


この記事では、python に関する関連知識を提供します。主に、タプルの作成、アクセス、変更、削除、組み込みメソッドなど、タプルに関連する問題を紹介します。助けるために。

推奨学習: python チュートリアル
はじめに - Python では、プロジェクト内の重要なデータ情報はデータ構造を通じて保存されます。 Python 言語には、リスト、タプル、辞書、セットなどのさまざまな組み込みデータ構造があります。このクラスでは、Python で最も重要なデータ構造の 1 つであるタプルについて説明します。
Python では、タプルを特別な種類のリストとして考えることができます。リストとの唯一の違いは、タプル内のデータ要素を変更できないことです [これは変更されません。データ項目を変更できないだけでなく、データ項目の追加や削除もできません。 】。不変データのセットを作成する必要がある場合、通常はデータをタプルに入れます~
Python では、タプルを作成する基本的な形式は、データ要素を括弧「()」で囲み、各要素をカンマ「,」で区切ることです。
は次のとおりです:
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
# 而且——是可以创建空元组哦!
tuple3 = ()
# 小注意——如果你创建的元组只包含一个元素时,也不要忘记在元素后面加上逗号。让其识别为一个元组:
tuple4 = (22, )タプルは文字列やリストと似ており、インデックスは 0 から始まり、インターセプトして合計することができます。 . 組み合わせやその他の操作。
は次のとおりです:
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
# 显示元组中索引为1的元素的值
print("tuple1[1]:", tuple1[0])
# 显示元组中索引从1到3的元素的值
print("tuple2[1:3]:", tuple2[1:3])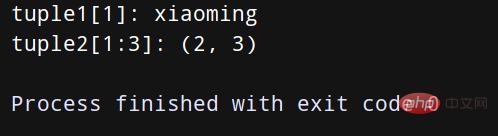
最初にタプルは不変であると言われましたが、タプル間の接続と組み合わせという操作もサポートされています:
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
tuple_new = tuple1 + tuple2
print(tuple_new)
タプルは不変ですが、del ステートメントを使用してタプル全体を削除できます。
は次のとおりです:
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
print(tuple1) # 正常打印tuple1
del tuple1
print(tuple1) # 因为上面删除了tuple1,所以再打印会报错哦!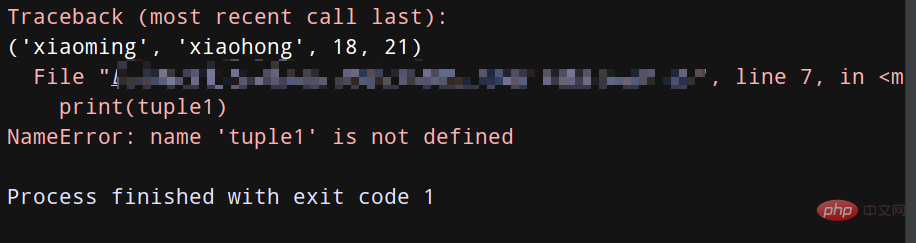
タプルは不変ですが、変更することもできます。 pass 組み込みメソッドを使用してタプルを操作します。一般的に使用される組み込みメソッドは次のとおりです:
実際には、最初にタプルをリストに変換し、操作後にタプルに変換することが多いです (リストには多くのメソッドがあるため~)。
Python では、N 個の要素を含むタプルまたはシーケンスを N 個に分割できます。個別の変数。これは、Python 構文では、単純な代入操作を通じて任意のシーケンス/反復可能なオブジェクトを個別の変数に分解できるためです。唯一の要件は、変数の合計数と構造がシーケンスと一致することです。
は次のとおりです:
tuple1 = (18, 22) x, y = tuple1 print(x) print(y) tuple2 = ['xiaoming', 33, 19.8, (2012, 1, 11)] name, age, level, date = tuple2 print(name) print(date)

不明な長さまたは任意の長さの反復可能なオブジェクトを分解したい場合、上記の分解操作は必要ありません。とても素敵になってね!通常、このタイプの反復可能オブジェクトには、既知のコンポーネントまたはパターンがいくつかあります (たとえば、要素 1 以降はすべて電話番号です)。「*」アスタリスク式を使用して反復可能オブジェクトを分解した後、開発者はこれらのパターンを簡単に利用して、反復可能なオブジェクトで複雑な操作を行うことなく、関連する要素を操作できます。
Python では、アスタリスク式は、タプルの可変長シーケンスを反復処理するときに非常に便利です。以下は、マークされる一連のタプルを分解するプロセスを示しています。
records = [
('AAA', 1, 2),
('BBB', 'hello'),
('CCC', 5, 3)
]
def do_foo(x, y):
print('AAA', x, y)
def do_bar(s):
print('BBB', s)
for tag, *args in records:
if tag == 'AAA':
do_foo(*args)
elif tag == 'BBB':
do_bar(*args)
line = 'guan:ijing234://wef:678d:guan'
uname, *fields, homedir, sh = line.split(':')
print(uname)
print(*fields)
print(homedir)
print(sh)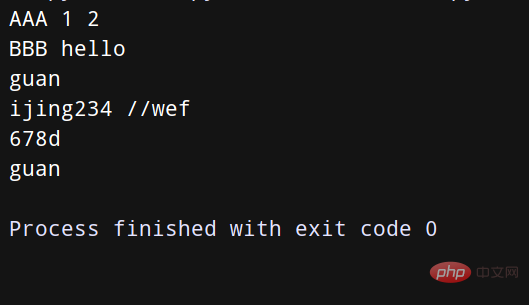
Python でリストやタプルなどのシーケンスを繰り返し処理する場合、最後のものをカウントする必要がある場合があります。履歴統計機能を実現するために少数の項目を記録します。
組み込みの両端キュー実装の使用:
from _collections import deque q = deque(maxlen=3) q.append(1) q.append(2) q.append(3) print(q) q.append(4) print(q)

