


この記事では、python に関する関連知識を提供します。主に xpath に関連する問題を紹介します。XPath (XML Path Language の正式名) は、XML パス言語です。XML 内の言語です。言語ドキュメント内の情報を見つけるのに役立つと幸いです。

推奨学習: python チュートリアル
XPath (XML パス言語の正式名) は、XML パス言語です。 XML 言語 ドキュメント内の情報を検索するための言語。元々は XML ドキュメントの検索に使用されましたが、HTML ドキュメントの検索にも適しています。
XPath の選択機能は非常に強力です。非常に簡潔な情報を提供します。パス選択式。さらに、文字列、値、時刻を照合したり、ノードやシーケンスを処理したりするための 100 以上の組み込み関数も提供します。検索したいほぼすべてのノードは、XPath
# を使用して選択できます。 ##xpath 解析原理:pip install lxml
etree オブジェクトをインスタンス化する方法
etree. parse(filePath)#你的文件路径
2. ソース コード データは、インターネット このオブジェクトへの読み込み
etree.HtML('page_ text')#page_ text互联网中响应的数据| / | |
| // | |
| #. | |
| … | |
| @ | |
| * | |
| @* | |
| [@attrib] | |
| #[@attrib='value'] | 指定された値を持つ指定された属性を持つすべての要素を選択します |
| #[tag ] | 指定された要素を持つ直接の子ノードをすべて選択します |
| [tag='text'] | 指定された要素を持つすべてのノードを選択します要素であり、テキストコンテンツはテキストノードです。 |
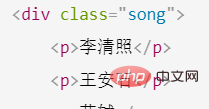
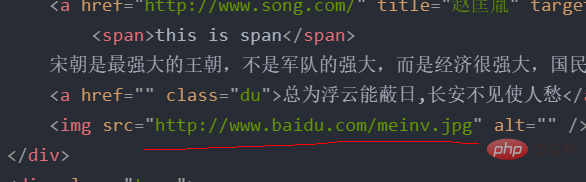
