

この記事では、Redis に関する関連知識を提供します。主に、文字列、リスト、ハッシュ、順序セットなどのデータ構造に関する関連問題を紹介します。内容は、皆様のお役に立てれば幸いです。

推奨学習: Redis 学習チュートリアル
Redis データ構造: String (文字列)、List (リスト)、ハッシュ (ハッシュ) )、セット (セット)、短縮セット (順序セット)
基礎となるデータ構造: 単純な動的文字列、二重リンク リスト、圧縮リスト、ハッシュ テーブル、スキップ リスト、整数配列
1. ハッシュ テーブル: ハッシュ テーブルは実際には配列であり、配列内の各要素はハッシュ バケットと呼ばれます。 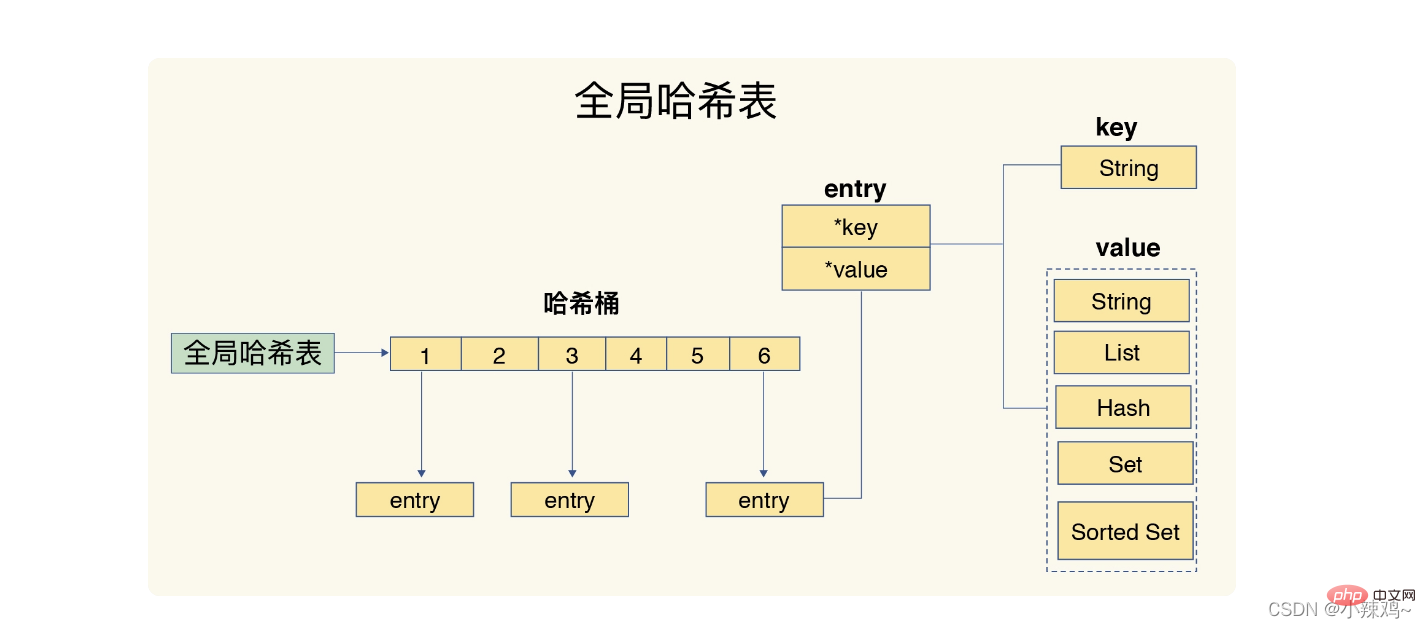
ハッシュの競合と再ハッシュにより、操作がブロックされる可能性があります。
redis がハッシュの競合を解決する方法はチェーン ハッシュですが、rehash は既存のハッシュ バケットの数を増やすことです。 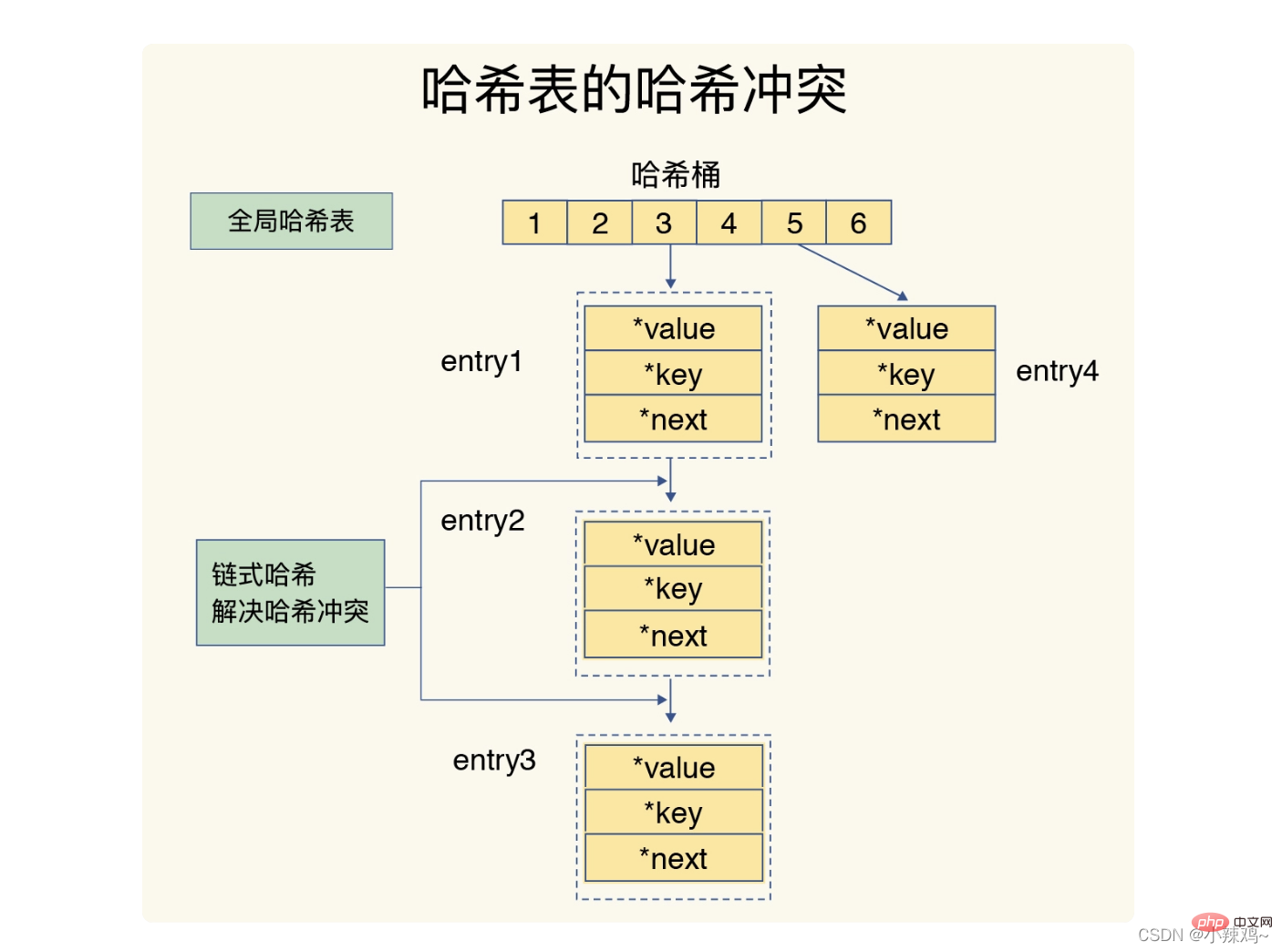
再ハッシュ操作の手順: 1. より大きな領域をハッシュ テーブルに割り当てます (たとえば、現在のハッシュ テーブルの 2 倍のサイズ)