は次のとおりです。履歴記録プロセスとしてのシーケンス。
from _collections import deque
def search(lines, pattern, history=5):
previous_lines = deque(maxlen=history)
for line in lines:
if pattern in line:
yield line, previous_lines
previous_lines.append(line)
# Example use on a file
if __name__ == '__main__':
with open('123.txt') as f:
for line, prevlines in search(f, 'python', 5):
for pline in prevlines: # 包含python的行
print(pline) # print (pline, end='')
# 打印最后检查过的N行文本
print(line) # print (pline, end='')123.txt:
pythonpythonpythonpythonpythonpythonpython python python
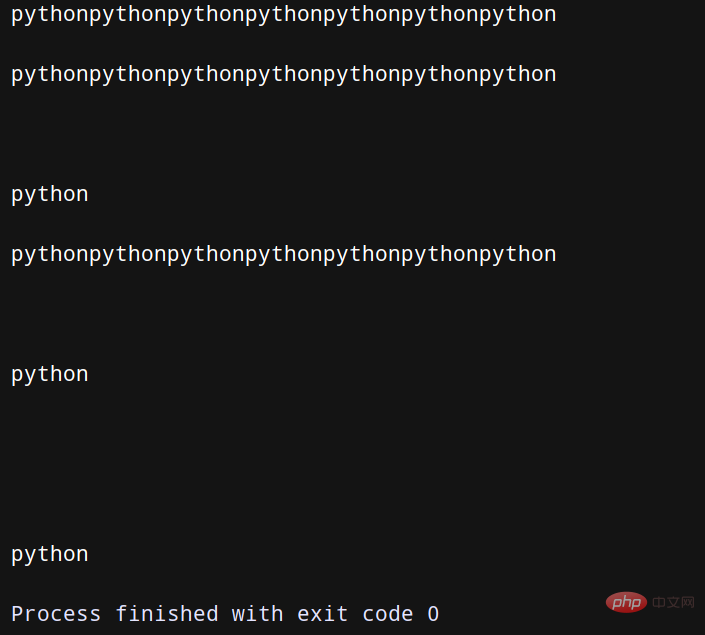
在上述代码中,对一系列文本行实现了简单的文本匹配操作,当发现有合适的匹配时,就输出当前的匹配行以及最后检查过的N行文本。使用deque(maxlen=N)创建了一个固定长度的队列。当有新记录加入而使得队列变成已满状态时,会自动移除最老的那条记录。当编写搜索某项记录的代码时,通常会用到含有yield关键字的生成器函数,它能够将处理搜索过程的代码和使用搜索结果的代码成功解耦开来。
使用内置模块heapq可以实现一个简单的优先级队列。
如下——演示了实现一个简单的优先级队列的过程。
import heapq
class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0
def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1
def pop(self):
return heapq.heappop(self._queue)[-1]
class Item:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'Item({!r})'.format(self.name)
q = PriorityQueue()
q.push(Item('AAA'), 1)
q.push(Item('BBB'), 4)
q.push(Item('CCC'), 5)
q.push(Item('DDD'), 1)
print(q.pop())
print(q.pop())
print(q.pop())在上述代码中,利用heapq模块实现了一个简单的优先级队列,第一次执行pop()操作时返回的元素具有最高的优先级。
拥有相同优先级的两个元素(foo和grok)返回的顺序,同插入到队列时的顺序相同。
函数heapq.heappush()和heapq.heappop()分别实现了列表_queue中元素的插入和移除操作,并且保证列表中的第一个元素的优先级最低。
函数heappop()总是返回“最小”的元素,并且因为push和pop操作的复杂度都是O(log2N),其中N代表堆中元素的数量,因此就算N的值很大,这些操作的效率也非常高。
上述代码中的队列以元组 (-priority, index, item)的形式组成,priority取负值是为了让队列能够按元素的优先级从高到底排列。这和正常的堆排列顺序相反,一般情况下,堆是按从小到大的顺序进行排序的。变量index的作用是将具有相同优先级的元素以适当的顺序排列,通过维护一个不断递增的索引,元素将以它们加入队列时的顺序排列。但是当index在对具有相同优先级的元素间进行比较操作,同样扮演一个重要的角色。
在Python中,如果以元组(priority, item)的形式存储元素,只要它们的优先级不同,它们就可以进行比较。但是如果两个元组的优先级相同,在进行比较操作时会失败。这时可以考虑引入一个额外的索引值,以(priority, index, item)的方式建立元组,因为没有哪两个元组会有相同的index值,所以这样就可以完全避免上述问题。一旦比较操作的结果可以确定,Python就不会再去比较剩下的元组元素了。
如下——演示了实现一个简单的优先级队列的过程:
import heapq
class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0
def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1
def pop(self):
return heapq.heappop(self._queue)[-1]
class Item:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'Item({!r})'.format(self.name)
# ①
a = Item('AAA')
b = Item('BBB')
#a <p><img src="https://img.php.cn/upload/article/000/000/067/49d26f0b616718a47cdbeebb6cfbf35b-7.png" alt="Python タプルの例を示した詳細な説明"></p><p>在上述代码中,因为在1-2中没有添加所以,所以当两个元组的优先级相同时会出错;而在3-4中添加了索引,这样就不会出错了!</p><p>推荐学习:<a href="//m.sbmmt.com/course/list/30.html" target="_blank">python学习教程</a></p>以上がPython タプルの例を示した詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



