この記事では、mysql に関する関連知識を提供します。主に、インデックスとは何か、インデックスの基礎となる実装など、高度な mysql の章のいくつかの問題を紹介します。一緒にそれについて話しましょう。見てください、それが皆さんのお役に立てば幸いです。

推奨学習: mysql ビデオ チュートリアル
MySQL は、よく知られているようでなじみのない用語ですが、できるだけ早く私たちが Javaweb を学習していたとき、MySQL データベースを使用していました。その段階では、MySQL はデータを保存するのにちょうど良いものであるように思えました。保存するときはデータをすべて詰め込み、クエリを実行するときはテーブル全体を盲目的にクエリします。 (少しの情報なしで)最適化)。
私たちは常に自分自身と他人を欺き、他の側面を通じて最適化できると考えています。MySQL Advanced に直面することに消極的で、代わりに、より高度だと思われるものを学びます。 「高度な」こと、MySQL のプレッシャーを共有するために Redis を学ぶ、MyCat とその他のミドルウェアを学ぶ、マスター/スレーブ レプリケーション 、読み取り/書き込み分離 、サブデータベースを実装するおよびサブテーブルなど。 (メロのことを言っているのです、そうです)
面接の準備をしていたとき、面接の質問で MySQL についてすべてを知っているわけではないことがわかりました~
私が学んだ最先端のミドルウェアについては、ほとんどGet!に依頼しました。 !使い方しか分からない 履歴書を書くときに、xxx ミドルウェアについて「理解している」と弱くしか書けません...
もちろん、MySQL Advanced Chapter を学ぶことはできません。インタビューのためですが、実際のプロジェクトではこの部分の最適化が非常に重要です。サーバーダウンを経験した後は、黙って行うしかありません...
今から始めましょう、上陸するにはまだ遅すぎます現時点では ! ! !ゴールド 3 とシルバー 4 を利用して、MySQL 上級章の知識ポイントを補足し、次の側面から MySQL 上級章の旅を開始することをお勧めします。
サイドバー ディレクトリから
役立つ部分を取得します。その中で、 絵文字表現プレフィックス
絵文字表現プレフィックス
が重要な部分です。役立つと思われる場合、エディターは引き続き表示します。この記事と MySQL コラムを改善してください。
インデックスの定義
MySQL のインデックスの公式定義は次のとおりです。 インデックス (インデックス) は、MySQL がデータを効率的に取得するのに役立つ (順序付けられた) データ構造です。インデックスは、クエリ効率を向上させるメカニズムとしてデータベース テーブルのフィールドに追加されます。データベース システムは、データに加えて、特定の検索アルゴリズムを満たすデータ構造も維持します。これらのデータ構造は、何らかの方法でデータを参照 (ポイント) するため、これらのデータ構造に高度な検索アルゴリズムを実装できます。このデータ構造は、索引。 。以下の図に示すように:
実際、簡単に言うと、インデックスはソートされたデータ構造です。
左側データ テーブルには合計 2 列と 7 つのレコードがあり、一番左はデータ レコードの物理アドレスです (論理的に隣接するレコードがディスク上で物理的に隣接しているとは限らないことに注意してください)。 Col2 の検索を高速化するために、右に示すようにバイナリ検索ツリーを維持できます。各ノードには、
インデックス キー値
と、対応するデータ レコードの物理アドレスへのポインタが含まれています。 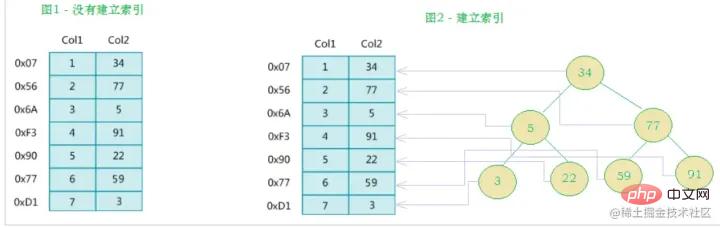 なので、二分検索を使用して、対応するデータをすばやく取得できます。
なので、二分検索を使用して、対応するデータをすばやく取得できます。
インデックスの利点検索
と
ソート
の速度を高速化し、データベースのIOコストとCPU消費量を削減します。
- 一意のインデックスを作成すると、データベース テーブル内のデータの各行の一意性が保証されます。 インデックスの欠点
- インデックスは実際には
テーブル
であり、主キーとインデックス フィールドを保存し、エンティティのレコードを指します。占有スペースが必要です。
クエリ効率は向上しますが、追加、削除、変更の場合、テーブルが変更されるたびにインデックスを更新する必要があります。新規: 当然、新しいノードを追加する必要があります。削除: インデックス ツリーでポイントされているレコードは失敗する可能性があります。これは、このインデックス ツリー内の多くのノードが無効な変更であることを意味します: インデックス ツリー内のノードの
をポイントする - には、必要な場合があります。
- に変更されますが、実際には、MySQL に保存するために バイナリ検索ツリー を使用しません。なぜですか?
