


#MySQL チュートリアル #コラムで紹介したインデックスに B Tree を使用する理由
 #序文
#序文
##この記事のタイトルは、私が面接中に遭遇した実際の問題です。インターネット クラウドファンディング会社は、面接官の MySQL 関連の知識をテストする際に最初の質問をしました。 , 当時はかなり混乱していました。この若者が武道の倫理に従わず、ルーティンに従ってカードをプレイしなかったとは予想していませんでした。一般に人々が MySQL 関連の知識について尋ねたとき、彼らはそうではありませんでしたインデックスの最適化、インデックスの失敗、その他の関連問題について常に質問しますか?なんで出てきたの? 保存ファイルが違うの? MVCCの仕組みを調べてもそうなります。そこで今回はこの部分の知識ポイントをまとめていきます。
インデックスを作成する必要がある理由まず、インデックスを作成する目的はクエリの速度を向上させることであることは誰もが知っています。インデックスを使用するとクエリ速度が向上しますか? インデックスの模式図を見てみましょう。
SQL ステートメントがあるとします:
select * from Table where id = 15
次に、インデックスがない場合、テーブル全体のスキャンが実際に実行されます。 id=15 のレコードが見つかるまで 1 つずつ検索します (時間計算量は O(n); 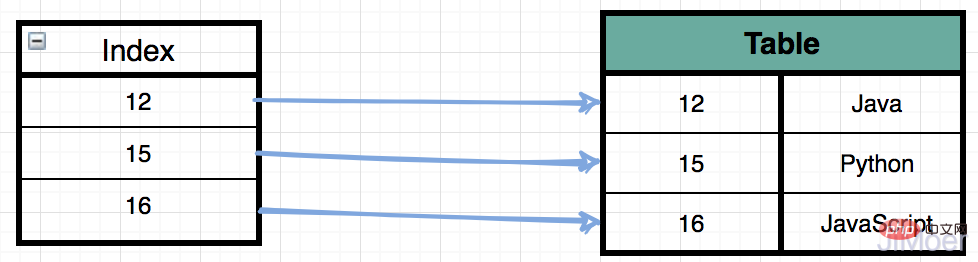
インデックスを使用してクエリするとどうなるでしょうか?まず、id=15 に基づいてインデックス値でバイナリ検索が実行されます。バイナリ検索の効率は非常に高く、その時間計算量は O(logn) です。これが、インデックスによってクエリを改善できる理由です。ただし、インデックス データの量も比較的大きいため、通常はメモリに保存されず、ディスクに直接保存されるため、ディスク内のファイルの内容を読み取るときにディスク IO が発生することは避けられません。
上で述べたように、インデックス データは通常ディスクに保存されますが、計算されたデータはメモリ内に存在する必要があります。非常に大きく、一度にメモリにロードできないため、データ検索にインデックスを使用する場合、複数のディスク IO が実行されて、インデックス データがバッチでメモリにロードされます。 したがって、正しい結果を得るために、インデックス データ構造はディスク IO 回数が最小限である必要があります。
<strong></strong>ハッシュ タイプ
現在、MySQL には実際に 2 つのインデックス データ タイプから選択できます。1 つは BTree (実際には B Tree)、A ハッシュです。 。 しかし、実際に使用する場合、ほとんどの人が BTree を選択するのはなぜでしょうか?
