



# 関連する学習の推奨事項:##これは
の 2 番目の記事では、パンダの最も重要なデータ構造である DataFrame について話しましょう。 前回の記事では、Series の使い方を紹介し、Series が一次元配列に相当することにも触れましたが、pandas には便利で使いやすい API が数多くカプセル化されています。 DataFrame は、
Series で構成される dictとして単純に理解でき、データが 2 次元のテーブルに結合されます。また、テーブルレベルのデータ処理とバッチデータ処理のための多くのインターフェイスも提供するため、データ処理の難しさが大幅に軽減されます。
を使用すると、対応する行と列を簡単に取得できます。これにより、データ処理用のデータを見つける難しさが大幅に軽減されます。 まず、最も単純な DataFrame の作成方法から始めましょう。
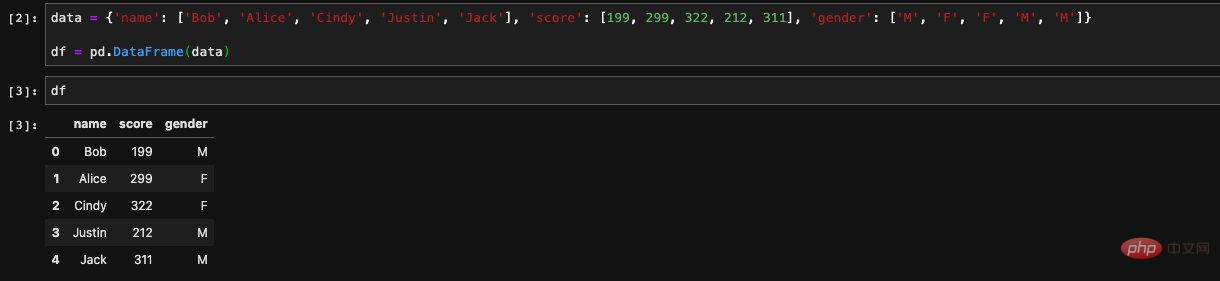 キーが次のような辞書を作成します。列名、値はリストです。この dict を DataFrame コンストラクターに渡すと、
キーが次のような辞書を作成します。列名、値はリストです。この dict を DataFrame コンストラクターに渡すと、jupyter で出力すると、DataFrame の内容が表形式で自動的に表示されます。
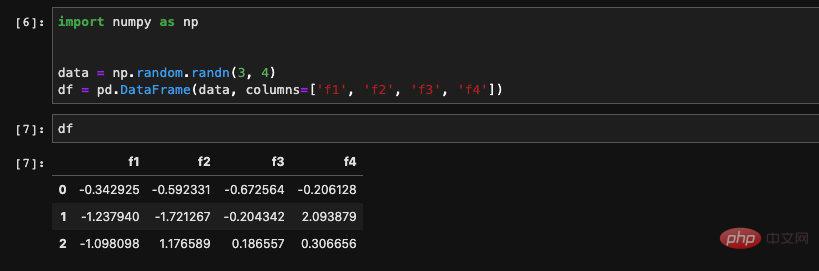
pandas のもう 1 つの非常に強力な機能は、次のことです。 さまざまな形式のファイルからデータを読み取り、一般的に使用される Excel、CSV、さらにはデータベースなどの DataFrame を作成します。
Excel、csv、json などの構造化データの場合、pandas は特別な API を提供します。対応する API を見つけて使用できます。
特別な形式であっても問題ありませんが、さまざまなテキスト ファイルからデータを読み取り、区切り文字 やその他のパラメータを渡すことで作成が完了する read_table を使用します。たとえば、PCA の次元削減効果を検証した前回の記事では、.data 形式のファイルからデータを読み取りました。このファイルの列間の区切り文字はスペースであり、カンマや csv の表文字ではありません。 sep パラメータ から を渡し、区切り文字を指定してデータの読み取りを完了します。

