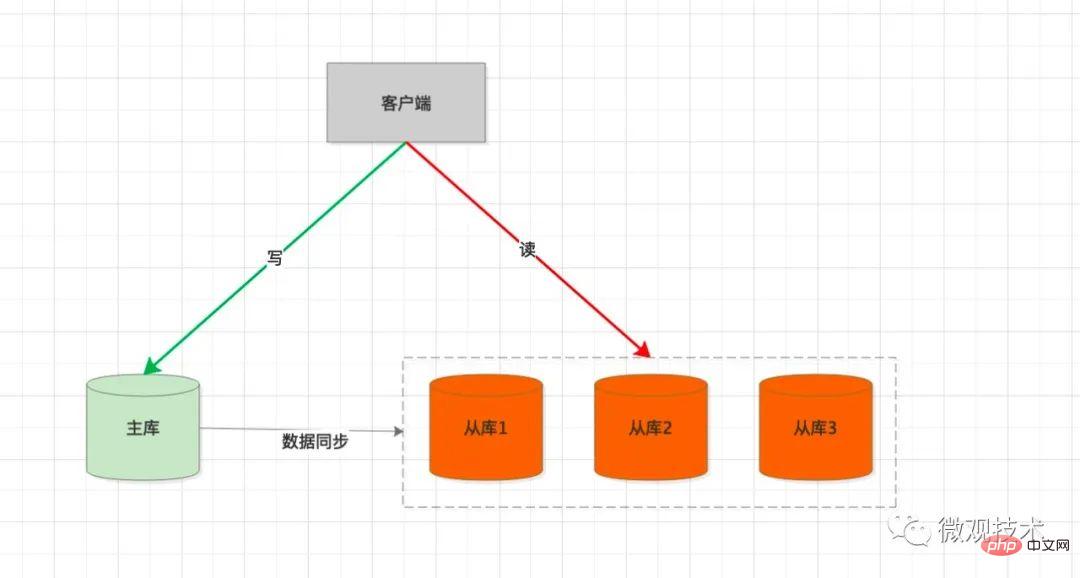
処理プロセス:
writeかreadオペレーション
SQL、リクエストは メイン データベースに送信されます
が生成され、 スレーブ ライブラリ
に同期され、SQL スレッドを通じて binlog が再生されます。スレーブ ライブラリ テーブルに対応するデータを生成します
戦略を渡し、 スレーブ ライブラリでユーザー要求を処理する これは非常に合理的なように思えますが、よく考えてみるとそうではありません。
と
Slave library はデータの非同期レプリケーションを使用します。これら 2 つの場合、ユーザー間のデータが同期されていない場合はどうすればよいですか? メイン ライブラリはデータの書き込みを終えたばかりで、スレーブ ライブラリが最新のデータを取得する前に read リクエストが送信され、ユーザーは
この問題に対して、今日はどのような解決策があるのかについて説明します。 1. メイン データベースの強制使用
未使用のビジネス要件を別の方法で処理する
シナリオ 1:にアクセスできます。 シナリオ 2:
2. スレーブ データベースからのクエリの遅延マスター データベースとスレーブ データベース間のデータ同期には一定の時間間隔が必要なため、スレーブ データベースからのデータのクエリを遅らせる戦略があります。
select sleep(1) select * from order where order_id=11111;
正式なビジネス クエリでは、まず sleep ステートメントを実行して、スレーブ データベース用に特定のデータ同期バッファ期間を予約します。
これは万能のソリューションであるため、同時実行性の高いビジネス シナリオに直面すると、パフォーマンスが大幅に低下するため、通常はこのソリューションはお勧めできません。
3. マスターとスレーブが遅延しているかどうかを判断しますか?マスター ライブラリとスレーブ ライブラリのどちらを選択するかを決定します。