ハッシュ タイプのインデックスを使用する場合、MySQL はインデックスの作成時にインデックス データに対してハッシュ操作を実行するため、たとえデータ量が多くても、ハッシュ値に基づいてディスク ポインタをすぐに見つけることができます。データが大きい場合でも、データを迅速かつ正確に見つけることができます。
ただし、select * from Table where id > 15
のような範囲クエリの場合、ハッシュ型インデックスは処理できません。この範囲クエリの場合、テーブル全体が直接スキャンされます。ハッシュ型インデックスはソートできません。では、なぜ MySQL はインデックス データ構造としてバイナリ ツリーを持たないのでしょうか?バイナリ ツリーはバイナリ検索を通じてデータを見つけるため、効果は依然として良好で、時間計算量は O(logn);
ただし、バイナリ ツリーには問題があります。特殊な状況下では、棒、つまり一方向の連結リストに退化します。このとき、時間計算量は O(n);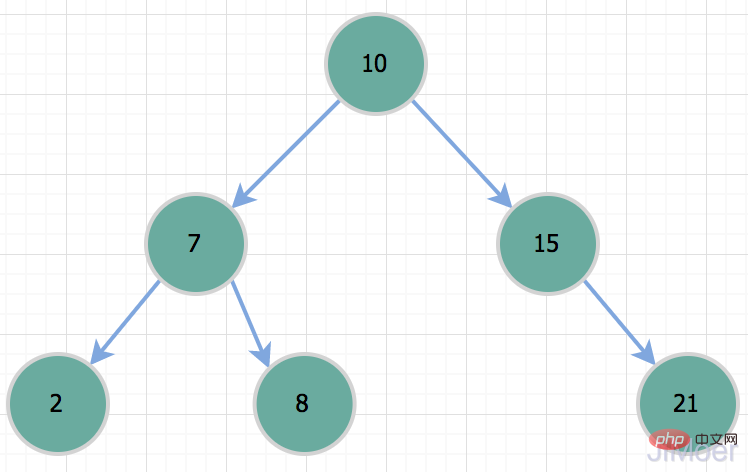 したがって、id=50 のレコードをクエリする場合、実際にはテーブル全体のスキャンと同じになります。このような状況のため、二分木はインデックス データ構造としては適していません。
したがって、id=50 のレコードをクエリする場合、実際にはテーブル全体のスキャンと同じになります。このような状況のため、二分木はインデックス データ構造としては適していません。 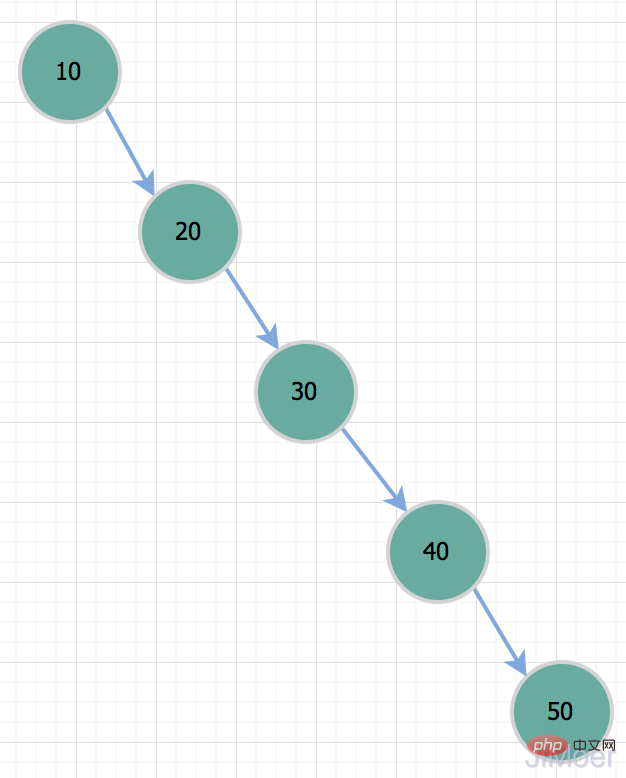 バランス型二分木
バランス型二分木
では、特殊な状況下では二分木はリンク リストに縮退するので、なぜバランス型二分木を使用できないのでしょうか?
バランスのとれたバイナリ ツリーの子ノード間の高さの差は 1を超えることはできません。下の図のバイナリ ツリーのように、キー 15 を持つノードの高さは 0 です。左側の子ノードとその右側の子ノードの高さ 0 は 1 であり、高さの差は 1 を超えないため、以下のツリーはバランスのとれた二分木です。
バランスを保つことができるため、クエリ時間の計算量は O(logN) になります。バランスを保つ方法としては、主に左回転、右回転などを行う必要があります。バランスの維持に関する具体的な内容はこの記事には記載されていないので、主な内容を知りたい場合は、自分で検索してください。 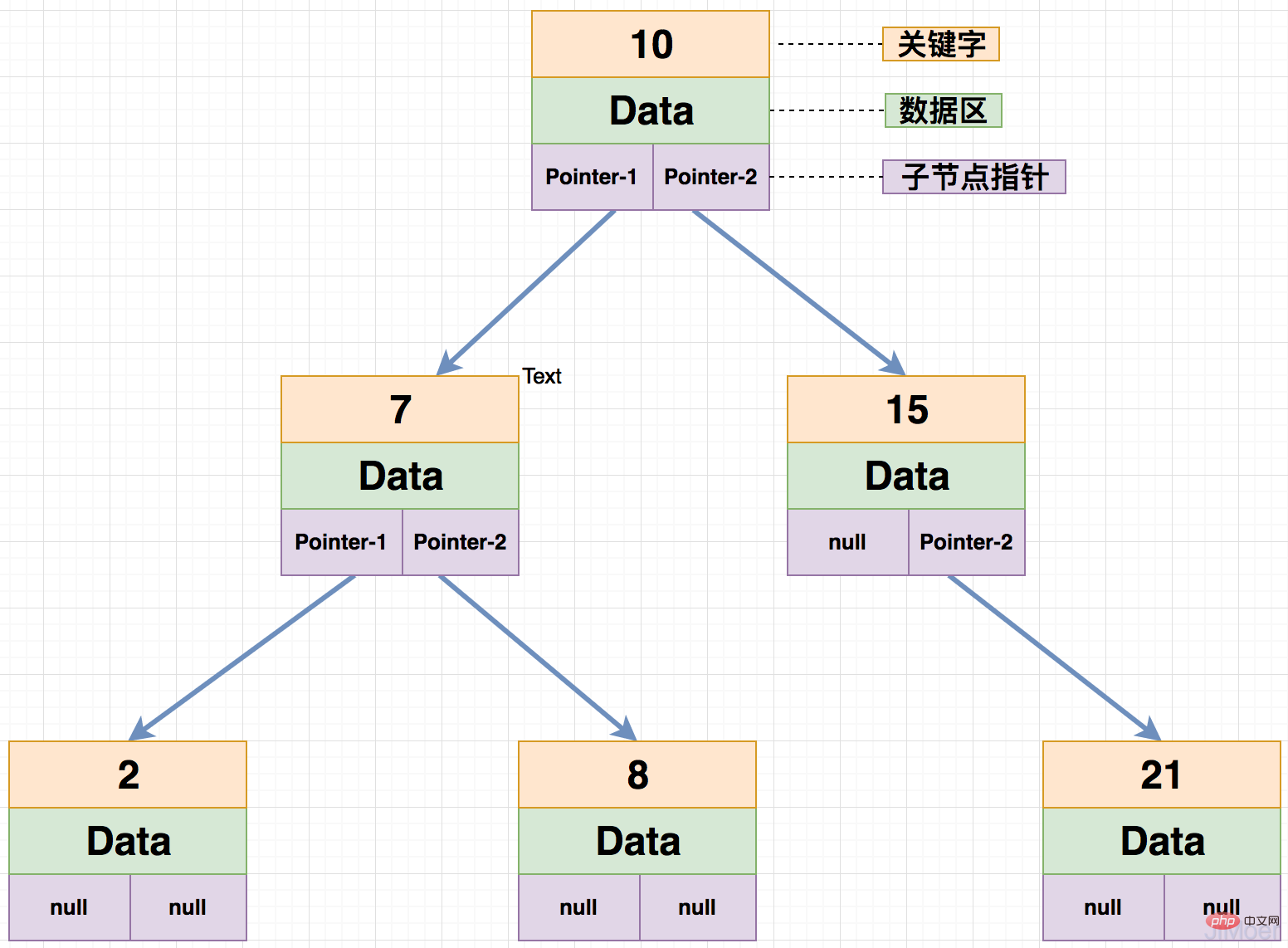 このデータ構造を使用して MySQL のインデックスを作成する場合、どのような問題がありますか?