このヘッダー パラメーターは、ファイルのどの行がデータの列名として使用されるかを示します。デフォルトの header=0 は、最初の行が列名として使用されます。データ内に列名が存在しない場合は、header=None を指定する必要があります。指定しないと問題が発生します。マルチレベルの列名を使用する必要があることはほとんどないため、一般に最も一般的に使用される方法は、デフォルト値を取得するか、デフォルト値を None に設定することです。
DataFrame を作成するこれらすべての メソッドの中で、最も一般的に使用されるのは最後のメソッド (ファイルからの読み取り) です。というのも、Kaggle で機械学習をしたり、コンペに参加したりするときは、データがあらかじめ用意されており、ファイルの形で渡されることが多く、自分でデータを作成する必要があるケースはほとんどありません。実際の作業シナリオの場合、データはファイルに保存されませんが、ソースが存在し、通常はいくつかのビッグ データ プラットフォームに保存され、モデルはこれらのプラットフォームからトレーニング データを取得します。
したがって、一般に、DataFrame を作成する他の方法を使用することはほとんどなく、ファイルから読み取る方法をある程度理解し、習得することに重点を置いています。
知っておくべき常識内容と言えるからです。
最初の数個のデータを表示するメソッドは head と呼ばれ、パラメータを受け取り、それを指定することで先頭から指定した数のデータを表示できます。
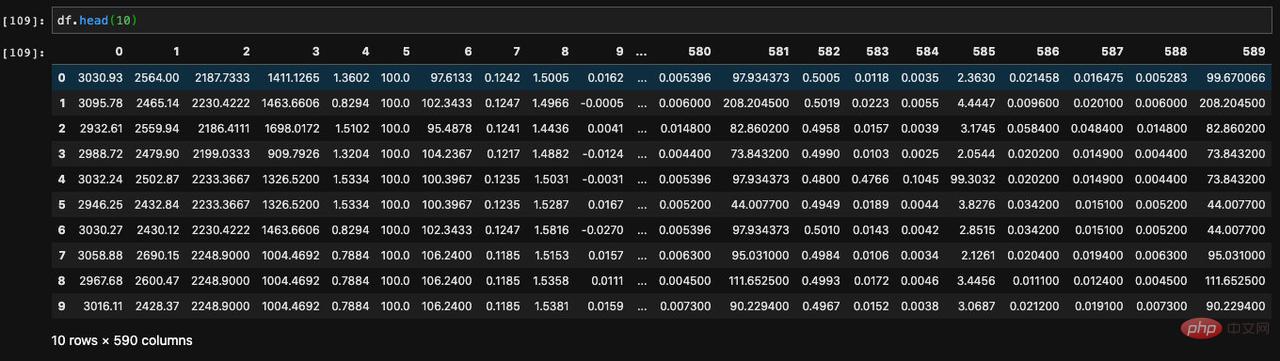
tail## と呼びます#。これにより、DataFrame 内の最後に指定した数のデータを表示できます。

DataFrame で指定された列を取得するには 2 つの方法があります。
列名を追加するまたは find 要素を dict でクエリすることができます:
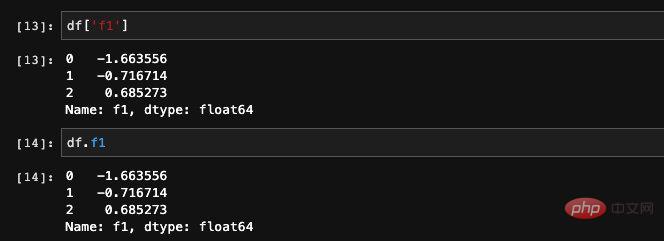 同時に複数の列を読み取ることもできます
同時に複数の列を読み取ることもできます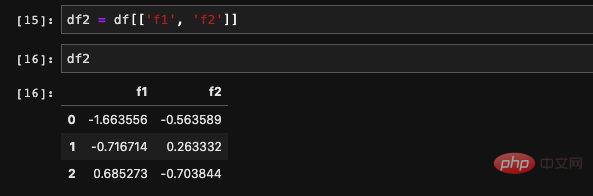
del を使用して不要な列を削除できます:
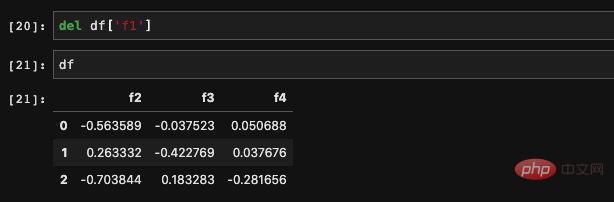
dict 割り当てと同じように、DataFrame に値を直接割り当てることができます:
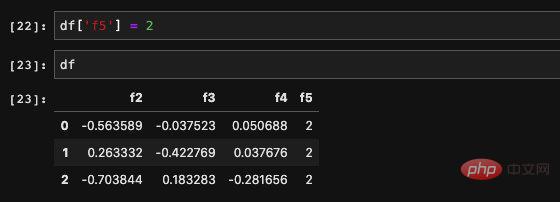
配列も可能です:
.values を使用して、DataFrame に対応する numpy 配列を取得できます。

DataFrame の各列なので、別の型 を持ち、numpy 配列に変換された後、すべてのデータは同じ型を共有します。その後、パンダはすべての列に共通の型を見つけます。そのため、オブジェクト型が取得されることがよくあります。したがって、.values を使用する前に型をチェックして、型によるエラーが発生しないことを確認することをお勧めします。
専門組織は統計を作成しています。アルゴリズム エンジニアの場合、時間の約 70% がデータ処理に費やされます。実際にモデルの作成やパラメータの調整に費やされる時間は 20% 未満である可能性があり、データ処理の必要性と重要性がわかります。 Python の分野において、pandas はデータ処理に最適なメスでありツールボックスですので、ぜひ皆さんにも使いこなしていただきたいと思います。
プログラミングについてさらに詳しく知りたい場合は、php training 列に注目してください。
以上がデータ処理にパンダを使用する DataFrameの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