二分探索ツリーでは、ここのノードは 1 つのデータのみを保存でき、ノードは MySQL のディスク ブロックに対応するため、毎回 1 つのディスク ブロックを読み取ることを知っておく必要があります。データは 1 つしか取得できず、効率が非常に悪いので、B-tree 構造を使用して格納することを考えます。
インデックス構造
インデックスは、サーバー層ではなく、MySQL のストレージ エンジン層に実装されます。したがって、各ストレージ エンジンのインデックスは必ずしも完全に同じであるとは限らず、すべてのエンジンがすべてのインデックス タイプをサポートしているわけではありません。
-
BTREE インデックス: 最も一般的なインデックス タイプで、ほとんどのインデックスが B ツリー インデックスをサポートします。
-
HASH Index: メモリ エンジンでのみサポートされており、使用シナリオは簡単です。
-
R ツリー インデックス (空間インデックス): 空間インデックスは、MyISAM エンジンの特別なインデックス タイプです。主に地理空間データ タイプに使用されます。通常はあまり使用されず、使用されません。特別にご紹介させていただきます。
-
フルテキスト (フルテキスト インデックス): フルテキスト インデックスは MyISAM の特別なインデックス タイプでもあり、主にフルテキスト インデックスに使用されます。InnoDB はフルテキスト インデックスの開始をサポートしています。 Mysql5.6バージョンから。
MyISAM、InnoDB、および Memory ストレージ エンジンはさまざまなインデックス タイプをサポートします
インデックス |
#INNODB エンジン
| #MYISAM エンジン
##メモリ エンジン |
##BTREE インデックス |
| サポート
|
サポート
| ## サポート |
#HASH インデックス
| サポートされていません
サポートされていません|
#サポートされている |
|
R ツリー インデックス
|
サポートされていません
|
サポートされている
|
サポートされていない |
| ##全文 | バージョン 5.6 以降はサポートされます
##サポートされます |
##サポートされません |
通常、インデックスと呼ばれるものは、特に指定がない限り、B ツリー (多方向検索ツリー、必ずしもバイナリではない) 構造で編成されたインデックスを指します。このうち、クラスター化インデックス、複合インデックス、プレフィックス インデックス、およびユニーク インデックスはすべてデフォルトで B ツリー インデックスを使用し、総称してインデックスと呼ばれます。
BTREE
マルチパスバランス検索ツリー、m 次 (m フォーク) BTREE は次の条件を満たします。