2. ハッシュ テーブル 1 のデータを再マップし、それを次の場所にコピーします。ハッシュ テーブル 2
3. ハッシュ テーブル 1
の領域を解放します。 2 番目のステップでは、大量のデータ コピー操作が必要です。ハッシュ テーブル 1 のすべてのデータを一度に移行すると、スレッド ブロッキングが発生します。他のリクエストは処理できません。この問題を回避するために、redis はプログレッシブ リハッシュを使用します。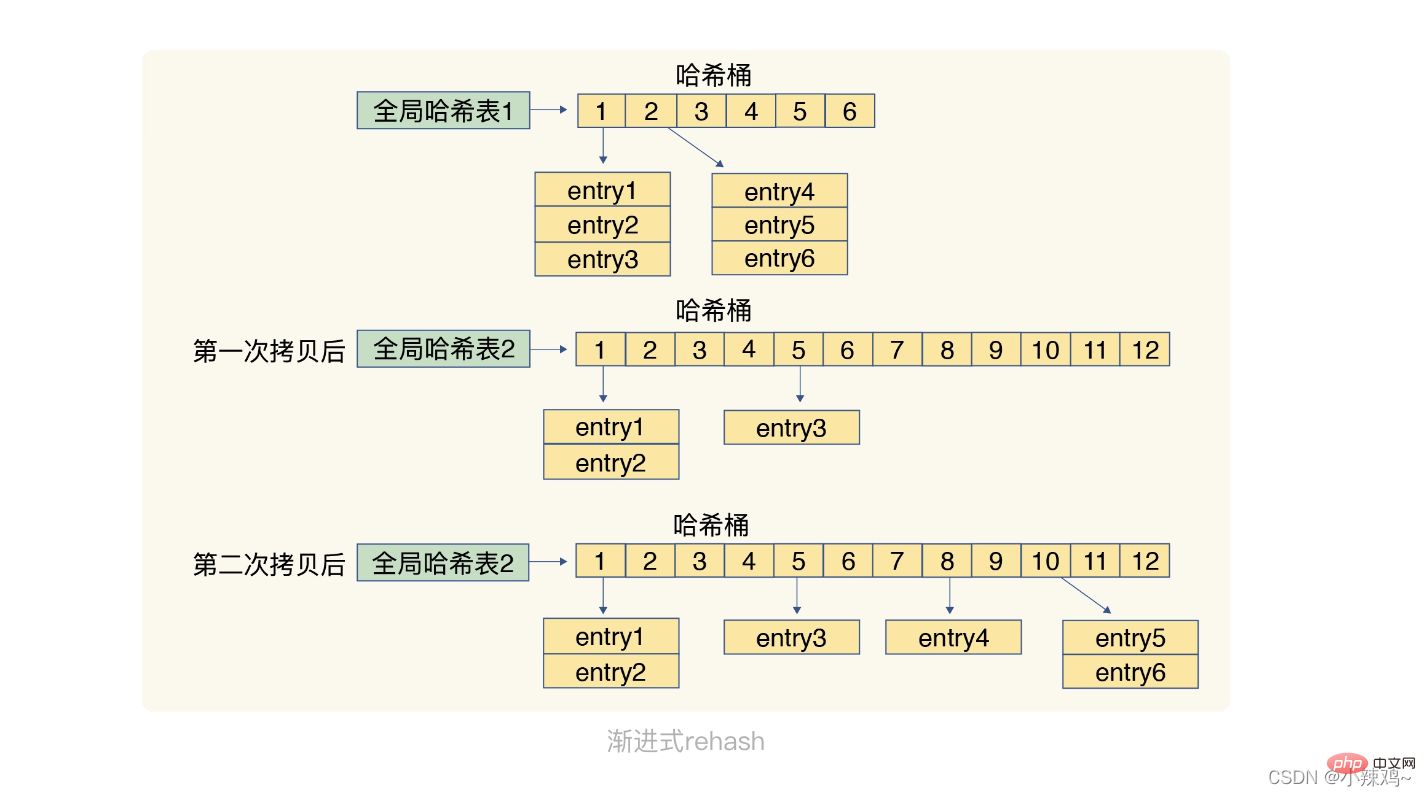
整数配列と二重リンク リストの複雑さは O(N)
です。圧縮されたリストのヘッダーには 3 つのデータが含まれます。 length、リストの末尾のオフセットとリスト内のエントリの数
圧縮リストの末尾には、リストの末尾を表す要素 zlend もあります。
リストをスキップします。順序付きリンク リストは要素を 1 つずつ検索することしかできませんが、ジャンプ リストはリンク リストに基づいてマルチレベルのインデックスが追加され、インデックス位置での複数のジャンプを通じてデータを迅速に配置できます。 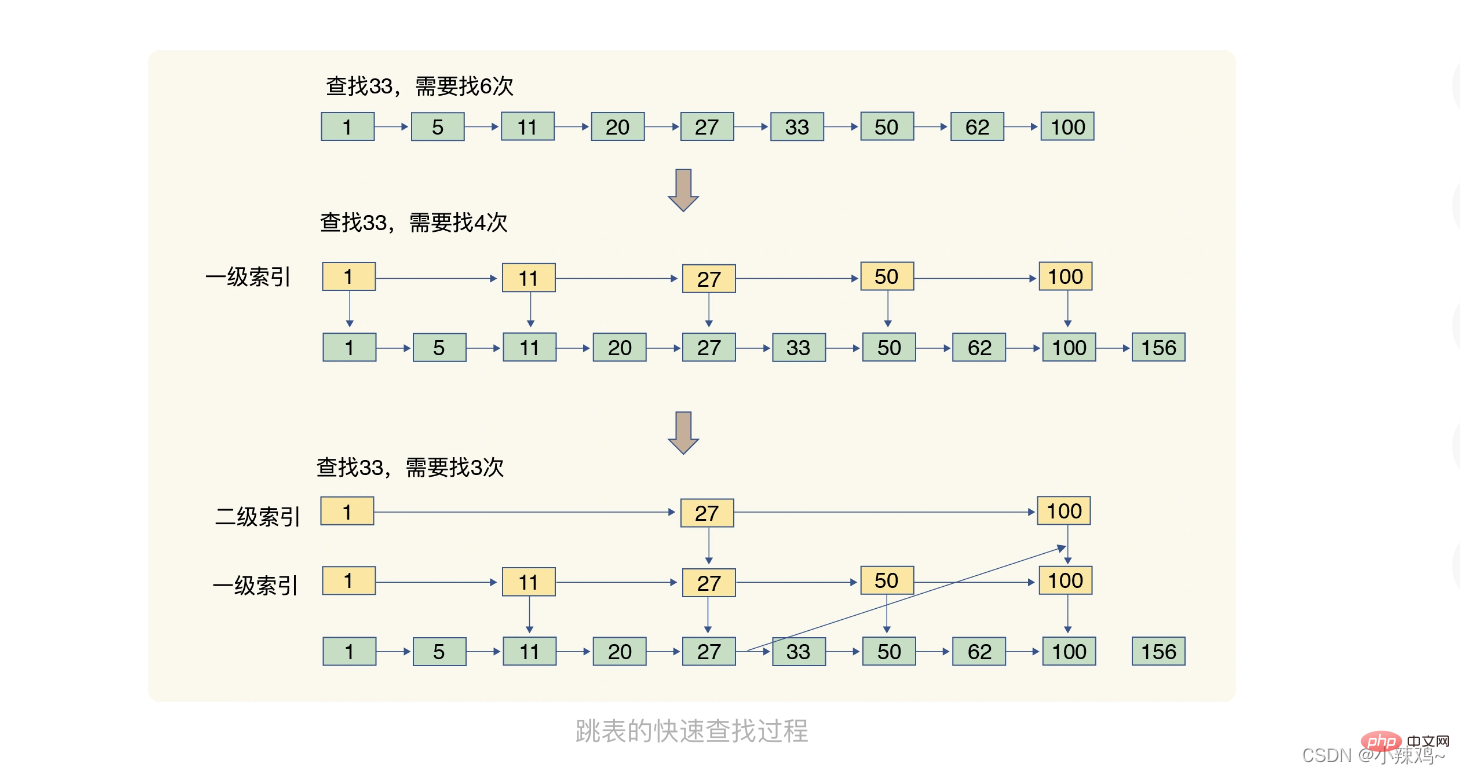 次の 5 つの構造の時間計算量
