



まえがき
現在、Zhihu ではビデオのアップロードが許可されていますが、ビデオをダウンロードすることはできません。とても腹が立ちます。と思ったので、必死で調べて、しばらくしてから、ビデオを簡単にダウンロードして保存できるようにするためのコードを入力しました。
次に、なぜ猫はヘビをまったく恐れないのでしょうか?例として回答し、ダウンロード プロセス全体を共有します。
関連する学習に関する推奨事項: Python ビデオ チュートリアル
デバッグしてみる
F12 を開くで、以下に示すようにカーソルを見つけて、ビデオにカーソルを移動します。以下に示すように:
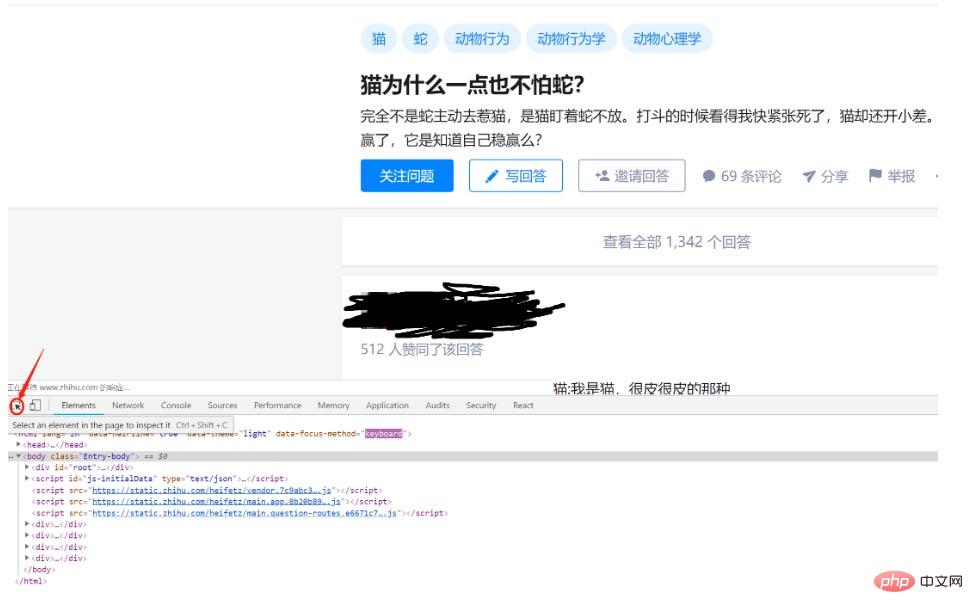
ねえ、これは何ですか?謎のリンクが視界に現れました: https://www.zhihu.com/video/xxxxx。このリンクをブラウザにコピーして開きます:
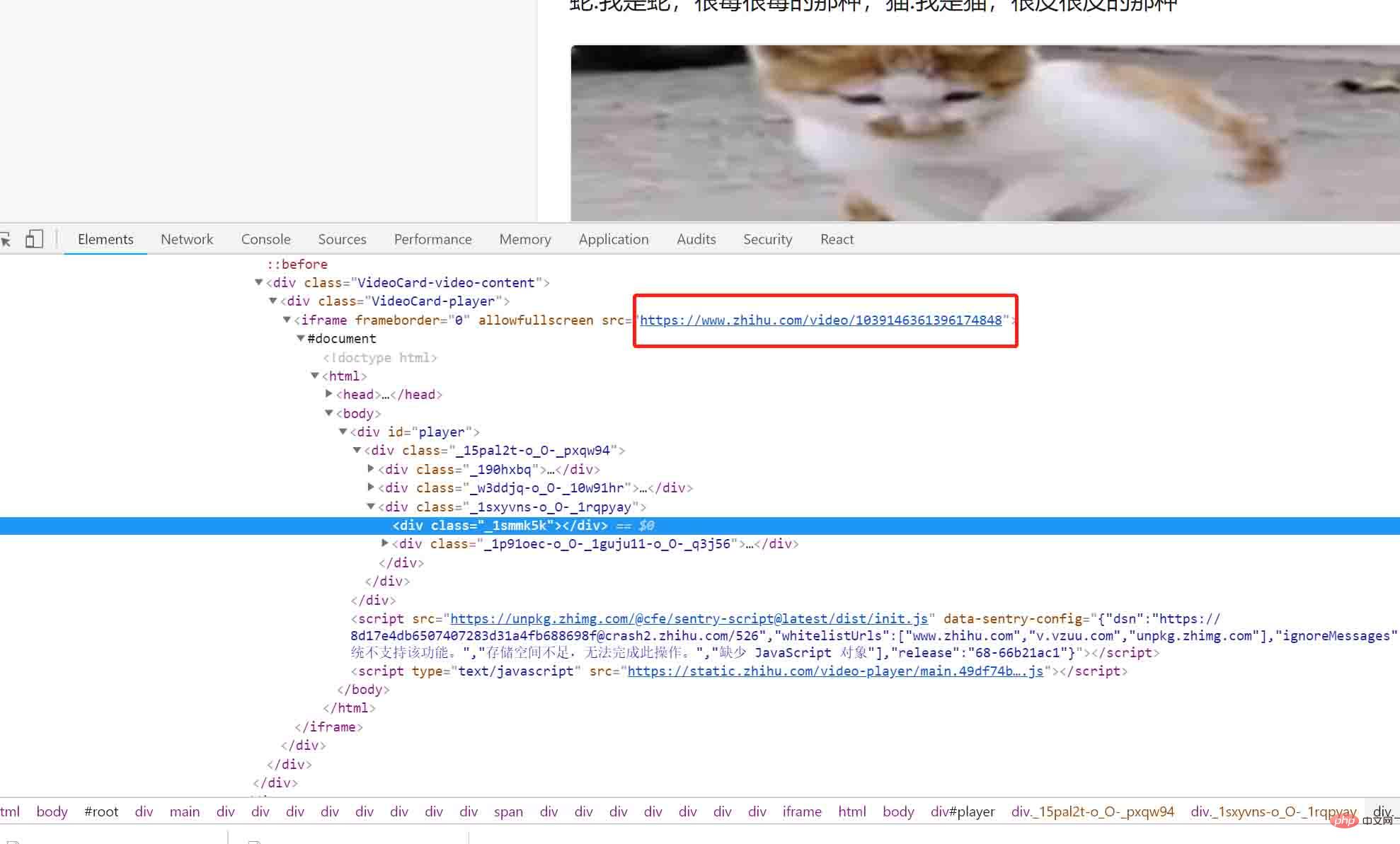
これが私たちが探しているビデオのようです。心配しないで、Web ページのリクエストを見てみましょう。すると、非常に興味深いリクエストが見つかります (ここが焦点です):