- 各ノードには最大 m 個の子があります。子の数: ceil(m/2) ~ m キーワードの数: ceil(m/2)-1 ~ m-1
ceil は切り上げを意味し、ceil(2.3)= 3
キーワード case を挿入

#m 次 B ツリーのプロパティを破壊しないことを保証します原因3 次の場合、ノードは最大 2 つまでなので、最初は 26 と 30 が一緒で、その後 85 が分割され始めます。30 が中央の上の位置になり、26 が残り、85 が次の位置に移動します。右側の 、つまり:
中央の上部の位置 、その後、左側は古いノードに留まり、右側は新しいノード
画像に 70 を挿入すると、たまたま 70 が真ん中の位置にあり、その後 62 が維持され、85 が新しいノードに分割されます。上昇したら、再度分割する必要があります。
上方向に分割し続けるだけで同じです。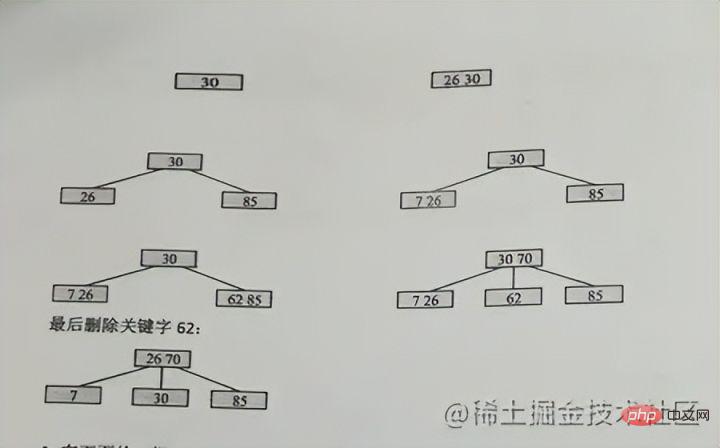
比較優位性二分探索ツリーと比較して、高さ/深さが低く、自然なクエリ効率が高くなります。
B TREE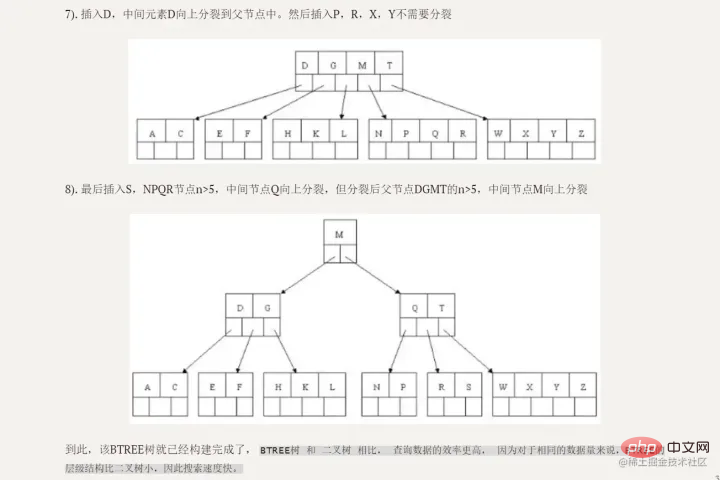
B ツリーには、内部ノード (インデックス ノード とも呼ばれます) と リーフ ノード という 2 種類のノードがあります。内部ノードは非リーフ ノードであり、内部ノードにはデータは格納されずインデックスのみが格納され、データはリーフ ノードに格納されます。
内部ノードのキーは、- 小さいものから大きいものまでの順序で配置されています内部ノードのキーの場合、左側のツリーのすべてのキーはそれより小さく、右側のツリーのキーはすべてそれよりも小さくなりますサブツリー キーはすべてそれ以上です。リーフ ノード内のレコードもキー サイズに従って配置されます。 各リーフノードには隣接するリーフノードへのポインタが格納されており、リーフノード自体はキーワードのサイズに応じて小さいから大きい順に接続されています。
- 親ノードは、right 子の最初の要素のインデックス を格納します。
- 利点の比較
B Tree のクエリ効率は より安定しています。 B ツリーのリーフ ノードのみがキー情報を保存するため、キーをクエリするにはルートからリーフに移動する必要があるため、より安定しています。 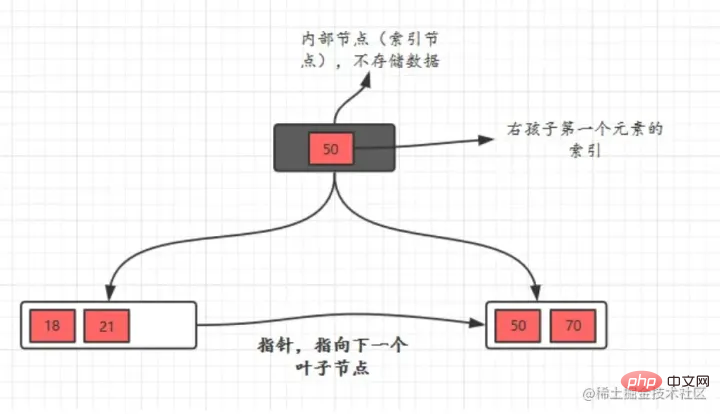 リーフ ノードをトラバースするだけで、ツリー全体をトラバースできます。 リーフ ノードをトラバースするだけで、ツリー全体をトラバースできます。
MySQL の B ツリー