次の 5 つの構造の時間計算量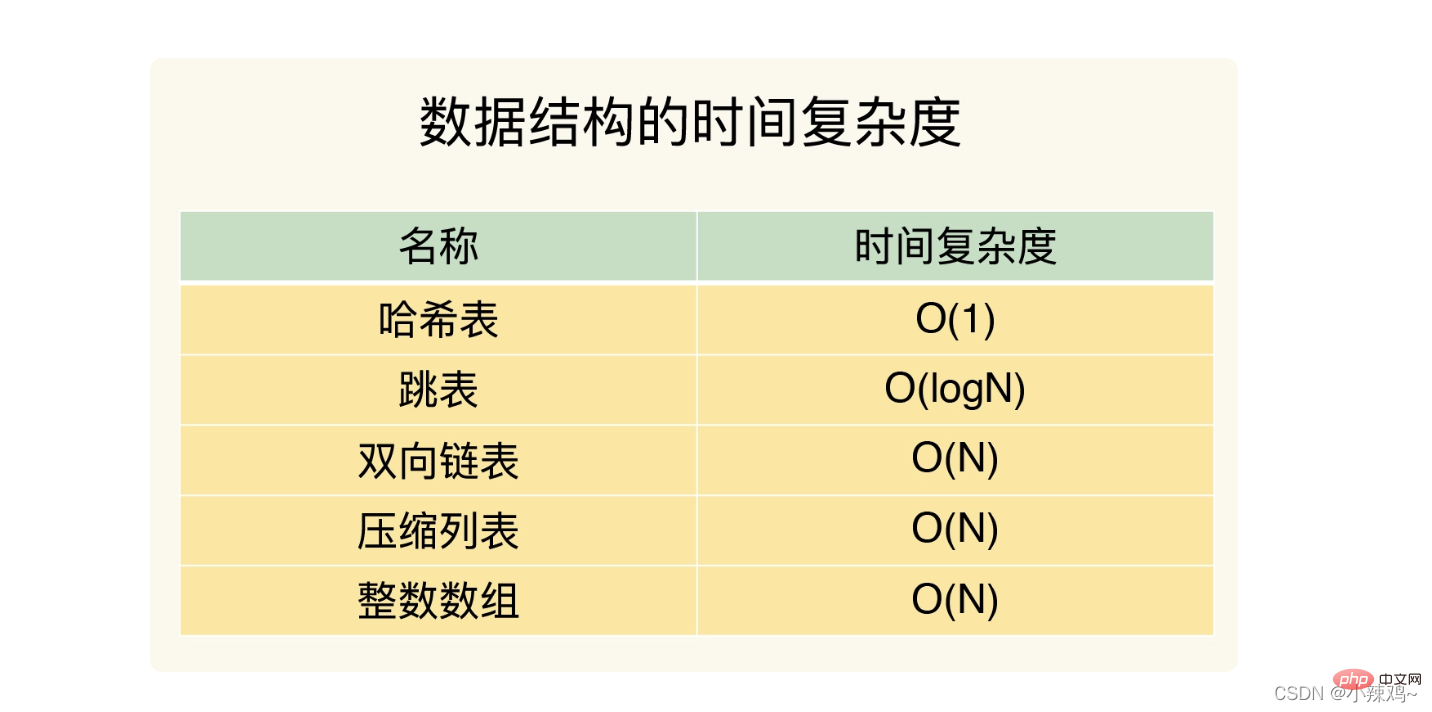
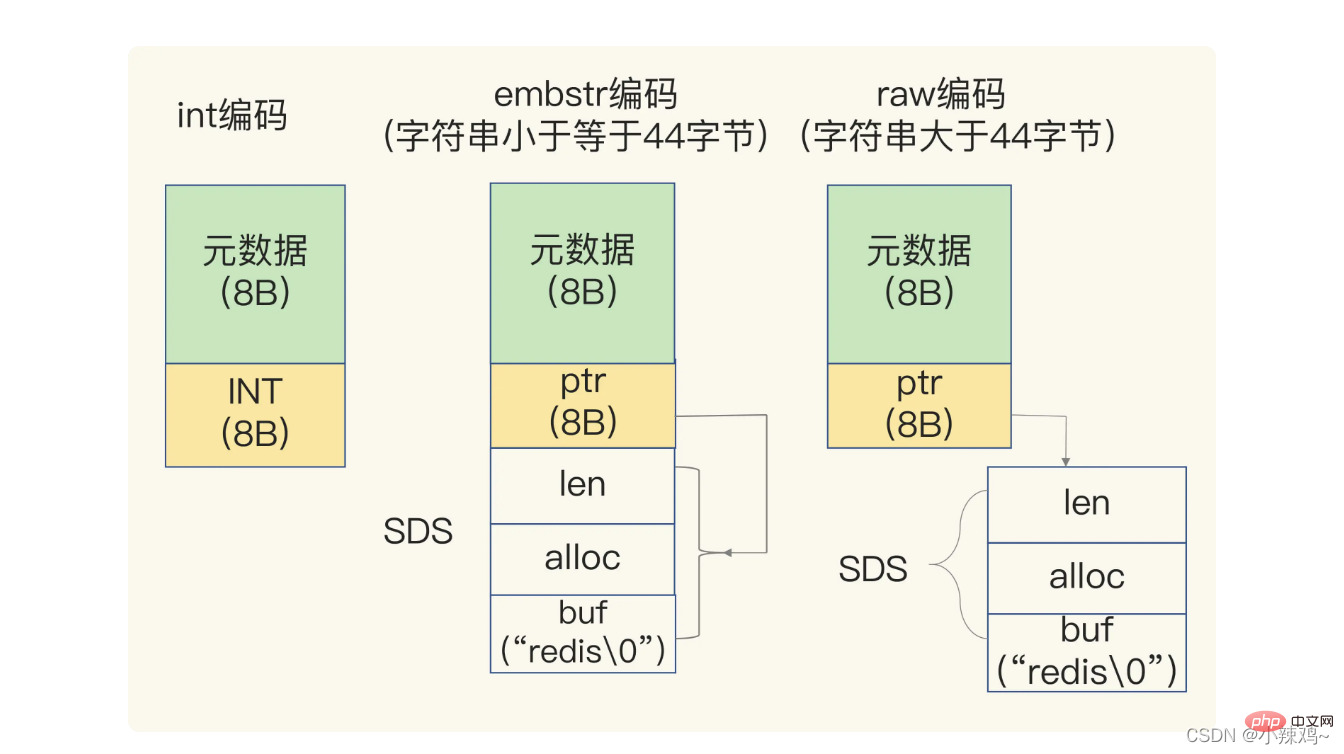
保存データに文字が含まれる場合、文字列は単純な動的文字列 SDS 構造を使用して保存されます 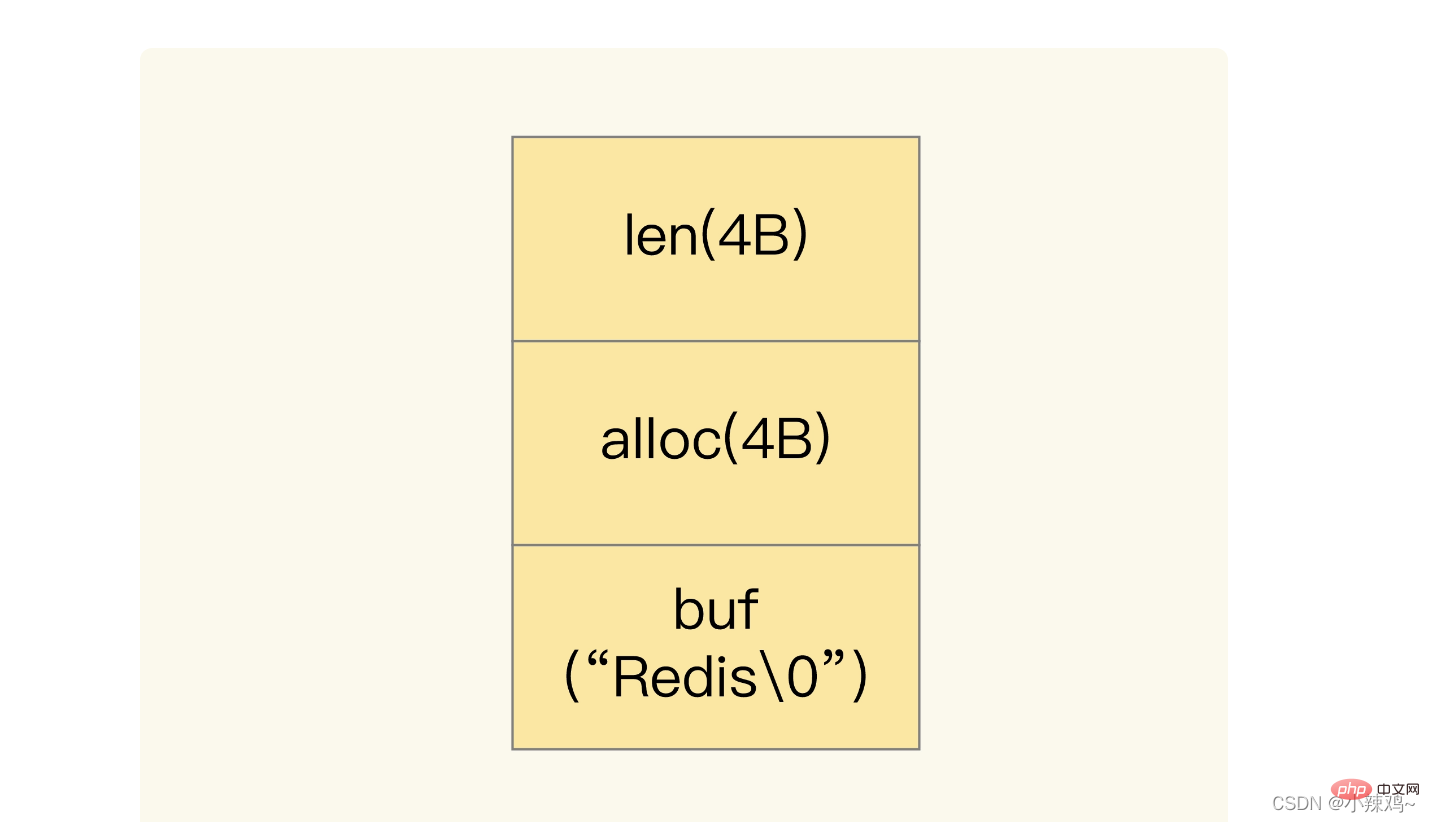 len は buf の使用長です alloc は実際に割り当てられた buf の長さです
len は buf の使用長です alloc は実際に割り当てられた buf の長さです
なぜなら、redis多くのデータ型があり、異なるデータ型には記録する同じメタデータがあるため、redis は RedisObject 構造を使用してこれらのメタデータを均一に記録します。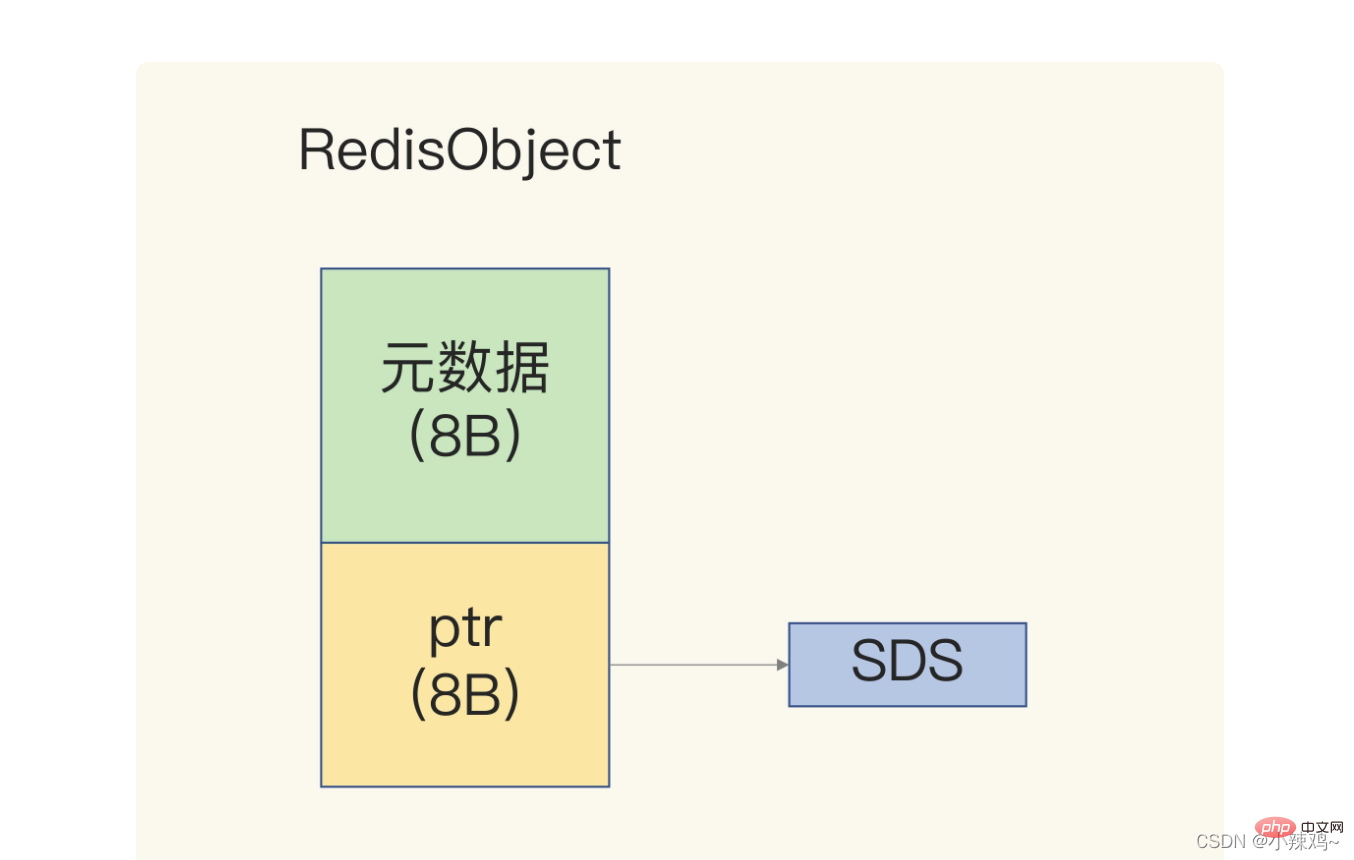 Long 型を保存する場合、RedisObject ポインターに値を直接整数データに設定できるため、整数を指すために追加のポインターが必要なくなり、ポインターのスペース オーバーヘッドが節約されます。