オプション 1:View seconds_behind_master 値 (単位は秒) が 0 の場合、マスター データベースとスレーブ データベースの間に遅延がないことを意味します
オプション 2:
、応答結果にはキー パラメーター
が含まれますMaster_Log_File マスターライブラリから読み込んだ最新のファイル
Read_Master_Log_Pos メインライブラリから読み込んだ最新のファイルの座標位置
Relay_Master_Log_File ライブラリから実行された最新のファイル
Exec_Master_Log_Pos ライブラリから実行された最新のファイルの座標位置
Retrieved_Gtid_Set
とビジネス SQL 操作を実行する場合、最初に最新のデータがデータベースから同期されているかどうかを確認します。マスターデータベースとスレーブデータベースのどちらを操作するかを決定します。 欠点:
这个问题跟 MQ消息队列 既要求高吞吐量又要保证顺序是一样的,从全局来看确实无解,但是缩小范围就容易多了,我们可以保证一个分区内的消息有序。
回到 主从库 之间的数据同步问题,从库查询哪条记录,我们只要保证之前对应的写binglog已经同步完数据即可,可以不用管主从库的所有的事务binlog 是否同步。
问题是不是一下简单多了
在从库执行下面命令,返回是一个正整数 M,表示从库从参数节点开始执行了多少个事务
select master_pos_wait(file, pos[, timeout]);
file 和 pos 表示主库上的文件名和位置
timeout 可选, 表示这个函数最多等待 N 秒
master_pos_wait 返回结果无法与具体操作的数据行做关联,所以每次接收读请求时,从库还是无法确认是否已经同步数据,方案实用性不高。
执行下面查询命令
阻塞等待,直到从库执行的事务中包含 gtid_set,返回 0
超时,返回 1
select wait_for_executed_gtid_set(gtid_set, 1);
MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的 GTID 返回给客户端。具体操作,将参数
session_track_gtids设置为OWN_GTID,调用 API 接口mysql_session_track_get_first返回结果解析出 GTID
发起 写 SQL 操作,在主库成功执行后,返回这个事务的 GTID
发起 读 SQL 操作时,先在从库执行 select wait_for_executed_gtid_set (gtid_set, 1)
如果返回 0,表示已经从库已经同步了数据,可以在从库执行 查询 操作
否则,在主库执行 查询 操作
跟上面的 master_pos_wait 类似,如果 写操作 与 读操作 没有上下文关联,那么 GTID 无法传递 。方案实用性不高。
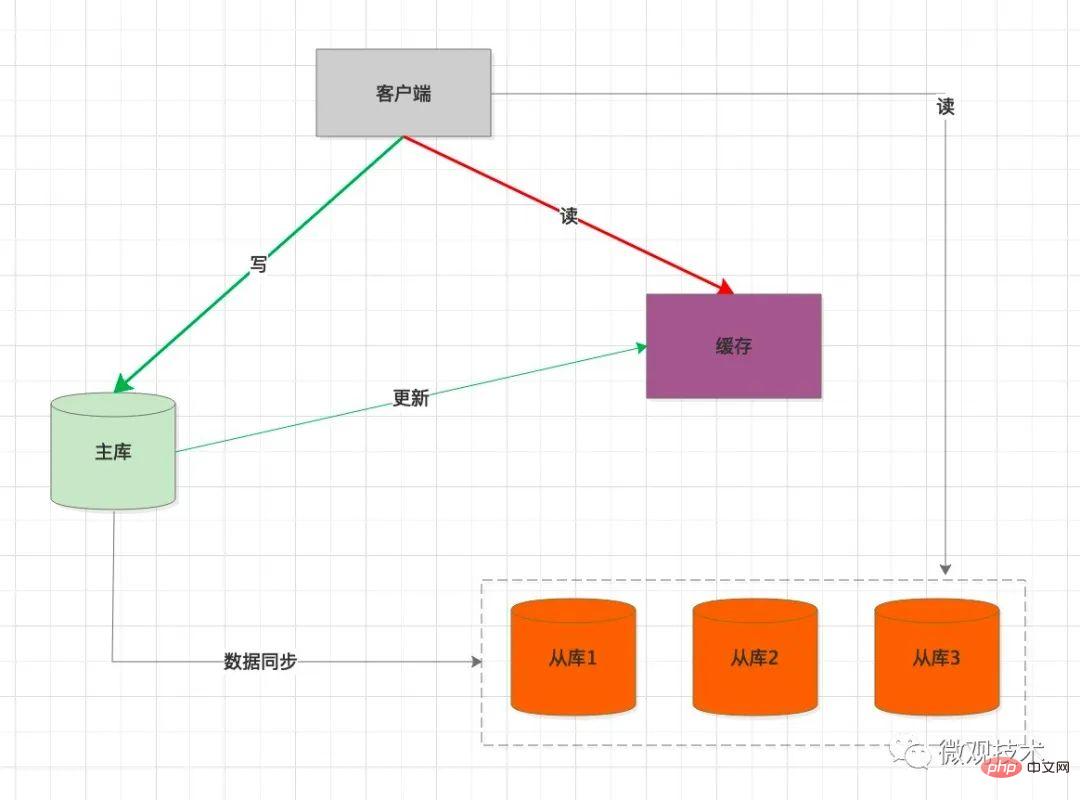
高并发系统,缓存作为性能优化利器,应用广泛。我们可以考虑引入缓存作为缓冲介质
客户端 写 SQL ,操作主库
同步将缓存中的数据删除
当客户端读数据时,优先从缓存加载
如果 缓存中没有,会强制查询主库预热数据
K-V 存储,适用一些简单的查询条件场景。如果复杂的查询,还是要查询从库。
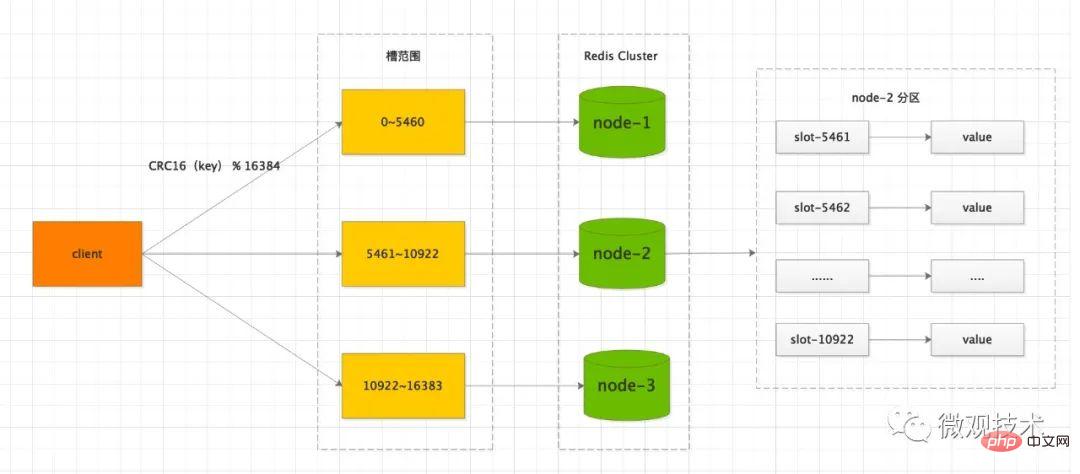
参考 Redis Cluster 模式, 集群网络拓扑通常是 3主 3从,主节点既负责写,也负责读。
通过水平分片,支持数据的横向扩展。由于每个节点都是独立的服务器,可以提高整体集群的吞吐量。
转换到数据库方面
常见的解决方式,是分库分表,每次读写都是操作主库的一个分表,从库只用来做数据备份。当主库发生故障时,主从切换,保证集群的高可用性。
推荐学习:mysql视频教程
以上がMySQL のマスター/スレーブ遅延と読み取り/書き込み分離に対する解決策の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



