


この記事は、python に関する関連知識を提供します。主に、数値、文字列、リスト、タプル、辞書などを含むデータ構造に関連する問題を紹介します。内容は、皆様のお役に立てれば幸いです。 。

推奨学習: Python ビデオ チュートリアル
整数型 ( int ) - 多くの場合、整数または整数、つまり小数点のない正または負の整数と呼ばれます。 Python3 の整数にはサイズ制限がなく、Long 型として使用できます。ブール値は整数のサブタイプです。
浮動小数点型 (float) - 浮動小数点型は整数部と小数部で構成され、科学表記法 (2.5e2 = 2.5 x ) を使用して表現することもできます。 102 = 250)
複素数 ((complex)) - 複素数は実数部と虚数部で構成され、bj または complex(a, b). 複素数 b の実部 a と虚数部はすべて浮動小数点型です。
int(x) x を整数に変換します。
float(x) x を浮動小数点数に変換します。
complex(x) 実数部を x、虚数部を 0 として、x を複素数に変換します。
complex(x, y) 実数部を x、虚数部を y として、x と y を複素数に変換します。 x と y は数値式です。
# + - * / %(取余) **(幂运算) # 整数除法中,除法 / 总是返回一个浮点数, # 如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // print(8 / 5) # 1.6 print(8 // 5) # 1 # 注意:// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系 print(8 // 5.0) # 1.0 # 使用 ** 操作来进行幂运算 print(5 ** 2) # 5的平方 25
index():部分文字列 substr が初めて出現する位置。検索対象の部分文字列が存在しない場合、ValueErrorrindex() 例外がスローされます。
rindex(): 最後の出現箇所を検索します。部分文字列 substr.position、検索された部分文字列が存在しない場合、ValueError() 例外がスローされます
find(): 部分文字列 substr が最初に出現する位置を検索します。検索された部分文字列 文字列が存在しない場合、-1
rfind(): 部分文字列 substr の最後の出現を検索します。検索された部分文字列が存在しない場合、-1 を返します。
s = 'hello, hello'
print(s.index('lo')) # 3
print(s.find('lo')) # 3
print(s.find('k')) # -1
print(s.rindex('lo')) # 10
print(s.rfind('lo')) # 10upper(): 文字列内のすべての文字を大文字に変換します
#
s = 'hello, Python' print(s.upper()) # HELLO, PYTHON print(s.lower()) # hello, python print(s.swapcase()) # HELLO, pYTHON print(s.capitalize()) # Hello, python print(s.title()) # Hello, Python
#ljust(): 左揃え、最初のパラメータは幅を指定し、2 番目のパラメータはフィラーを指定します。デフォルトはスペースです。設定された幅が実際の幅より小さい場合は、元の文字列が返されます
rjust(): 右揃え、最初のパラメータは幅を指定し、2 番目のパラメータはフィラーを指定します。デフォルトはスペースです。設定された幅が実際の幅より小さい場合は、元の文字列が返されます
zfill(): 右揃え、左側は 0 で埋められます。このメソッドは、文字列の幅を指定するために使用されるパラメータを 1 つだけ受け取ります。指定された幅が文字列の長さ以下である場合、文字列自体が返されます
s = 'hello,Python'
'''居中对齐'''
print(s.center(20, '*')) # ****hello,Python****
'''左对齐 '''
print(s.ljust(20, '*')) # hello,Python********
print(s.ljust(5, '*')) # hello,Python
'''右对齐'''
print(s.rjust(20, '*')) # ********hello,Python
'''右对齐,使用0进行填充'''
print(s.zfill(20)) # 00000000hello,Python
print('-1005'.zfill(8)) # -0001005文字列の分割、スライス
split(): 文字列の左側から分割します
rsplit(): 文字列の右側から分割しますs = 'hello word Python'
print(s.split()) # ['hello', 'word', 'Python']
s1 = 'hello|word|Python'