Long 型を保存する場合、RedisObject ポインターに値を直接整数データに設定できるため、整数を指すために追加のポインターが必要なくなり、ポインターのスペース オーバーヘッドが節約されます。
保存された文字列が 44 バイト未満の場合、sds とメタデータは embstr エンコーディングと呼ばれる連続メモリ領域に割り当てられます。
保存された文字列が 44 バイトより大きい場合、SDS とメタデータは embstr エンコーディングと呼ばれ、別々に保存されます。生のエンコーディング
さらに、redis はグローバル ハッシュ テーブルを使用してすべてのキーと値のペアを保存します。ハッシュ テーブル内の各項目は、キーと値のペアを指すために使用される dictEntry 構造です。キー値が表示されます。次は 24 バイトを使用しますが、実際には 32 バイトを占有します。これは、jemalloc がメモリを割り当てるときに、N より大きいが N に最も近い 2 のべき乗を、バイト数に応じて見つけるためです。スペースを申請することで、頻繁な割り当ての数を減らすことができます。 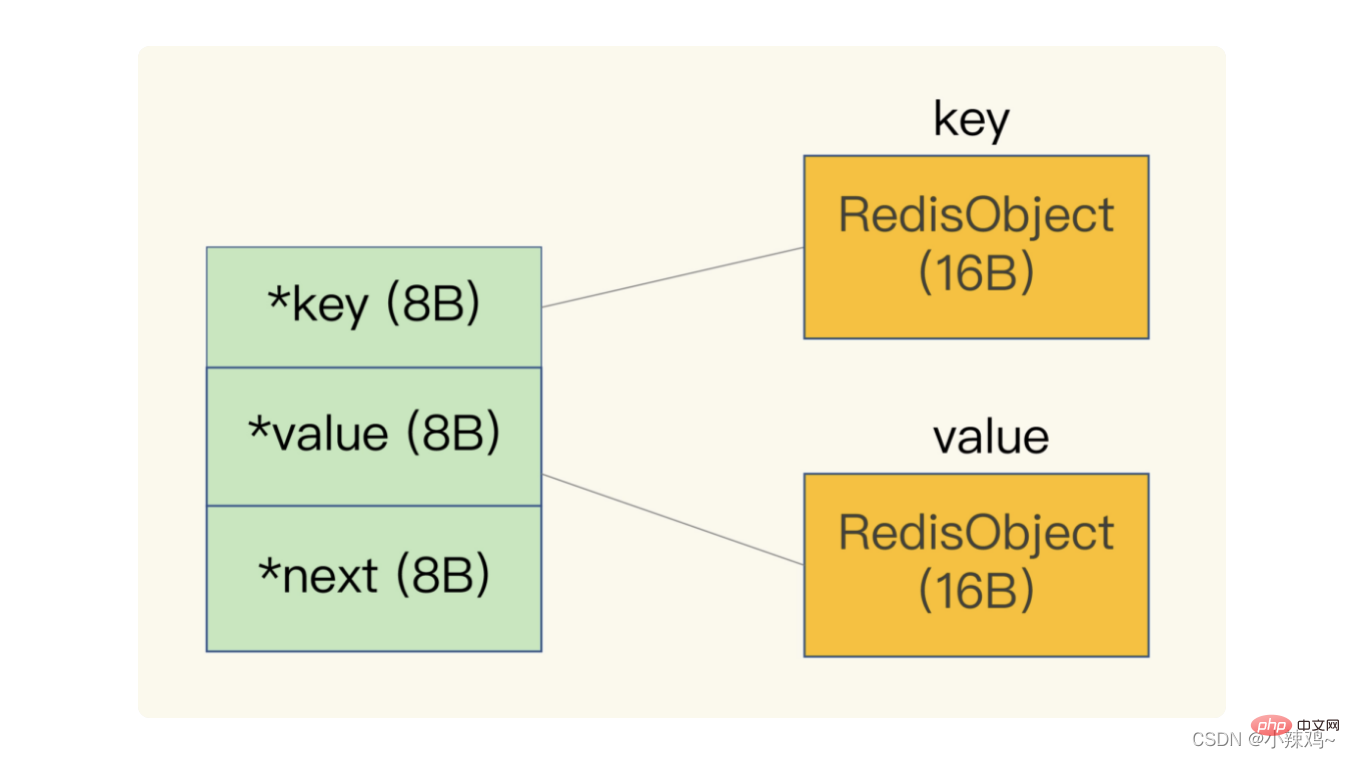
メモリを節約するにはどのようなデータ構造を使用できますか?