このデータ構造を使用して MySQL のインデックスを作成する場合、どのような問題がありますか?
バイナリ ツリーはバランスの問題を解決しますが、新たな問題ももたらします。つまり、それ自体のツリーの深さが原因で、一連の効率の問題が発生します。
したがって、バイナリ ツリーのバランスをとる問題を解決するには、バランスの取れたマルチツリー (バランス ツリー) がより良い選択肢になりました。
バランス ツリー – B ツリー
B ツリーとは、バランスのとれたマルチ ツリーを意味します。一般に、B ツリー内のノードには子ノードの数が含まれます。その次数の B ツリーを呼び出します。通常 m は次数を表すために使用されますが、m が 2 の場合は平衡二分木になります。
B ツリーの各ノードには最大で m-1 個のキーワードを含めることができ、少なくとも Math.ceil(m/2)-1 個のキーワードを保存する必要があります。はすべて同じレイヤー上にあります。下の図は 4 次 B ツリーです。 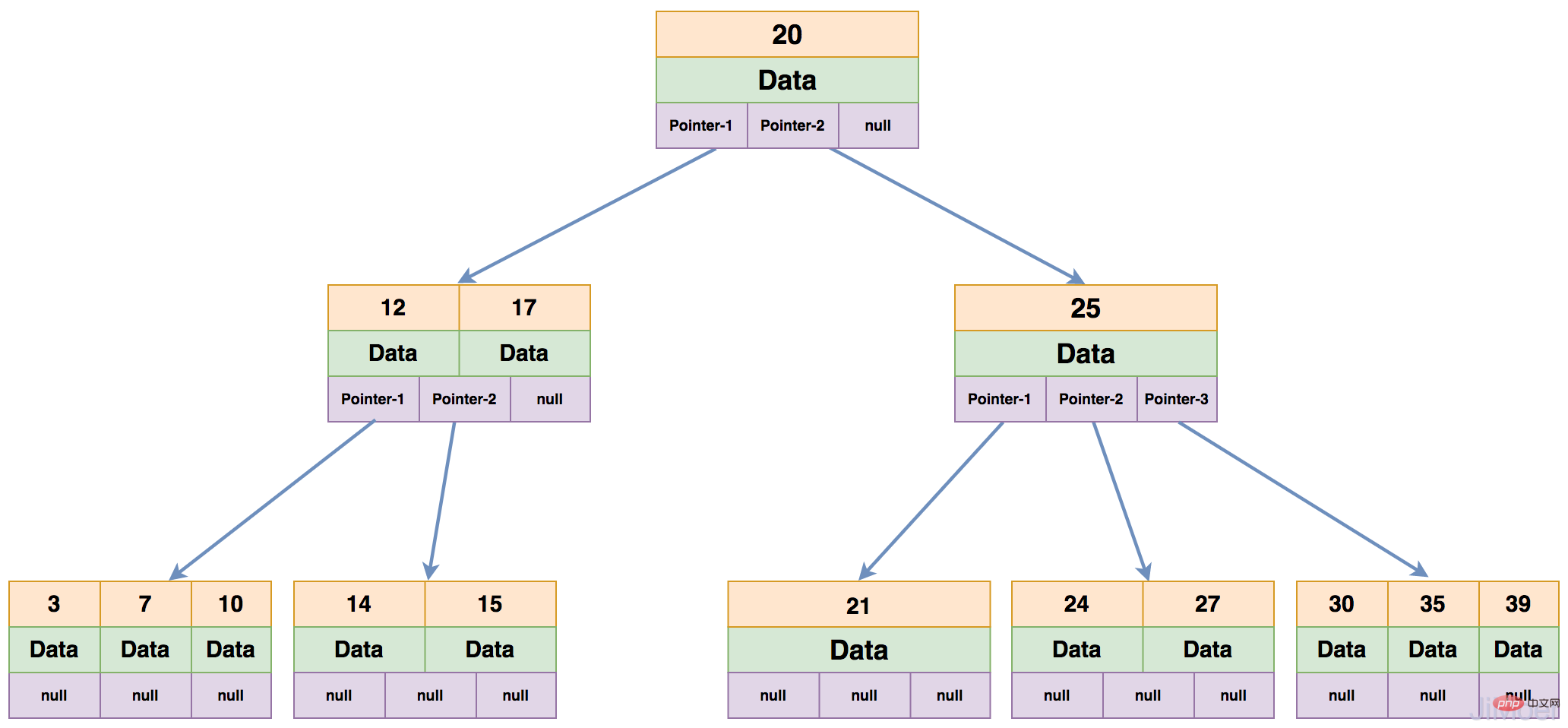
次に、B ツリーがデータを検索する方法を見てみましょう:
このように、実際には操作全体で 3 つの IO 操作が実行されますが、実際には、一般的な B ツリーには各層に多くの分岐 (通常は 100 を超える) があります。
ディスクの IO 機能をより有効に活用するために、MySQL は操作ページのサイズを 16K に設定します。つまり、各ノードのサイズは 16K です。各ノードのキーワードが int 型の場合は 4 バイト、データ領域のサイズが 8 バイトでノード ポインタがさらに 4 バイトを占める場合、B ツリーの各ノードに含まれるキーワードの数保存できるのは: (16*1000) / (4 8 4)=1000. 各ノードは最大 1000 個のキーワードを保存でき、各ノードは最大 1001 個のブランチ ノードを持つことができます。
このようにして、インデックス データをクエリするとき、1 回のディスク IO 操作で 1000 個のキーワードをメモリに読み込んで計算できます。B ツリーの 1 回のディスク IO 操作でバイナリ データのバランスが取れます。N 回のディスク IO 操作が実行されています。実行されました。