print(s1.split(sep='|')) # ['hello', 'word', 'Python']
print(s1.split('|', 1)) # ['hello', 'word|Python'] # 左侧开始
print(s1.rsplit('|', 1)) # ['hello|word', 'Python'] # 右侧开始s = 'hello,world' print(s[:5]) # hello 从索引0开始,到4结束 print(s[6:]) # world 从索引6开始,到最后一个元素 print(s[1:5:1]) # ello 从索引1开始,到4结束,步长为1 print(s[::2]) # hlowrd 从开始到结束,步长为2 print(s[::-1]) # dlrow,olleh 步长为负数,从最后一个元素(索引-1)开始,到第一个元素结束 print(s[-6::1]) # ,world 从索引-6开始,到最后一个结束
#isidentifier(): 指定された文字列が正当な識別子であるかどうかを判断します。
isspace(): 指定された文字列全体が空白文字 (キャリッジ リターン、ライン フィード、水平タブ文字) で構成されているかどうかを判断します。 isalpha(): 指定された文字列が完全に文字構成で構成されているかどうかを判断します。s = 'hello,Python,Python,Python'
print(s.replace('Python', 'Java')) # 默认全部替换 hello,Java,Java,Java
print(s.replace('Python', 'Java', 2)) # 设置替换个数 hello,Java,Java,Pythonlst = ['hello', 'java', 'Python']
print(','.join(lst)) # hello,java,Python
print('|'.join(lst)) # hello|java|Pythonフォーマットされた文字列出力
% プレースホルダー: 出力の前に % を追加し、複数のパラメーターには括弧とカンマを使用しますname = '张三'
age = 20
print('我叫%s, 今年%d岁' % (name, age))
print('我叫{0}, 今年{1}岁,小名也叫{0}'.format(name, age))
print(f'我叫{name}, 今年{age}岁')
# 我叫张三, 今年20岁
# 我叫张三, 今年20岁,小名也叫张三
# 我叫张三, 今年20岁# 设置数字的宽度和精度
'''%占位'''
print('%10d' % 99) # 10表示宽度
print('%.3f' % 3.1415926) # .3f表示小数点后3位
print('%10.3f' % 3.1415926) # 同时设置宽度和精度
'''{}占位 需要使用:开始'''
print('{:.3}'.format(3.1415926)) # .3表示3位有效数字
print('{:.3f}'.format(3.1415926)) # .3f表示小数点后3位
print('{:10.3f}'.format(3.1415926)) # .3f表示小数点后3位
# 99
#3.142
# 3.142
#3.14
#3.142
# 3.142s = '但愿人长久' # 编码 将字符串转换成byte(二进制)数据 print(s.encode(encoding='gbk')) #gbk,中文占用2个字节 print(s.encode(encoding='utf-8')) #utf-8,中文占用3个字节 # 解码 将byte(二进制)转换成字符串数据 # 编码与解码中,encoding方式需要一致 byte = s.encode(encoding='gbk') print(byte.decode(encoding='gbk')) # b'\xb5\xab\xd4\xb8\xc8\xcb\xb3\xa4\xbe\xc3' # b'\xe4\xbd\x86\xe6\x84\xbf\xe4\xba\xba\xe9\x95\xbf\xe4\xb9\x85' # 但愿人长久
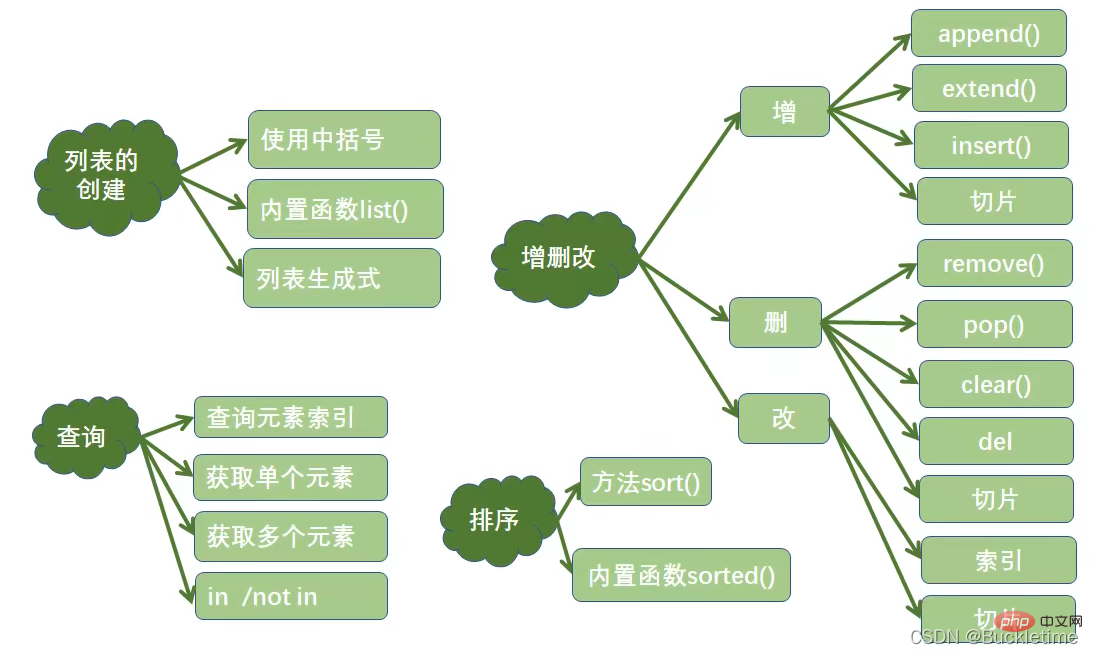
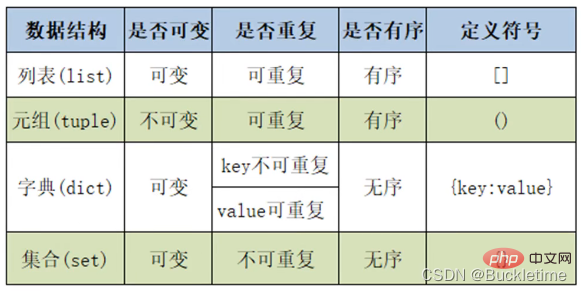
可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存
语法格式:[i*i for i in range(i, 10)]
解释:i表示自定义变量,i*i表示列表元素的表达式,range(i, 10)表示可迭代对象
print([i * i for i in range(1, 10)])# [1, 4, 9, 16, 25, 36, 49, 64, 81]
in / not in
for item in list: print(item)
list.index(item)
list = [1, 4, 9, 16, 25, 36, 49, 64, 81]print(list[3]) # 16print(list[3:6]) # [16, 25, 36]