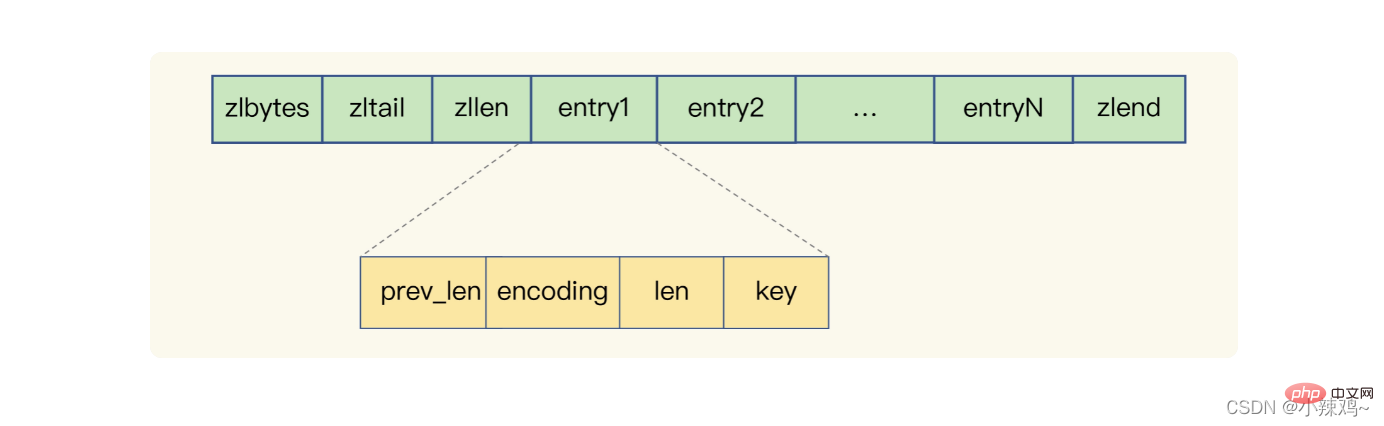
圧縮リスト: zlbytes はリストの長さを表し、zltail はリストの末尾オフセットを表し、zllen はリスト内のエントリの数を表し、zlend はリストの終わりを表し、perv_len はリストの長さを表します。前のエントリでは、encoding はエンコード方法を表し、len はそれ自体の長さを表し、キーは実際に格納されているデータです。 Redis は、圧縮リストに基づいてリスト、ハッシュ、ソート セットを実装します。
セット タイプを使用して単一値のキーと値のペアを保存するにはどうすればよいですか?
単一値のキーと値のペアを保存する場合、単一値の値を 2 つの部分に分割するハッシュの 2 番目のエンコーディングを使用できます。最初の部分はハッシュ キーとして使用され、後半の部分はハッシュ キーとして使用されます。
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。127.0.0.1:6379> info memory# Memoryused_memory:1039120127.0.0.1:6379> hset 1101000 060 3302000080(integer) 1127.0.0.1:6379> info memory# Memoryused_memory:1039136
ハッシュ タイプには 2 つの基本的な実装構造があります: 1. 圧縮リスト 2. ハッシュ テーブル