- MySql インデックス データ構造は、従来の B ツリーを最適化します。元の B ツリーに基づいて、隣接するリーフ ノードを指す リンク リスト ポインタ (全体の構造は二重リンク リストに似ています) が形成され、シーケンシャル ポインタを備えた B ツリーが形成され、改善されます。インターバルアクセスのパフォーマンス。
- 注意深い生徒なら、この図と二分探索ツリー図の最大の違いは何であるかがわかるでしょうか?
二分探索ツリーから B ツリー への移行では、1 つのノードに複数のデータを保存できるという大きな変更があります。これは、1 つのディスク ブロックに複数のデータを保存できるのと同等です。データにアクセスできるため、IO 時間が大幅に短縮されます。 !
B MySQL のツリー インデックス構造図:
インデックスの原理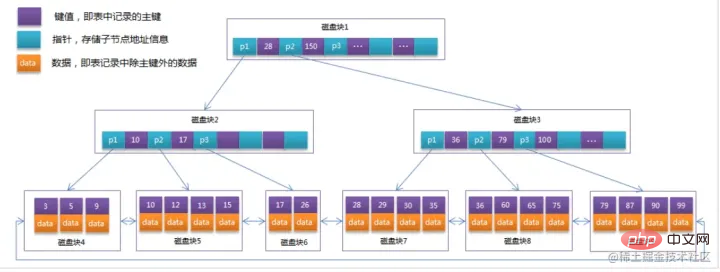 BTreeインデックス: BTreeインデックス:
初期化の概要
水色のものはディスクブロックと呼ばれ、各ディスクブロックに何個のディスクブロックが含まれているかがわかります。項目 (濃い青で表示) とポインター (黄色で表示) 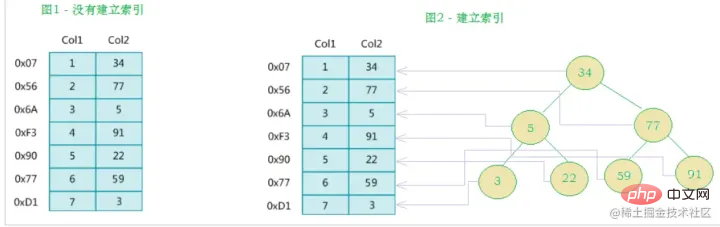 たとえば、ディスク ブロック 1 には、ポインター P1、P2、および P3 を含むデータ項目 17 と 35 が含まれています。 たとえば、ディスク ブロック 1 には、ポインター P1、P2、および P3 を含むデータ項目 17 と 35 が含まれています。 P1 は、17 未満のディスク ブロックを表します。 、P2 は 17 ~ 35 のディスク ブロックを表し、P3 は 35 より大きいディスク ブロックを表します。
-
実際のデータはリーフ ノードに存在しますつまり、3、5、9、10、13、15、28、29、36、60、75、79、90、99 。 `
- 非リーフ ノードには実際のデータは格納されません。17 や 35 などの検索方向をガイドする データ項目 だけが実際にはデータ テーブルに存在しません。 `
検索プロセス
データ項目 29 を検索する場合、最初にディスク ブロック 1 がディスクからメモリにロードされ、この時点で IO が発生します。 。メモリ内で二分探索を使用して、29 が 17 ~ 35 の間にあることを確認し、ディスク ブロック 1 の P2 ポインタをロックします。メモリ時間は (ディスクの IO と比較して) 非常に短いため、無視できます。ディスクを使用します。ディスク ブロック 1 からディスク ブロック 3 の P2 ポインタのアドレスがディスクからメモリにロードされます。2 番目の IO が発生します。29 は 26 と 30 の間にあります。ディスク ブロック 3 の P2 ポインタはロックされています。ディスク ブロック 8 がロードされます。ポインタを介してメモリにアクセス 3 回目の IO が発生 同時にメモリが通過 二分検索が 29 に達してクエリが終了し、合計 3 回の IO が発生します。