:B-Tree は、データのバランスを確保するために一連の操作を実行することに注意してください。バランスをとるには比較的時間がかかります。そのため、インデックスを作成するときは、適切なフィールドを選択する必要があり、あまりにも多くのインデックスを作成しないでください。作成するインデックスが多すぎると、データを更新するときにインデックスを更新するプロセスに時間がかかります。 。
また 性別フィールドなど、識別度の低いフィールド値をインデックスとして選択しないでください。値は合計 2 つしかありません。そうすると、B の深さが発生する可能性があります。 - ツリーが大きすぎるとインデックスの効率が低下します。
B Tree
B-Tree は、バランスのとれたバイナリ ツリーの問題を非常にうまく解決し、クエリの効率性も確保できます。では、なぜ B とは何なのでしょうか。ツリーのこと?
まず、B ツリーがどのようなものかを見てみましょう。
B Tree は B-Tree の一種であり、各ノードのキーワードと m 次式の関係が B-Tree とは異なります。
まず、各ノードの子ノードの数と各ノードに格納できるキーワードの比率は 1:1 です。次に、データをクエリする場合、左クエリには閉区間を使用し、ブランチノードにもデータはありません。キーワードと子ノードポイントのみが保存され、データはリーフノードに格納されます。 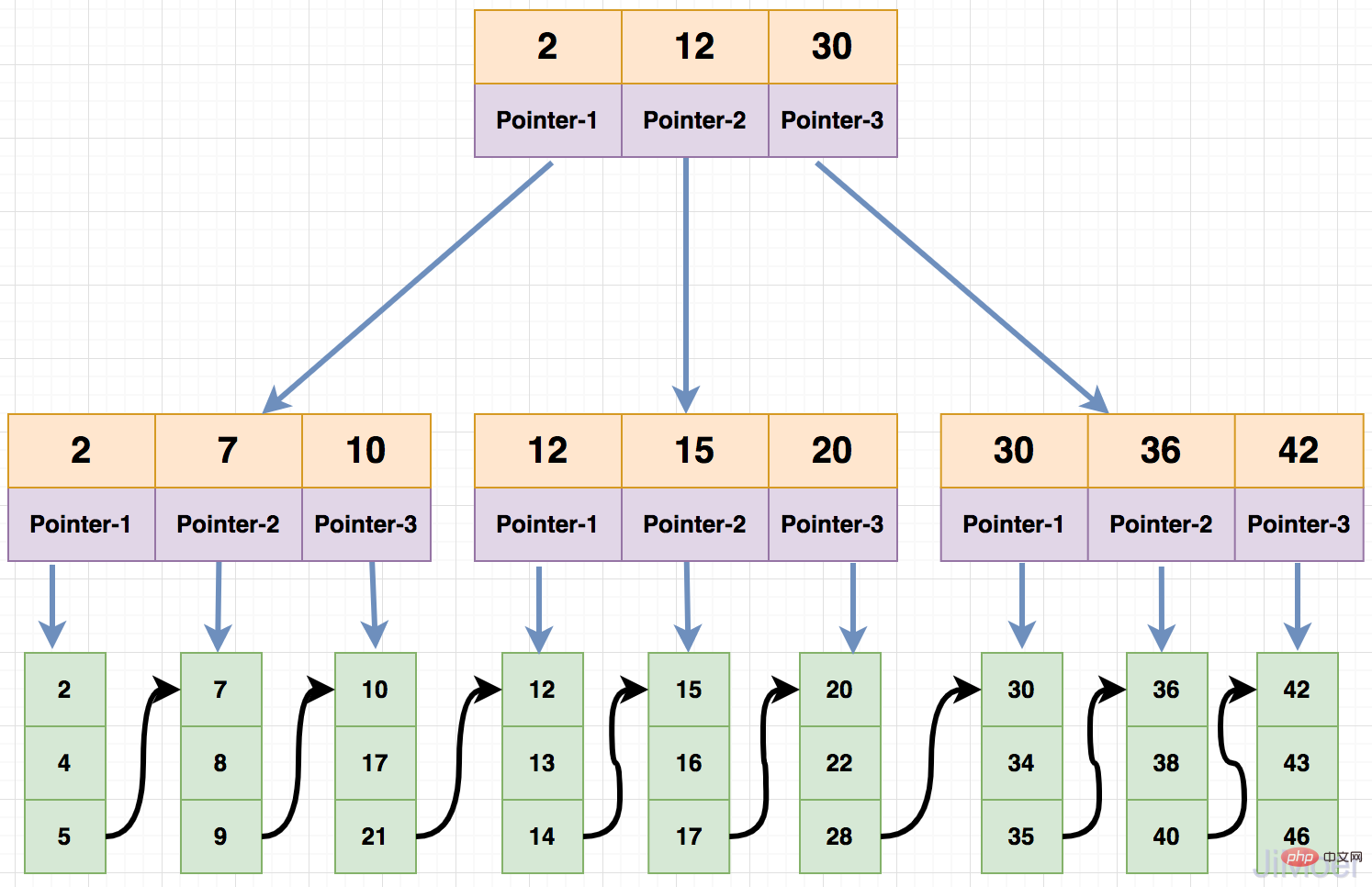
次に、B Tree でデータ クエリを実行する方法を見てみましょう。 ######例えば:###
id=2 が存在することがわかります。ノードは左側の閉じた間隔にデータを格納するため、 id はすべてルート ノードの最初の子ノードにあります;
id=2 キーワード、そして葉ノードに到達した場合、葉ノード内のデータを直接取得して返します。 次に、B ツリーと B ツリーの違いを見てみましょう。
上記のレイヤーごとの分析を経て、MySQL がデータ構造として B Tree を選択した理由を要約できます。そのインデックス、毛織物。