ハッシュ リストには 2 つのしきい値があります。これら 2 つのしきい値を超えると、圧縮リストからハッシュ テーブルに変換されます。
hash-max-ziplist-entries は、圧縮リストに保存するときに設定されたハッシュ リストの要素の最大数を示します。
hash-max-ziplist-value は、圧縮リストに保存する場合のハッシュ セットの 1 つの要素の最大長
統計モードの設定
1. 統計の集計
2. 統計の並べ替え
3.バイナリ状態統計
4. カーディナリティ統計
1.Bitmap:
2.HyperLogLog
3.GEO:
LBS アプリケーションの GEO データ型
GEO の基礎となる構造は、ソート セットに基づいて実装されます。ソート セットは、要素の重みに従ってソートでき、範囲クエリをサポートします。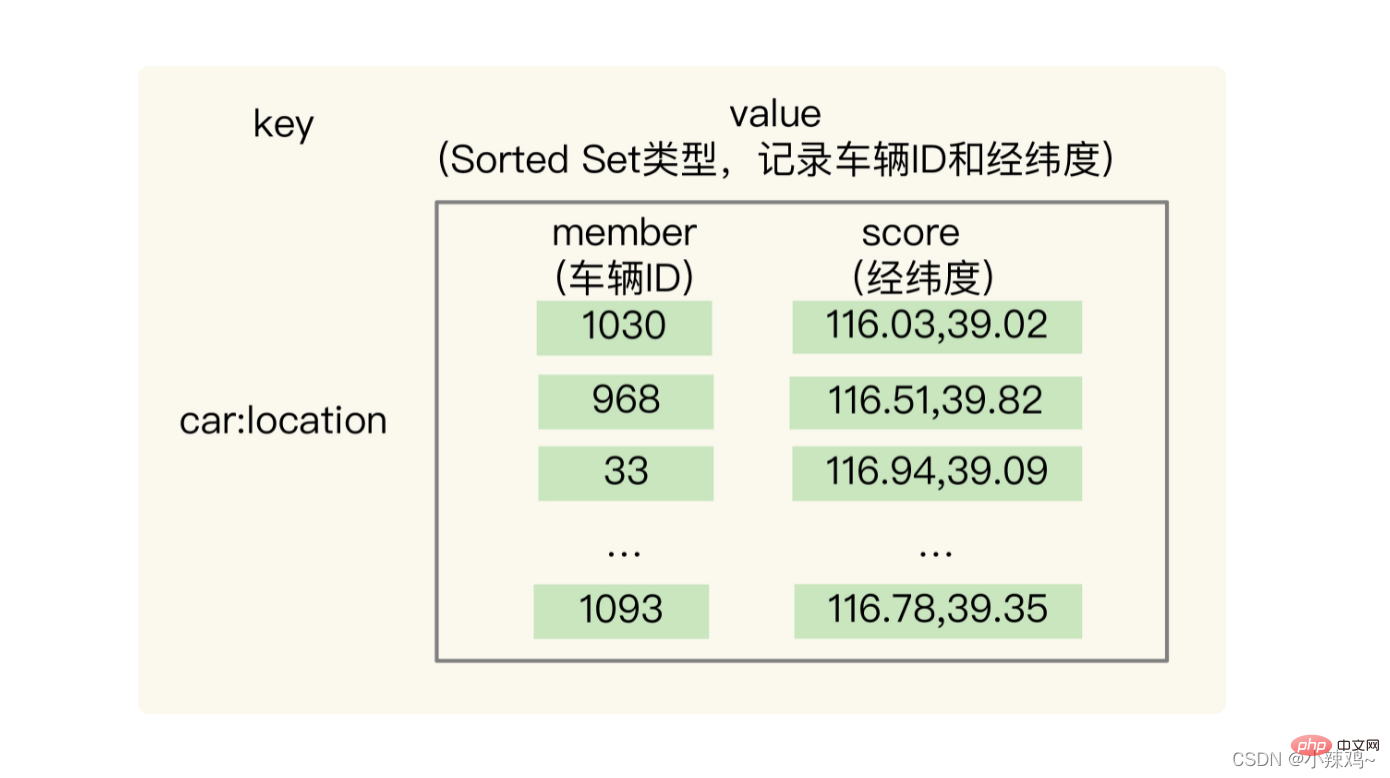
重みスコアのsorted Set は浮動小数点数 (float 型) ですが、経度と緯度は 2 つの数値であるため、GeoHash エンコードを使用する必要があります。
GeoHash エンコードは、「2 分割間隔、間隔エンコード」方式で実行されます。
最初に経度と緯度をコード化された形式に変換し、次に交差を実行します 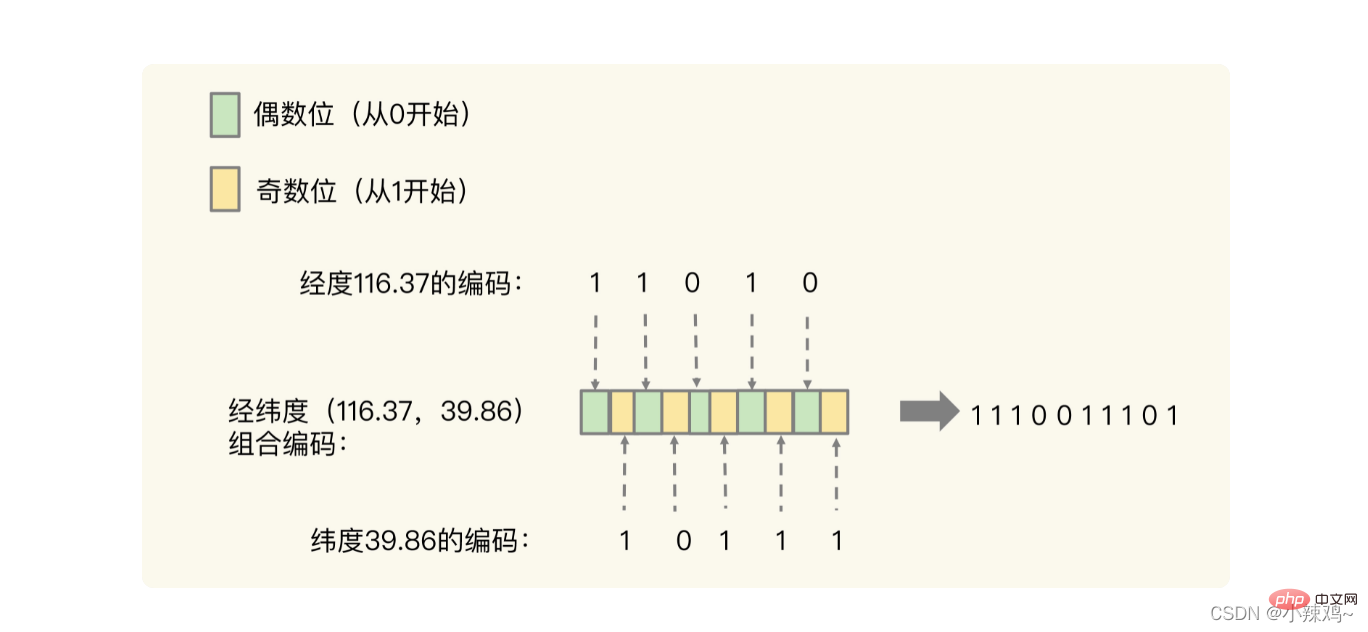
実際、交差の目的は次の図に示す概念です。実際に 2 次元の場所を特定できます。空間内の正方形では、ソート セット範囲クエリを使用して同様のコーディング値を取得します。実際の地理空間では、これらは隣接する正方形でもあります。たとえば、1110011101 と 1111011101 は空間内で隣接しています。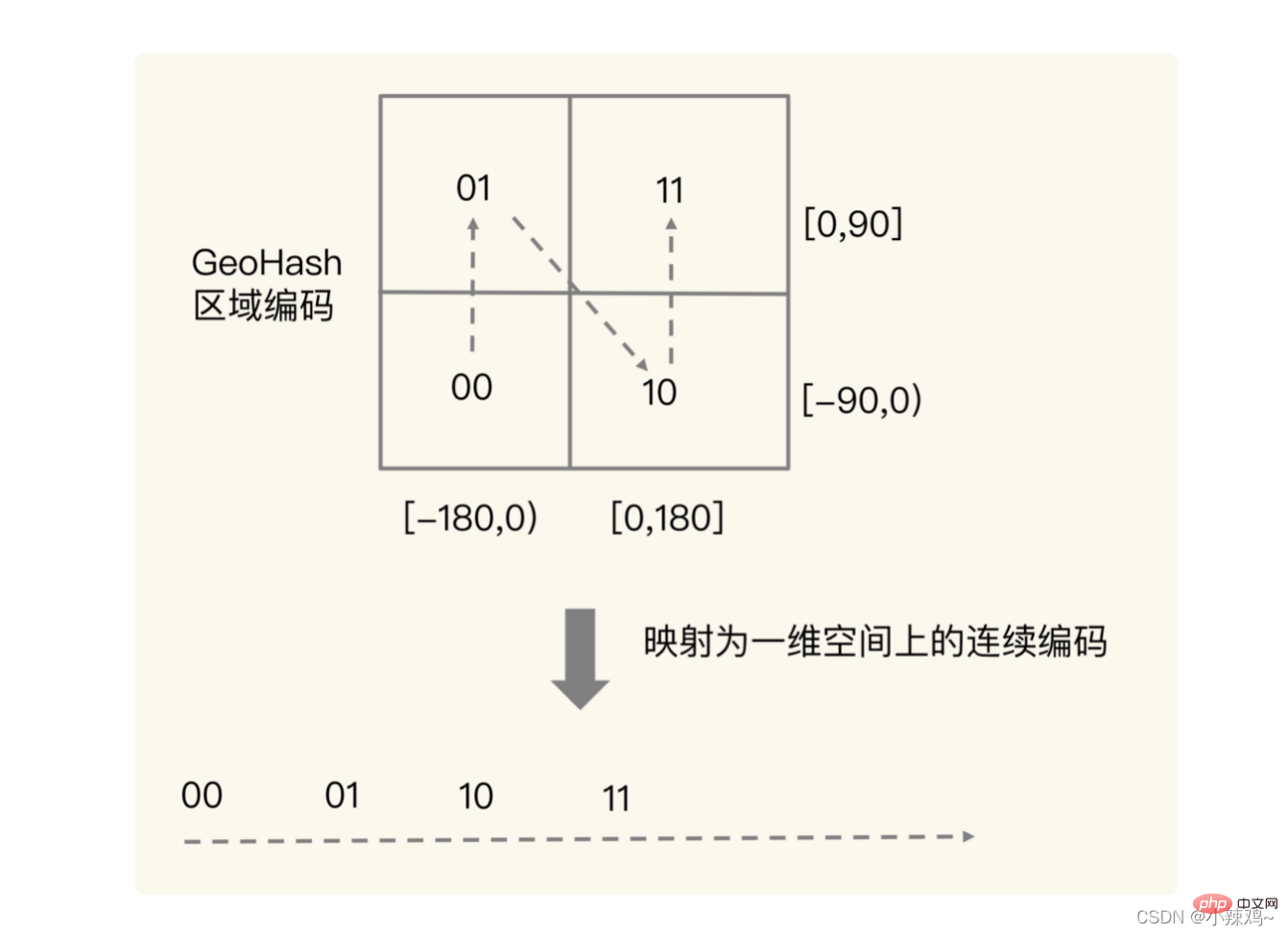