実際の状況では、3 層の B ツリーは数百万のデータを表すことができます。数百万のデータ検索に 3 回の IO だけが必要な場合、パフォーマンスは大幅に向上します。インデックスがない場合、各データは項目ごとに IO が発生すると、合計で数百万回の IO が必要となり、明らかにコストが非常に高くなります。
インデックスの分類
InnoDB では、主キーの順序に従ってテーブルをインデックス形式で格納しており、このように格納されたテーブルをインデックス構成テーブルと呼びます。前述したように、InnoDB は B ツリー インデックス モデルを使用するため、データは B ツリーに保存されます。
各インデックスは InnoDB の B ツリーに対応します。
主キー列を ID とするテーブルがあり、テーブル内にフィールド k があり、k にインデックスがあるとします。
このテーブルのテーブル作成文は次のとおりです:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
复制代码 ログイン後にコピー テーブル内のR1~R5の(ID,k)値は(100,1)、(200,2)、 (300,3)、(500,5)、および (600,6)、2 つのツリーの図の例は次のとおりです。図からはわかりにくいですが、リーフ ノードの内容に応じて、インデックス タイプが主キー インデックスと非主キー インデックスに分けられます。
主キー インデックス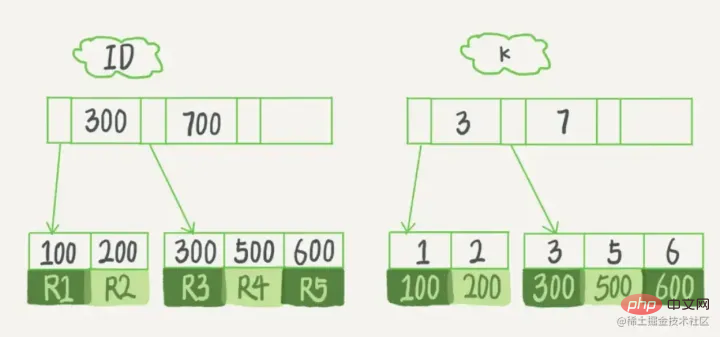 データ テーブルの主キー列は主キー インデックスを使用し、デフォルトで作成されます。これが、インデックス付けを学ぶ前に、先生がよく私たちにこう言ったのです。主キーに基づいたクエリです。高速になります。主キー自体にインデックスが付けられていることがわかります。
主キー インデックス
のリーフ ノードには、データ行全体が格納されます。 InnoDB では、主キー インデックスは クラスター化インデックス
(クラスター化インデックス) とも呼ばれます。 補助インデックス補助インデックス のリーフ ノードの内容は、 主キー の値です。 InnoDB では、補助インデックスは Secondary Index (セカンダリ インデックス) とも呼ばれます。 以下に示すように: 主キー インデックスは
データ行全体を格納します
補助インデックスはそれ自体のみを格納しますと ID 主キーはテーブル クエリに使用されます。
- 上記のインデックス構造に従って、質問について説明します。
クエリの違いは何ですか?主キーインデックスと補助インデックスに基づいていますか?