まず第一に、バランスバイナリツリーと比較して、B ツリーの深さは低く、ノードはより多くのキーワードを保存し、ディスク IO の数は少なく、クエリの計算効率が向上します。
B Tree には、より強力なグローバル スキャン機能があります。インデックス データに基づいてデータ テーブルをグローバルにスキャンする場合、B-Tree はツリー全体をスキャンします。レイヤーごとに移動します。 B Tree の場合、葉ノード間には逐次参照関係があるため、葉ノードを走査するだけで済みます。
B ツリーのディスク IO 読み取りおよび書き込み機能は、B ツリーの各ブランチ ノードにキーワードのみが保存されるため、より強力です。読み取りおよび書き込みの場合、16K データの 1 ページにはより多くのキーワードを保存でき、各ノードには B-Tree よりも多くのキーワードを保存できます。このように、B Tree のディスク IO は、B-Tree よりもはるかに多くのデータを読み込みます。
B ツリー データ構造には、他のデータ構造よりも強力な自然な並べ替え機能があり、並べ替えはブランチ ノードを通じて行われます。ソート用のメモリが追加され、より多くのデータを一度にロードできます。
B すべてのクエリはデータを返す前にリーフ ノードをスキャンする必要があるため、ツリーのクエリ効果はより安定しています。効果は安定しているだけで、必ずしも最適であるとは限りません。B-Tree のルート ノード データが直接クエリされた場合、B-Tree は 1 回のディスク IO だけでデータを直接返すことができますが、その効果は最適です。
上記の点を分析した後、MySQL は最終的にインデックスのデータ構造として B Tree を選択しました。
InnDB のデータ ストレージ ファイルと MyISAM のデータ ストレージ ファイルの違いは何ですか?
上記は MySQL インデックスのデータ構造をまとめたものですが、今回は 2 番目の質問について説明します。なぜなら、この質問は実際には MySQL インデックスと一定の関係があるからです。