ただし、コードは隣接していても、実際には正方形が隣接していない場合もあります。したがって、この状況が発生するのを避けるために、特定の経度と緯度の周囲の 4 つまたは 8 つの正方形を同時にクエリすることができます。 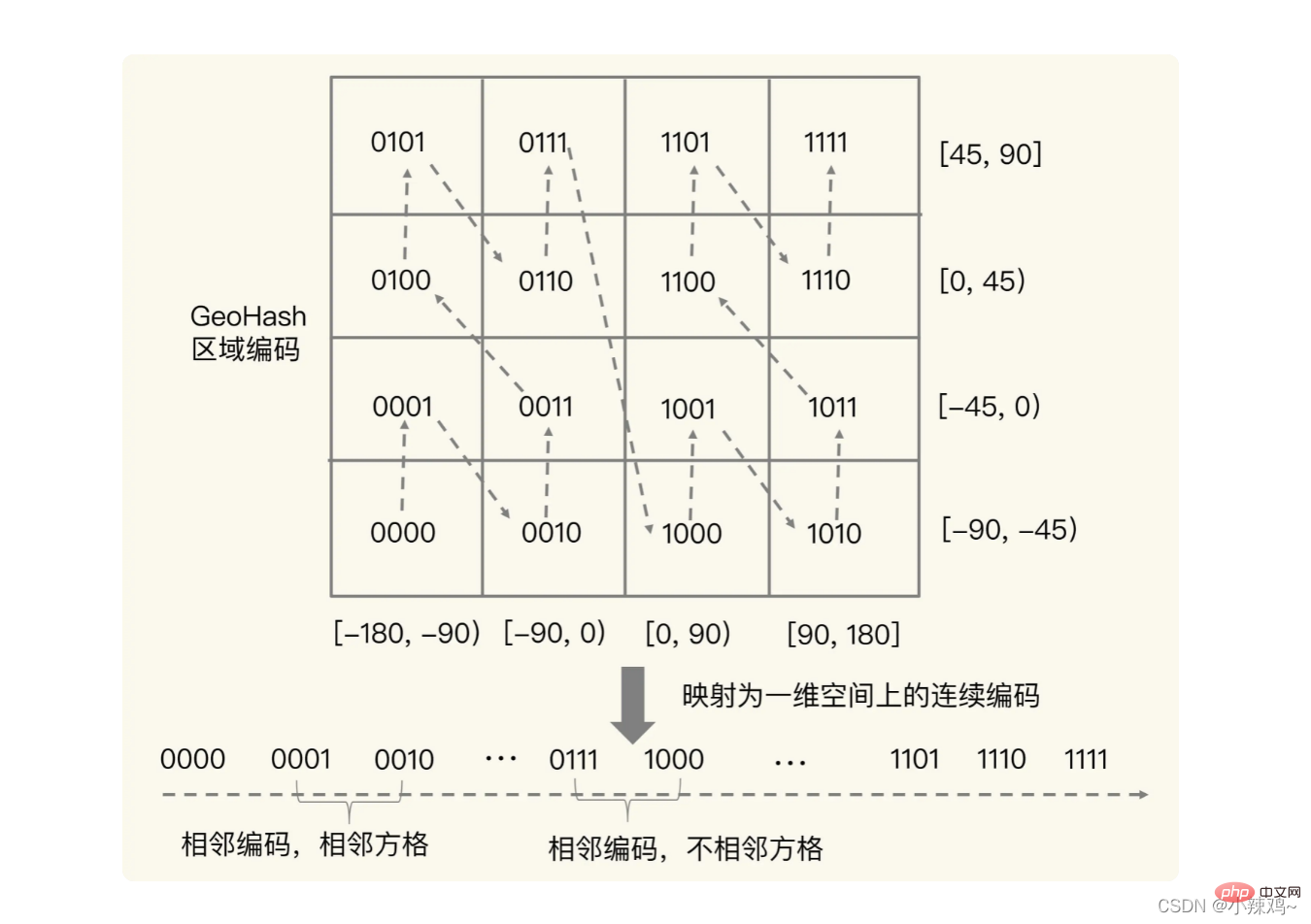 GEO タイプを使用する場合、よく使用する 2 つのコマンドは GEOADD と GEORADIUS です。
GEO タイプを使用する場合、よく使用する 2 つのコマンドは GEOADD と GEORADIUS です。
使用法: 車両 ID が 33 で、緯度と経度の位置が (116.034579, 39.030452) であるとします。GEO コレクションを使用して、すべての車両の緯度と経度を保存できます。コレクション キーは、cars:locations です。以下のコマンドを実行するだけで、ID 番号 33 の車両の現在の経度と緯度の位置が GEO に保存されます。
GEOADD cars:locations 116.034579 39.030452 33
NewTypeObject という名前のデータ構造を開発します。具体的には、次の 4 つの手順があります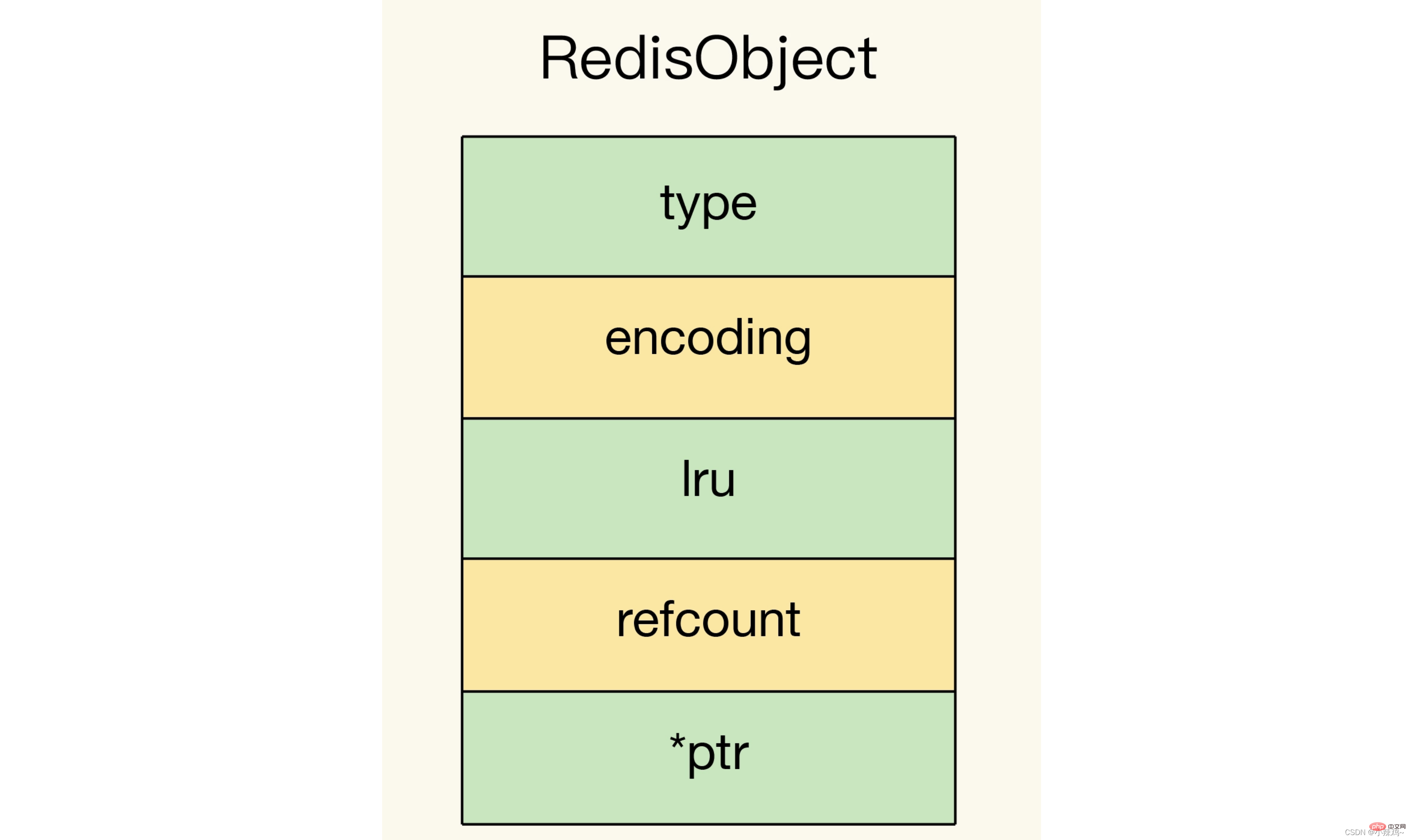
1. ハッシュとソート セットに基づいた保存: 2 つのデータ構造に基づいてクエリを実行する必要があるのはなぜですか?