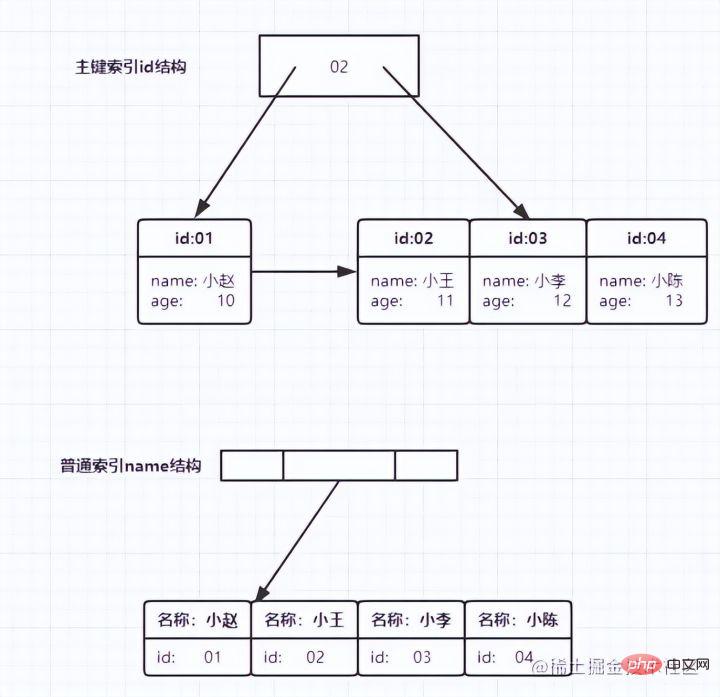
ステートメントが主キーのクエリ方法である select * from T where ID=500 の場合、ID の B ツリーを検索するだけで済みます。 ステートメントが select * from T where k=5 の場合、これは通常のインデックス クエリ方法ですが、最初に k インデックス ツリー
を検索し、ID 値 500 を取得する必要があります。 ## 次に、ID インデックス ツリー を 1 回検索します。このプロセスは テーブルに戻る- と呼ばれます。
-
言い換えると、補助インデックスに基づくクエリは、もう 1 つのインデックス ツリーをスキャンする必要があります。したがって、アプリケーションでは主キー クエリを使用するようにしてください。 クエリしたいデータがたまたまインデックス ツリーに存在しない限り、現時点ではそれを カバー インデックスと呼びます。つまり、インデックス列には、クエリするすべてのデータが含まれています。問われる。
同時に、セカンダリ インデックスは次のタイプに分類されます (簡単に読み飛ばしてください。詳細については後ほど説明します):
-
一意のキー (一意のキー): 一意のインデックスも制約です。 一意のインデックスの属性列には重複データを含めることはできませんが、データは NULL にすることができます。テーブルでは複数の一意のインデックスを作成できます。 ほとんどの場合、一意のインデックスを確立する目的は、クエリの効率性ではなく、属性列内のデータの一意性のためです。
-
通常のインデックス (インデックス): 通常のインデックスの唯一の機能は、データを迅速にクエリすることです。テーブルでは複数の通常のインデックスを作成でき、データの重複と NULL が許可されます。 。
-
プレフィックス インデックス (Prefix): プレフィックス インデックスは文字列型データにのみ適用されます。プレフィックスインデックスはテキストの最初の数文字にインデックスを作成し、最初の数文字だけを取得するため、通常のインデックスに比べて作成されるデータが小さくなります。
-
フル テキスト インデックス (フル テキスト): フル テキスト インデックスは、主に大規模なテキスト データ内のキーワード情報を取得するために使用され、現在検索エンジンのデータベースで使用されている技術です。 Mysql5.6 より前は、MYISAM エンジンのみがフルテキスト インデックスをサポートしていましたが、5.6 以降は、InnoDB もフルテキスト インデックスをサポートしました
拡張機能--インデックス プッシュダウン
いわゆるプッシュダウン名前が示すように、実際には テーブルを返す操作を延期します。非常に無駄が多いため、MySQL ではテーブルを簡単に返すことはできません。それはどういう意味ですか?次の例を考えてみましょう。
複合インデックス (名前、ステータス、アドレス) を確立しました。これも、次の図のように、このフィールドに従って保存されます。
複合インデックス ツリー (インデックス列とアドレスのみを保存します)主キーはテーブルを返すために使用されます)
name |
##status
| アドレス
|
id(主キー)
|
| Xiaomi 1
| 0
|
1
|
1
|
#Xiaomi 2 | 1 | 1 | 2 |
我们执行这样一条语句:
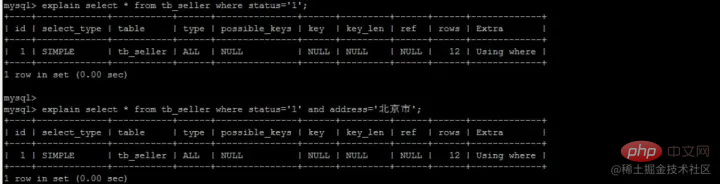
SELECT name FROM tb_seller WHERE name like '小米%' and status ='1' ;