見てみましょう。まず、サーバー MySQL がデータを保存するディレクトリを見つけます。
MySQL にログインし、MySQL コマンド ライン インターフェイスを開きます。 '�tadir%' のような変数を表示します;をクリックすると、データが保存されているディレクトリを確認できます。
MySQL がサーバーにデータを保存するディレクトリは次のとおりです:
/var/lib/mysql/
このディレクトリに入ると、すべてのデータベースのディレクトリが表示され、study_test という新しいデータベースを作成できます。
次に、ディレクトリ
/var/lib/mysql/study_test
に入ります。現在、ファイルは 1 つだけあります。このファイルは、データベースの作成時に構成された文字セットの内容を記録するために使用されます。
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt
次に、2 つの新しいテーブルを作成し、最初のテーブルのエンジン タイプとして InnoDB を選択し、2 番目のテーブルのエンジン タイプとして MyISAM を選択します。
student_innodb:
CREATE TABLE `student_innodb` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='innodb引擎表';
student_myisam:
CREATE TABLE `student_myisam` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='myISAM引擎类型表';
2 つのテーブルが作成されたら、「/var」と入力します。 /lib/mysql/study_test見てください:
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt-rw-r----- 1 mysql mysql 8650 1月 31 10:41 student_innodb.frm-rw-r----- 1 mysql mysql 114688 1月 31 10:41 