ハッシュ型は時系列単一キークエリのニーズを満たす高速な単一キークエリを実現できます 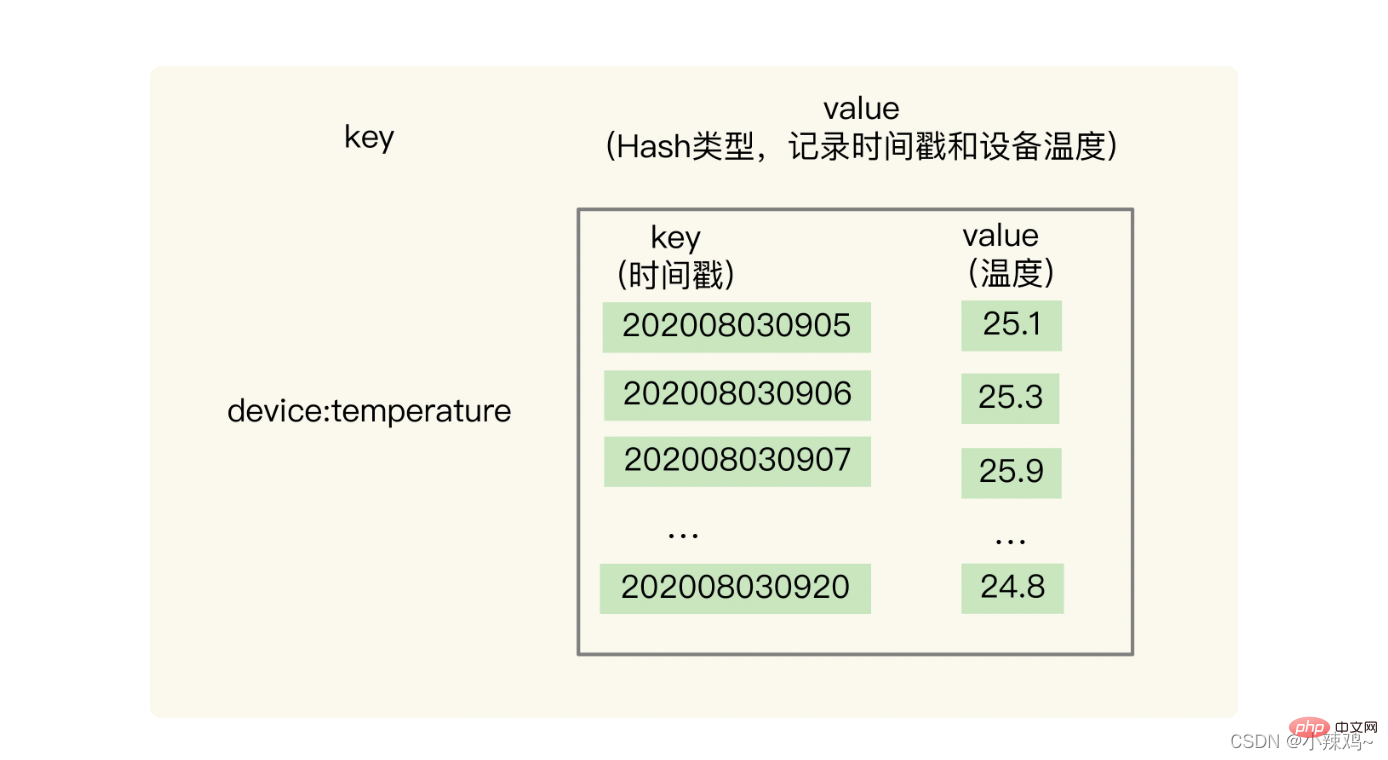
ただし、ハッシュ型には範囲クエリをサポートしていないという欠点があります。タイムスタンプ範囲クエリをサポートするには、要素の重みスコアに従ってソートするため、Through Sorted Set が必要です。 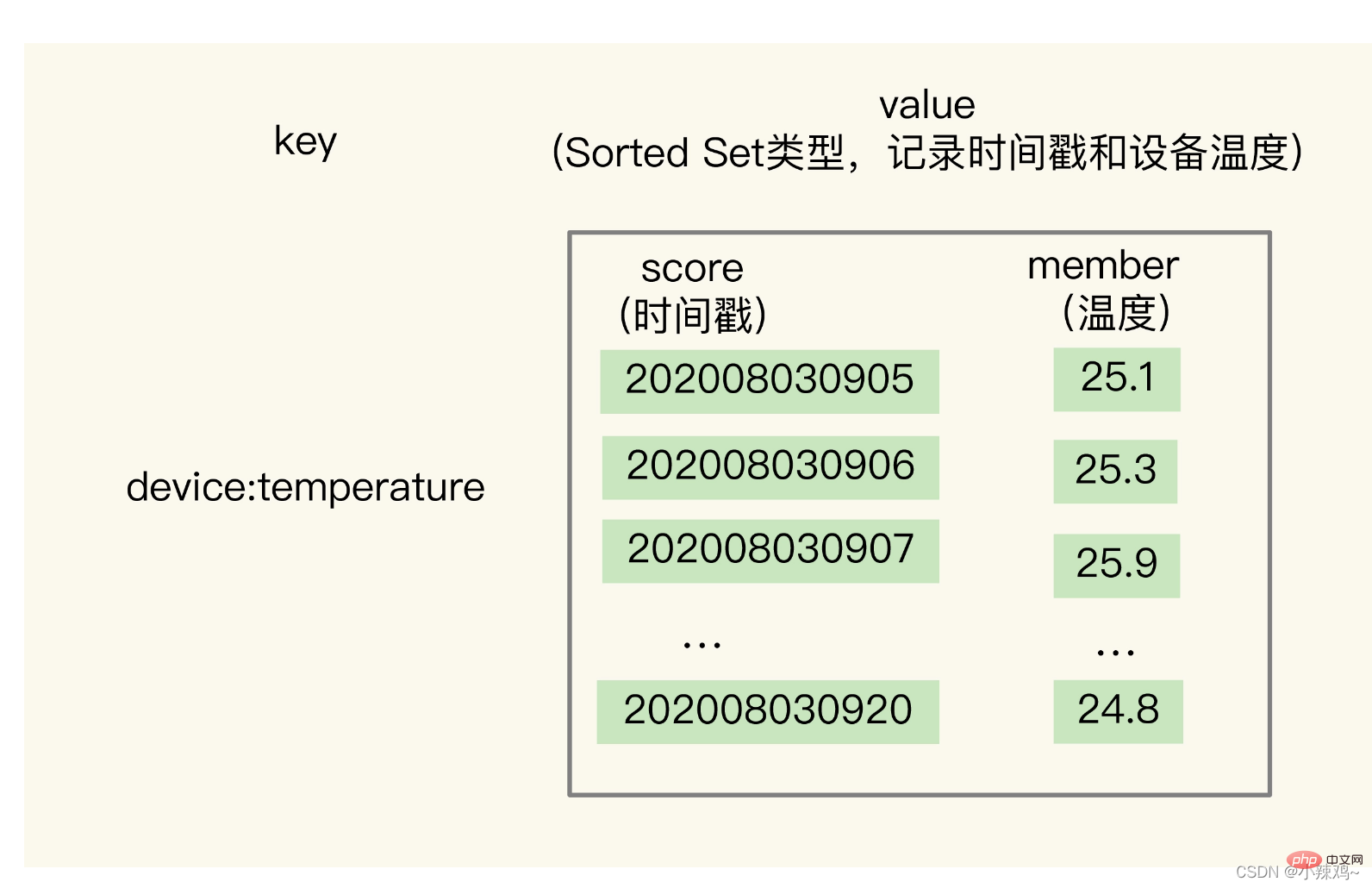
では、これら 2 つの操作のアトミック性を確保するにはどうすればよいでしょうか。
MULTI と EXEC の 2 つのコマンドを渡す必要があります:
MULTI は開始を意味します。このコマンドを受信すると、redis はコマンドをキューに入れます。
EXEC は終了を意味します。このコマンドを受信した後、開始されます。コマンド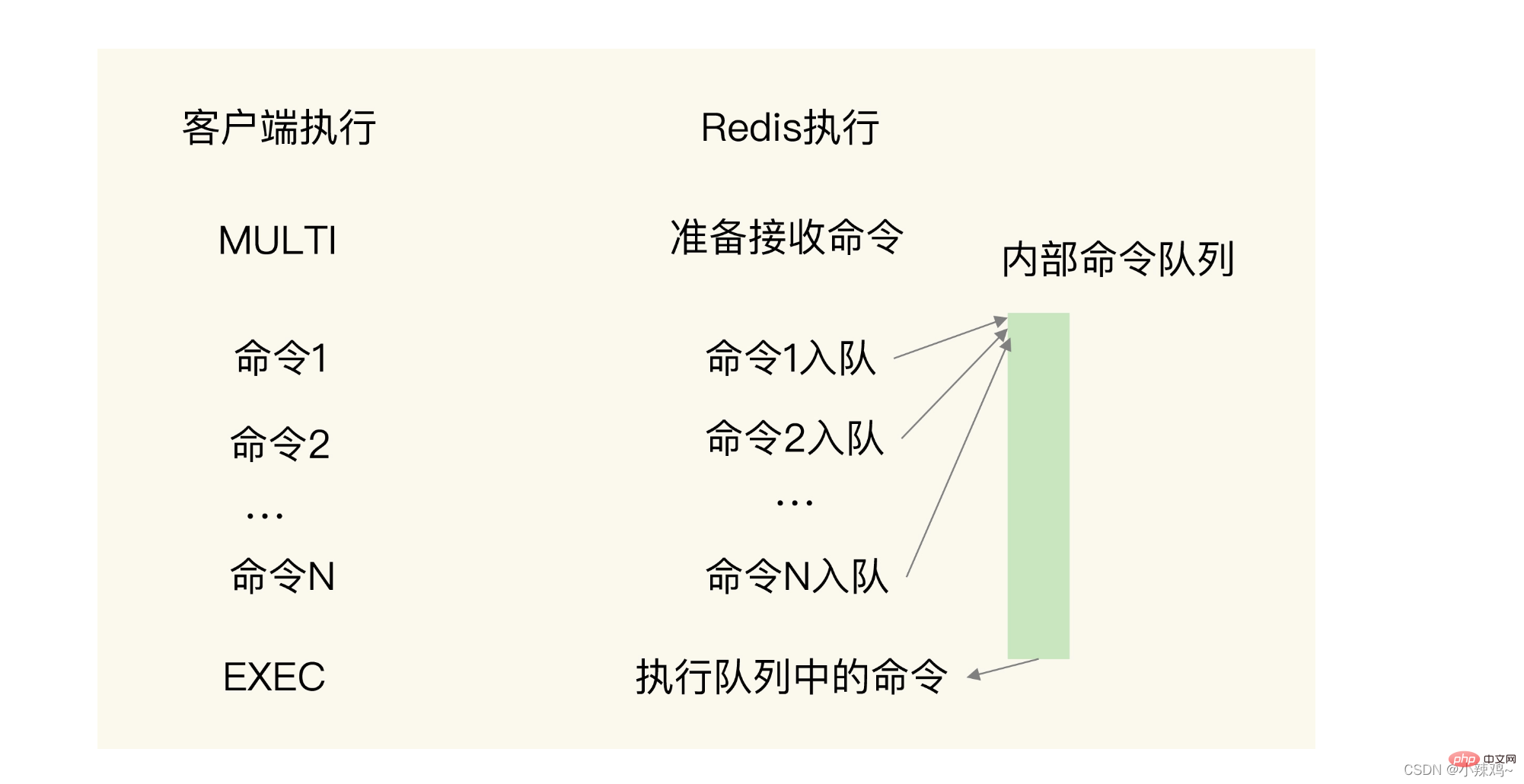
ただし、ハッシュとソート セットを使用する場合は、範囲クエリのみがサポートされ、集計計算はサポートされません。クライアント上で集計計算を実行すると、大量のネットワーク送信が発生します。したがって、RedisTimeSeries を通じて Redis 上で集計計算を実行できます。
推奨学習: Redis 学習チュートリアル
以上がRedisのデータ構造知識を画像と文章で詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