复制代码 ログイン後にコピー
- 首先我们在复合索引树上,找到了第一个以小米开头的name -- 小米1
- 此时我们不着急回表(回到主键索引树搜索的过程,我们称为回表),而是先在复合索引树判断status是否=1,此时status=0,我们直接就不回表了,直接继续找下一个以小米开头的name
- 找到第二个-- 小米2,判断status=1,则根据id=2去主键索引树上找,得到所有的数据
这种先在自身索引树上判断是否满足其他的where条件,不满足则直接pass掉,不进行回表的操作,就叫做索引下推。
最左前缀原则
所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个复合索引:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效:
- 按楼梯从低到高,无出现跳跃的情况--此时符合最左前缀原则,索引不会失效

- 出现跳跃的情况
- 直接第一层name都不走,当然都失效
- 走了第一层,但是后续直接第三层,只有出现跳跃情况前的不会失效(此处就只有name成功)

- 同时,这个顺序并不是由我们where中的排列顺序决定,比如: where name='小米科技' and status='1' and address='北京市' where status='1' and name='小米科技' and address='北京市'
这两个尽管where中字段的顺序不一样,第二个看起来越级了,但实际上效果是一样的
其实是因为我们MySQL有一个Optimizer(查询优化器),查询优化器会将SQL进行优化,选择最优的查询计划来执行。
- 关于这个查询优化器,后续文章我们也会谈谈MySQL的逻辑架构与存储引擎
索引设计原则
针对表
- 查询频次高,且数据量多的表
针对字段
- 最好从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
其他原则
- 最好用唯一索引,区分度越高,使用索引的效率越高
- 不是越多越好,维护也需要时间和空间代价,建议单张表索引不超过 5 个
因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
比如:
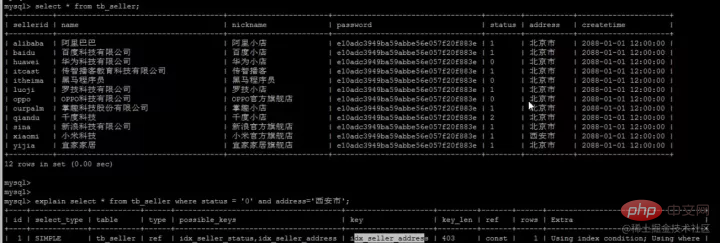
我们创建了三个单列索引,name,status,address
当我们where中根据status和address两个字段来查询时,数据库只会选择最优的一个索引,不会所有单列索引都使用。
最优的索引:具体是指所查询表中,辨识度最高(所占比例最少)的索引列,比如此处address中有一个辨识度很高的 '西安市'数据;
- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
- 利用最左前缀,比如有N个字段,我们不一定需要创建N个索引,可以用复合索引
也就是说,我们尽量创建复合索引,而不是单列索引
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(name,email,status);
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;
复制代码 ログイン後にコピー 举个栗子
假设我们有这么一个表,id为主键,没有创建索引:
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB
复制代码 ログイン後にコピー 如果要在此处建立复合索引,我们要遵循什么原则呢?