student_innodb.ibd-rw-r----- 1 mysql mysql 8650 1月 31 10:58 student_myisam.frm-rw-r----- 1 mysql mysql 0 1月 31 10:58 student_myisam.MYD-rw-r----- 1 mysql mysql 1024 1月 31 10:58 student_myisam.MYI
ディレクトリ内のファイルを見ると、テーブルの作成後にさらにいくつかのファイルがあることがわかります。これは、InnoDB エンジン タイプ テーブルも示していますMyISAM エンジン タイプ テーブルとのファイルの違い。
これらの各ファイルには独自の機能があります:
MyISAM ストレージ エンジンがインデックスを保存すると、データは次のようになります。インデックス付き B ツリーは最終的に、特定のデータではなく、データが存在する物理アドレスを指します。次に、物理アドレスに従ってデータ ファイル (*.MYD) 内の特定のデータを見つけます。
次の図に示すように:
複数のインデックスがある場合、複数のインデックスは同じ物理アドレスを指します。 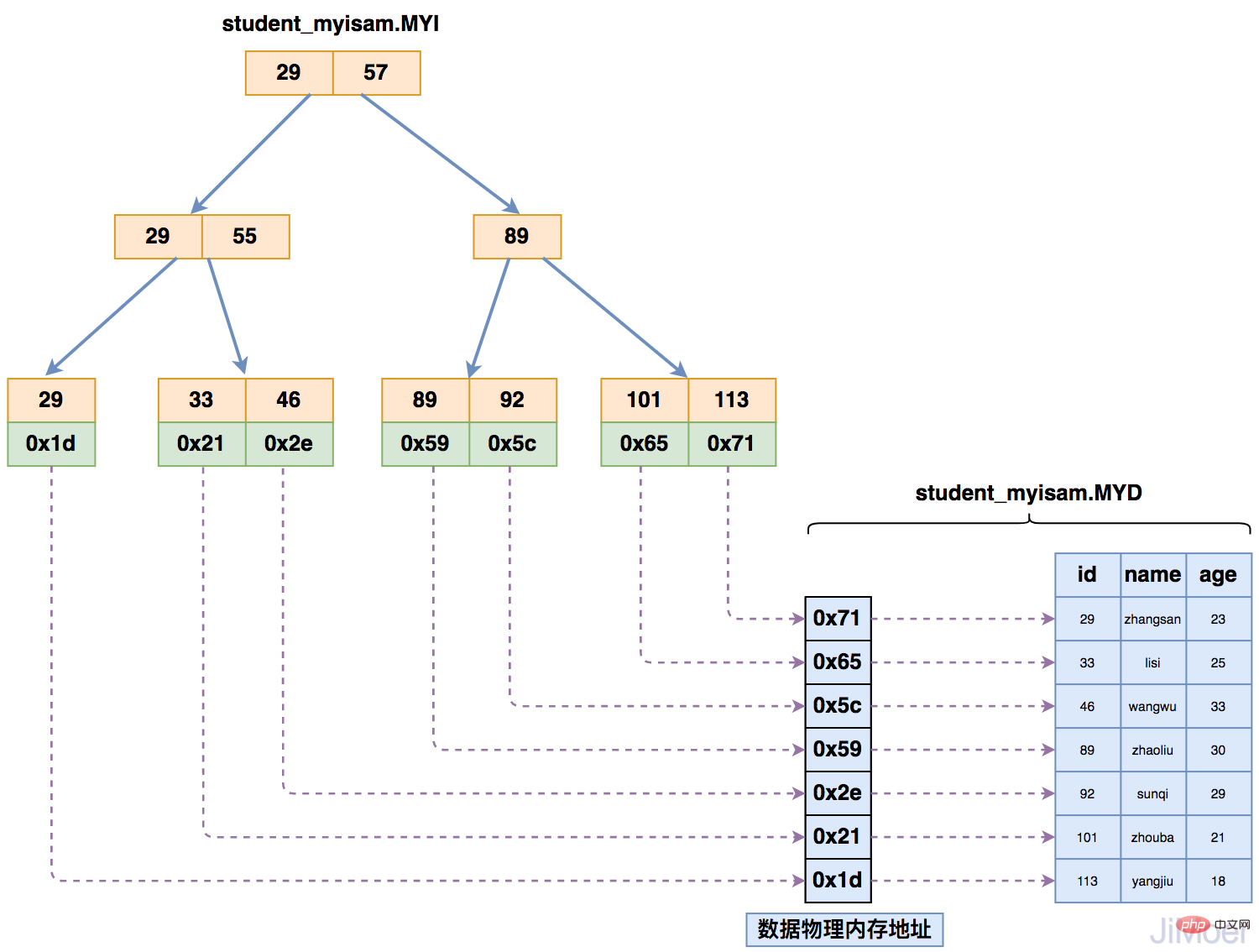 以下の図に示すように:
以下の図に示すように:
この構造を通じて、MyISAM のストレージ エンジンのインデックスがすべて同じレベルにあり、主キー インデックスと非主キー インデックスが同じであることがわかります。構造とクエリメソッドはまったく同じです。 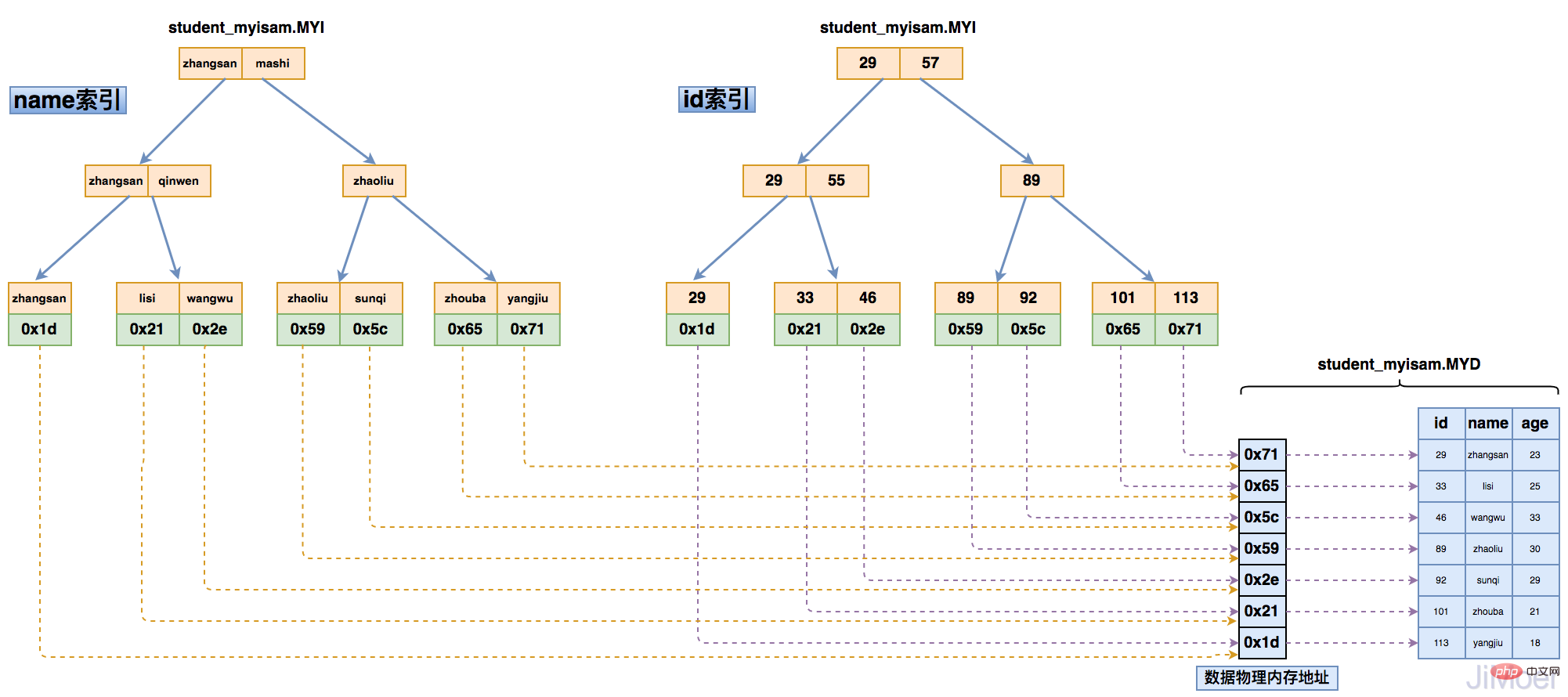
まず、InnoDB のインデックスはクラスター化インデックスと非クラスター化インデックスに分かれています。クラスター化インデックスはキーワードを保存します。データの保存では、B ツリーの各枝ノードにキーワードが保存され、葉ノードにデータが保存されます。
「クラスタリング