append():在列表的末尾添加一个元素
extend():在列表的末尾至少添加一个元素
insert0:在列表的指定位置添加一个元素
切片:在列表的指定位置添加至少一个元素
rerove():一次删除一个元素,
重复元素只删除第一个,
元素不存在抛出ValceError异常
pop():删除一个指定索引位置上的元素,
指定索引不存在抛出IndexError异常,
不指定索引,删除列表中最后一个元素
切片:一次至少删除一个元素
clear0:清空列表
del:删除列表
list.sort()
sorted(list)
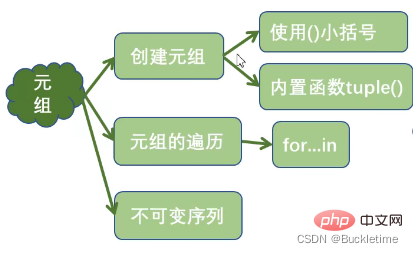
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号
t = ('Python', 'hello', 90)tuple(('Python', 'hello', 90))t = (10,)
items = ['fruits', 'Books', 'Others']
prices = [12, 36, 44]
d = {item.upper(): price for item, price in zip(items, prices)}
print(d) # {'FRUITS': 12, 'BOOKS': 36, 'OTHERS': 44}user = {"id": 1, "name": "zhangsan"}
user["age"] = 25
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 25}user = {"id": 1, "name": "zhangsan", "age": 25}
user["age"] = 18
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 18}user = {"id": 1, "name": "zhangsan"}del user["id"]print(user) # {'name': 'zhangsan'}del useruser = {"id": 1, "name": "zhangsan"}user.clear()print(user) # {}scores = {'张三': 100, '李四': 95, '王五': 88}for name in scores:
print(name, scores[name])scores = {'张三': 100, '李四': 95, '王五': 88}for name, score in scores.items():
print(name, score)
s = {'Python', 'hello', 90}print(set("Python"))print(set(range(1,6)))print(set([3, 4, 7]))print(set((3, 2, 0)))print(set({"a", "b", "c"}))# 定义空集合:set()print(set())print({i * i for i in range(1, 10)})# {64, 1, 4, 36, 9, 16, 49, 81, 25}两个集合是否相等:可以使用运算符 == 或 != 进行判断,只要元素相同就相等
一个集合是否是另一个集合的子集:issubset()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {10, 70}print(s2.issubset(s1))
# Trueprint(s3.issubset(s1)) # Falseprint(s1.issuperset(s2)) # Trueprint(s1.issuperset(s3)) # False
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {20, 70}print(s1.isdisjoint(s2))
# False 有交集print(s3.isdisjoint(s2)) # True 无交集s1 = {10, 20, 30, 40}s2 = {20, 30, 40, 50, 60}print(s1.intersection(s2)) # {40, 20, 30}print(s1 & s2) # {40, 20, 30}print(s1.union(s2)) # {40, 10, 50, 20, 60, 30}print(s1 | s2) # {40, 10, 50, 20, 60, 30}print(s2.difference(s1)) # {50, 60}print(s2 - s1) # {50, 60}print(s2.symmetric_difference(s1)) # {10, 50, 60}print(s2 ^ s1) # {10, 50, 60}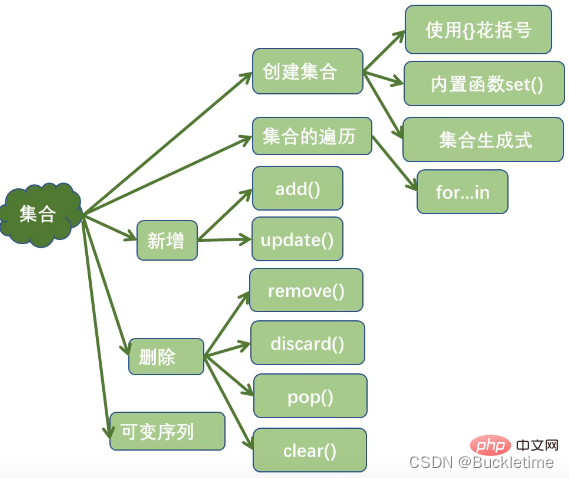
推荐学习:python教程
以上がPython3 データ構造の知識ポイントの詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