通过调整顺序,可以少维护一个索引
- 比如我们的业务需求里边,有如下两种查询方式: 根据name查询 根据name和age查询
如果我们建立索引(age,name),由于最左前缀原则,我们这个索引能实现的是根据age,根据age和name查询,并不能单纯根据name查询(因为跳跃了),为了实现我们的需求,我们还得再建立一个name索引;
而如果我们通过调整顺序,改成(name,age),就能实现我们的需求了,无需再维护一个name索引,这就是通过调整顺序,可以少维护一个索引。
考虑空间->短索引
- 比如我们的业务需求里边,有以下两种查询方式: 根据name查询 根据age查询 根据name和age查询
我们有两种方案:
- 建立联合索引(name,age),建立单列索引:age索引。
- 建立联合索引(age,name),建立单列索引:name索引。
这两种方案都能实现我们的需求,这个时候我们就要考虑空间了,name字段是比age字段大的,显然方案1所耗费的空间是更小的,所以我们更倾向于方案1。
何时建立索引
- where中的查询字段
- 查询中与其他表关联的字段,比如外键
- 排序的字段
- 统计或分组的字段
何时达咩索引
- 表中数据量很少
- 经常改动的表
- 频繁更新的字段
-
数据重复且分布均匀的表字段(比如包含了很多重复数据,那此时多叉树的二分查找,其实用处不大,可以理解为O(logn)退化了)
索引相关语法
创建索引
默认会为主键创建索引--primary
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
复制代码 ログイン後にコピー 查找索引
结尾加上\G,可以变成竖屏显示
select index from tbl_name\G;
复制代码 ログイン後にコピー 删除索引
drop INDEX index_name on tbl_name ;
复制代码 ログイン後にコピー 变更索引
1). alter table tb_name add primary key(column_list);
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
2). alter table tb_name add unique index_name(column_list);
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
3). alter table tb_name add index index_name(column_list);
添加普通索引, 索引值可以出现多次。
4). alter table tb_name add fulltext index_name(column_list);
该语句指定了索引为FULLTEXT, 用于全文索引
复制代码 ログイン後にコピー 查看索引使用情况
show status like 'Handler_read%'; -- 查看当前会话索引使用情况
show global status like 'Handler_read%'; -- 查看全局索引使用情况
复制代码 ログイン後にコピー Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低越好)。
Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(这个值越高越好)。
Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。
Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。
Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
总结
- 索引简单来说就是一个排好序的数据结构,可以方便我们检索数据,而不需要盲目的进行全表扫描。
- 索引底层有很多种实现结构,这篇主要只是讲解了BTREE索引,如果对树这一数据结构还不太熟悉的小伙伴,可以关注我后续数据结构专栏,会整理关于普通树,二叉树,二叉排序树的文章。
- 索引分类:
- 主键索引
- 辅助索引
这里我们还扩展了索引下推,是一个十分重要的知识点,需要仔细回味。
- 索引的相关设计原则,索引虽好,但也不可贪杯,不能为了用索引而建索引。
- 索引的相关语法,很容易上手的。
- 查看索引的使用情况。
推荐学习:mysql视频教程
|
以上がMySQL インデックスについて説明しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