#对上面表达式的实例详解这是一个HTML的文档 <meta> <title>测试bs4</title> <p> </p><p>百里守约</p> <p> </p><p>李清照</p> <p>王安石</p> <p>苏轼</p> <p>柳宗元</p> <a> <span>this is span</span> 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a> <a>总为浮云能蔽日,长安不见使人愁</a> <img alt="Python の例の詳細な xpath 分析" > <p> </p> ログイン後にコピー
从浏览器中打开是这样的 子节点和子孙节点的定位 / 和 //先来看子节点和子孙节点,我们从上往下找p这个节点,可以看到p的父节点是body,body父节点是html import requestsfrom lxml import etree
tree = etree.parse('test.html')r1=tree.xpath('/html/body/p') #直接从上往下挨着找节点r2=tree.xpath('/html//p')#跳跃了一个节点来找到这个p节点的对象r3=tree.xpath('//p')##跳跃上面所有节点来寻找p节点的对象r1,r2,r3>>([<element>,
<element>,
<element>],
[<element>,
<element>,
<element>],
[<element>,
<element>,
<element>])</element></element></element></element></element></element></element></element></element>ログイン後にコピー 属性定位如果我只想要p里面song这一个标签,就可以对其属性定位 r4=tree.xpath('//p[@class="song"]')r4>>>[<element>]</element>ログイン後にコピー 索引定位如果我只想获得song里面的苏轼的这个标签 tree.xpath('//p[@class="song"]/p')>>[<element>,
<element>,
<element>,