」は、データ行が特定の順序で 1 つずつ密集して格納されることを意味します。テーブルにデータを格納する方法は 1 つだけであるため、テーブルにはクラスター化インデックスを 1 つだけ持つことができます。通常、主キーはクラスター化インデックスとして使用されます。主キーがない場合、InnoDB は主キーとして非表示の列を生成します。デフォルトではキー。 下の図に示すように:
非クラスター化インデックス。セカンダリ インデックスとも呼ばれますが、B ツリーの各ブランチ ノード、リーフ ノードにもキーワードが保存されます。保存されたデータではなく、保存された主キーの値。セカンダリ インデックスを介してデータをクエリすると、まずデータに対応する主キーがクエリされ、次に主キーに基づいて特定のデータ行がクエリされます。 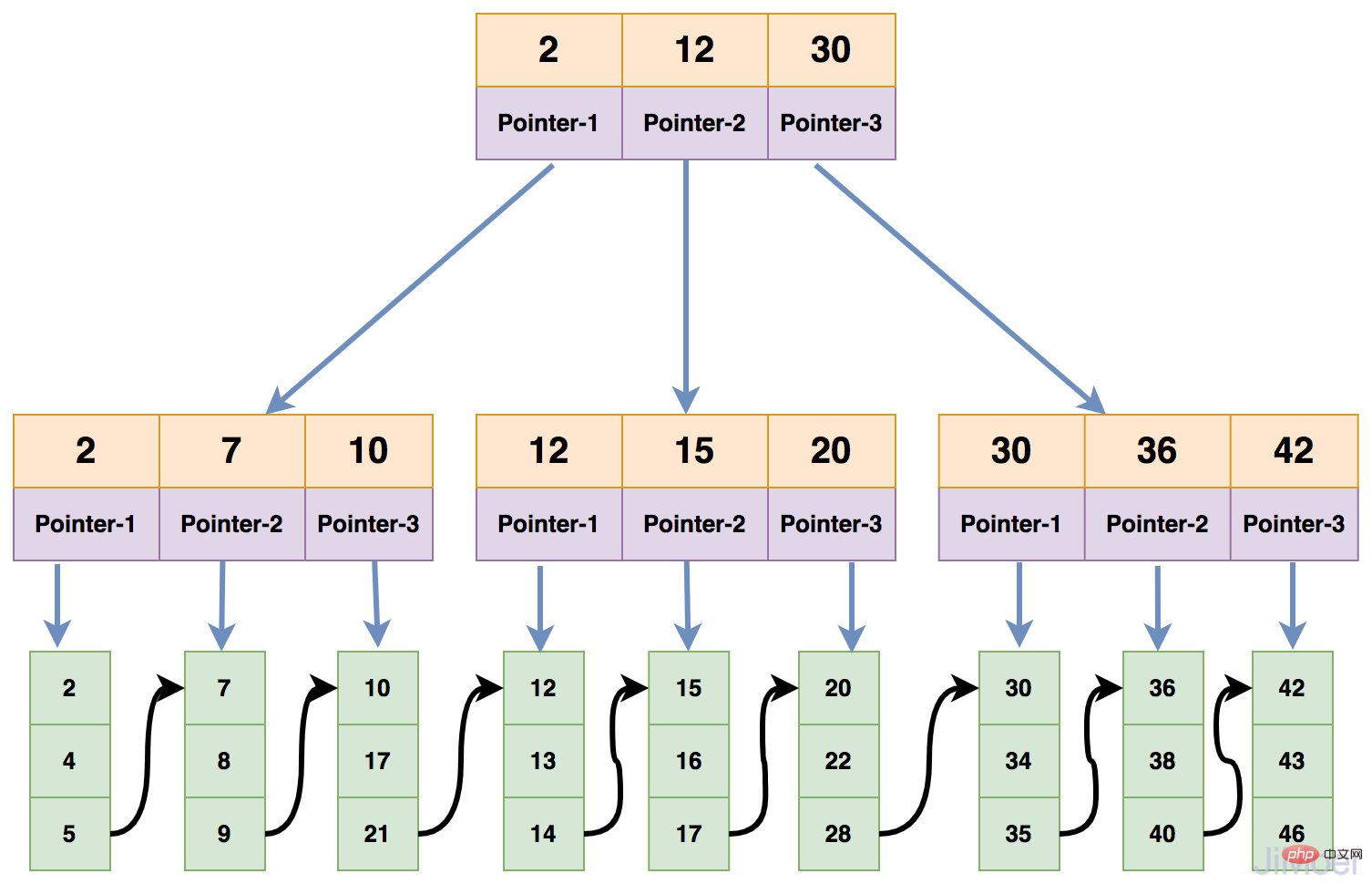
次の図に示すように:
非クラスター化インデックスの設計構造により、非クラスター化インデックスはクエリ時に 2 回のインデックス取得を実行する必要があります。利点は、データ移行が発生すると、主キー インデックスのみを更新する必要があり、非クラスター化インデックスを移動する必要がないことです。また、再設定が必要な MyISAM インデックスのような物理アドレスを保存する必要もなくなります。 - データ移行中に維持されるすべてのインデックス作成の問題。 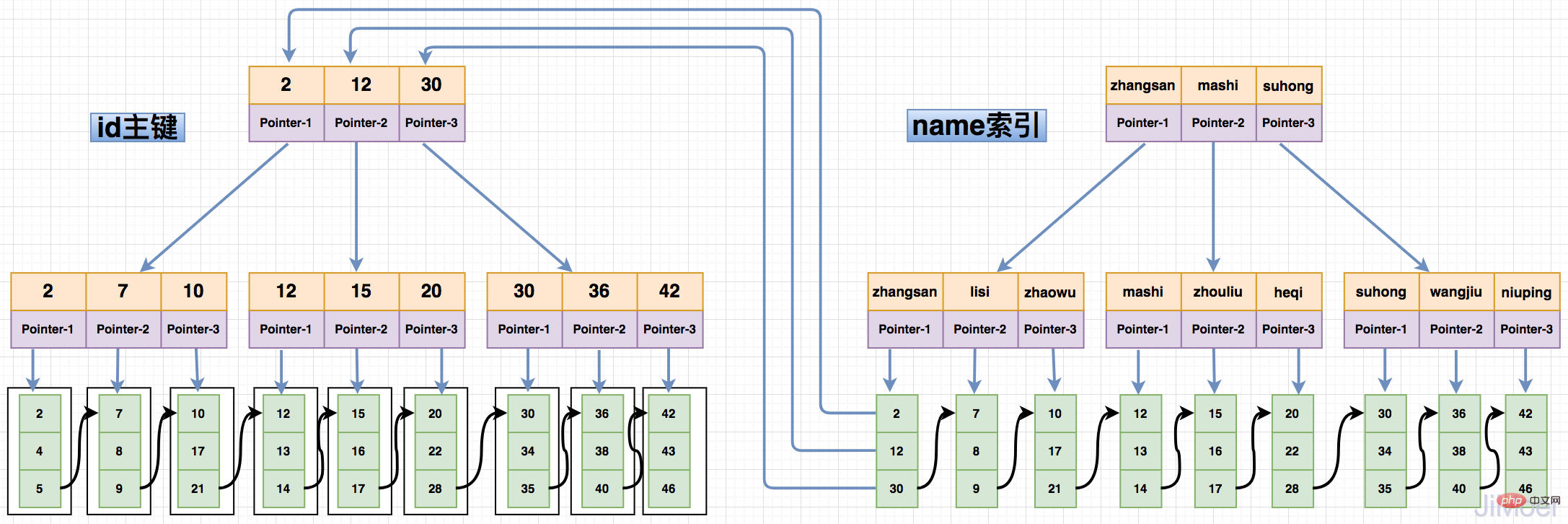
今回は、MySQL インデックスのデータ構造とファイルの格納構造についてわかりやすくまとめました。後ほど、実際の作業工程でインデックスを設計する際に、インデックスのデータ構造を理解することで、実際に SQL を書くときにどのような状況にインデックスが付けられ、どのような状況にインデックスが付けられないかを考慮することもできます。
MySQL はインデックスのデータ構造として B ツリーを使用します。これは、B ツリーの深さが浅く、ノードが多くのキーワードを保存し、ディスク IO の数が少ないため、より高いクエリ効率が保証されます。 。関連する無料学習の推奨事項:
以上がInnoDB データ ストレージ ファイルは MyISAM とは異なりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