<element>]</element></element></element></element>ログイン後にコピー 这个单独返回的苏轼的p标签,要注意的是这里的索引不是从0开始的,而是1 tree.xpath('//p[@class="song"]/p[3]')[<element>]</element>ログイン後にコピー 取文本比如我想取杜牧这个文本内容 tree.xpath('//p[@class="tang"]//li[5]/a/text()')>>['杜牧']ログイン後にコピー 可以看到这个返回的是一个列表,如果我们想取里面的字符串,可以这样 tree.xpath('//p[@class="tang"]//li[5]/a/text()')[0]杜牧ログイン後にコピー 看一个更直接的,//li 直接定位到 li这个标签,//text()直接将这个标签下的文本提取出来。但要注意,这样会把所有的li标签下面的文本提取出来,有时候你并不想要的文本也会提取出来,所以最好还是写详细一点,如具体到哪个p里的li。 tree.xpath('//li//text()')['清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村',
'秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山',
'岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君',
'杜甫',
'杜牧',
'杜小月',
'度蜜月',
'凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘']ログイン後にコピー 取属性比如我想取下面这个属性 tree.xpath('//p[@class="song"]/img/@src')['http://www.baidu.com/meinv.jpg']ログイン後にコピー 或者如果我想取所有的href这个属性,可以看到tang和song的所有href属性 tree.xpath('//@href')['http://www.song.com/',
'',
'http://www.baidu.com',
'http://www.163.com',
'http://www.126.com',
'http://www.sina.com',
'http://www.dudu.com',
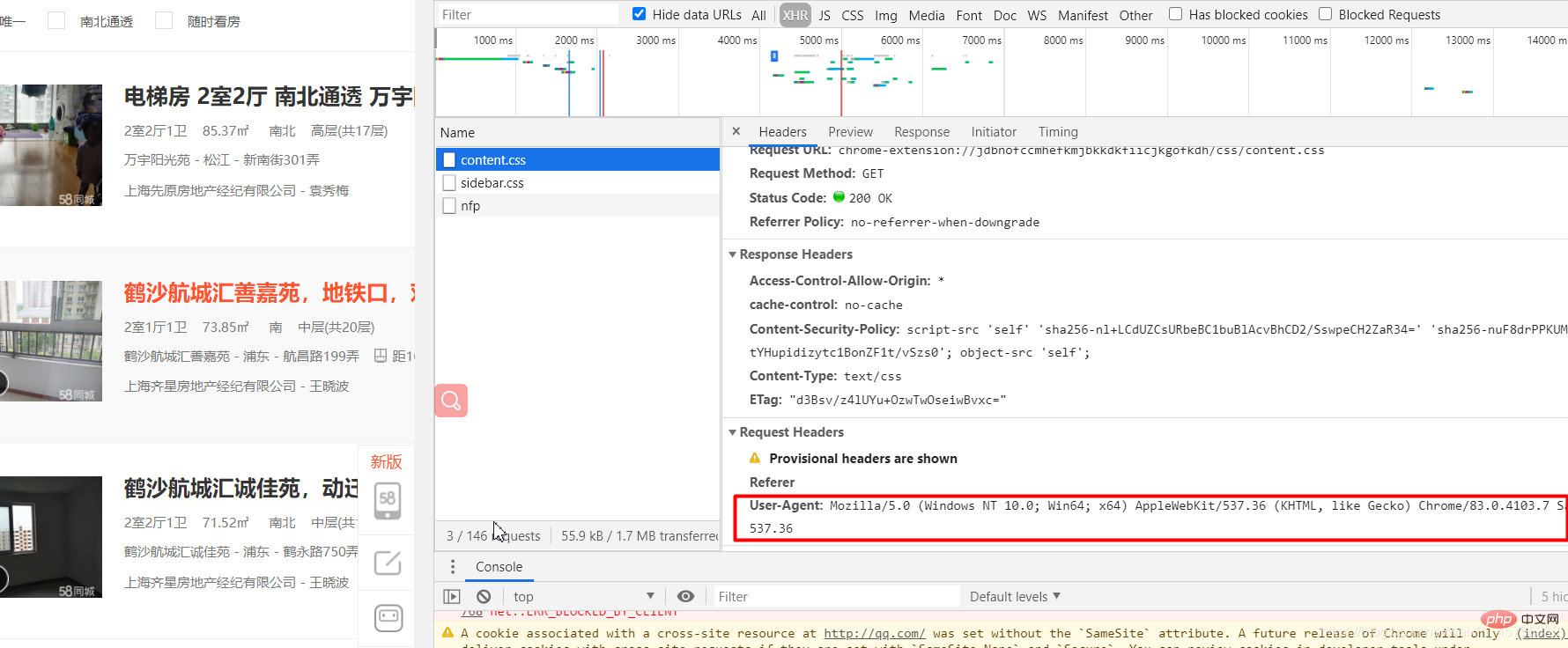
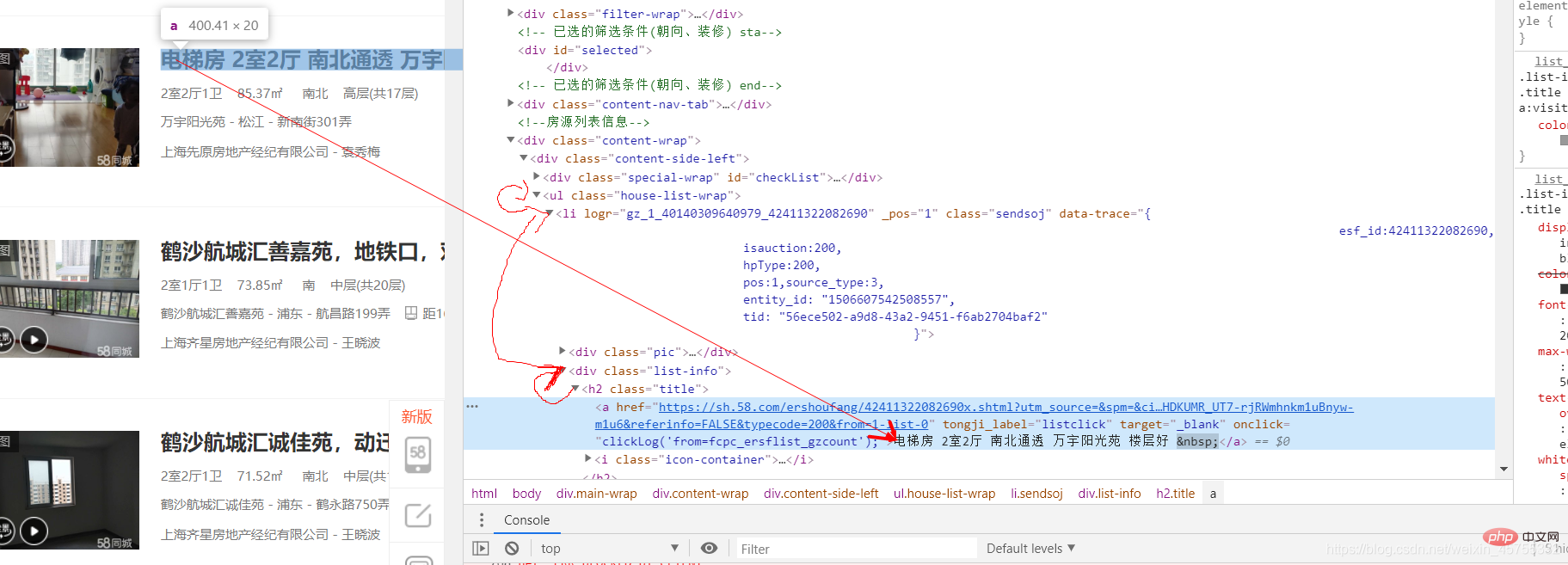
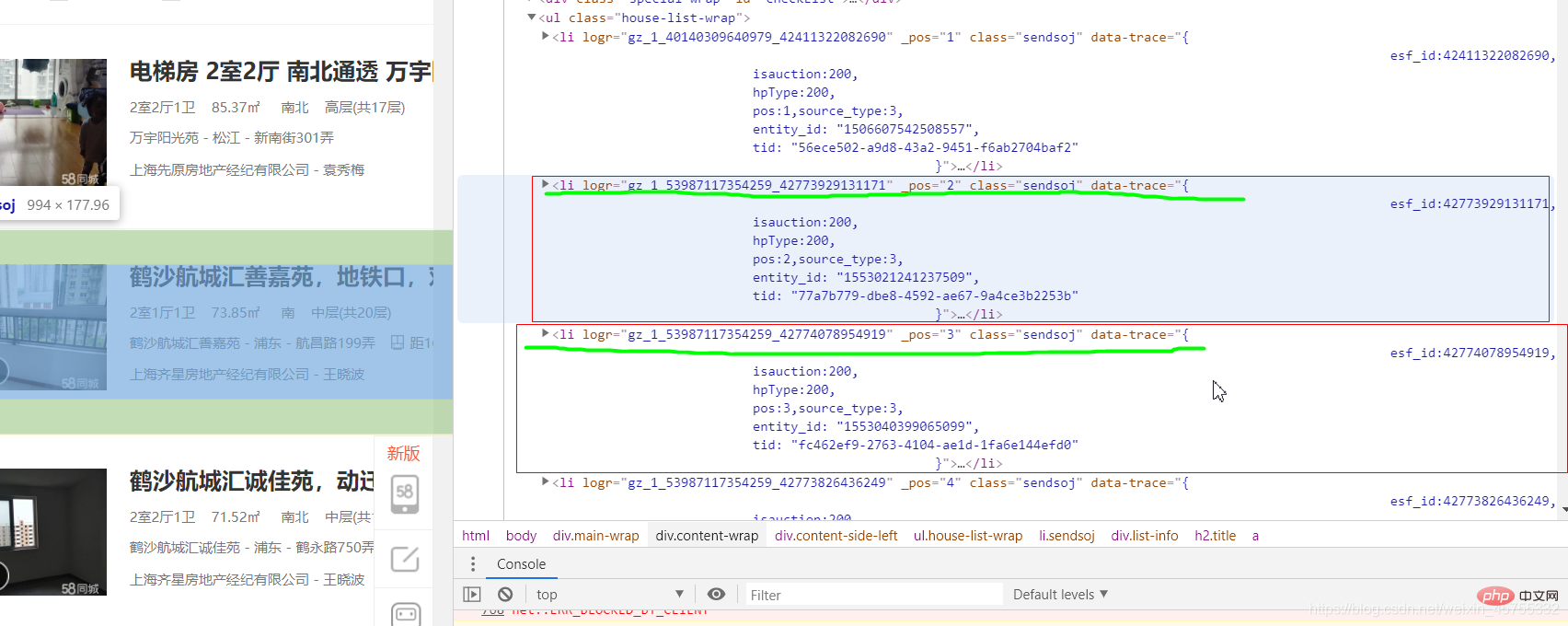
'http://www.haha.com']ログイン後にコピー 爬虫实战之58同城房源信息#导入必要的库import requestsfrom lxml import etree#URL就是网址,headers看图一url='https://sh.58.com/ershoufang/'headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.7 Safari/537.36'}#对网站发起请求page_test=requests.get(url=url,headers=headers).text# 这里是将从互联网上获取的源码数据加载到该对象中tree=etree.HTML(page_test)#先看图二的解释,这里li有多个,所里返回的li_list是一个列表li_list=tree.xpath('//ul[@class="house-list-wrap"]/li')#这里我们打开一个58.txt文件来保存我们的信息fp=open('58.txt','w',encoding='utf-8')#li遍历li_listfor li in li_list:
#这里 ./是对前面li的继承,相当于li/p...
title=li.xpath('./p[2]/h2/a/text()')[0]
print(title+'\n')
#把文件写入文件
fp.write(title+'\n')fp.close()ログイン後にコピー 图一:
推荐学习:python教程 |
以上がPython の例の詳細な xpath 分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