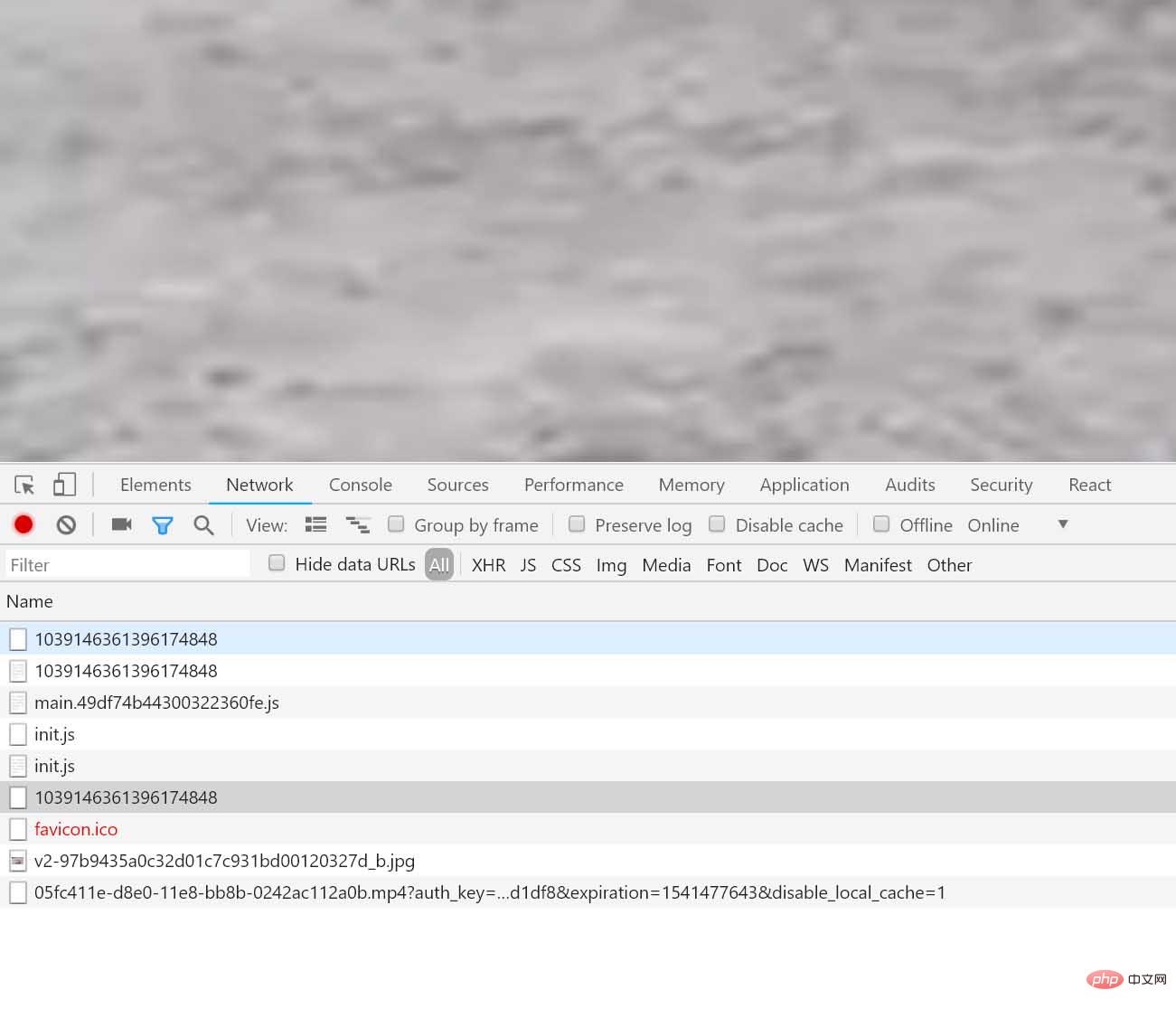
データを実際に見てみましょう:
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-987c2c504d14ab1165ce2ed47759d927&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-8b8024a22a62f097ca31b8b06b7233a1&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-5948c2562d817218c9a9fc41abad1df8&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-97b9435a0c32d01c7c931bd00120327d_b.jpg",
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}はい、ダウンロードしたいビデオはここにあります。ld は共通定義を表し、sd は標準を表します。 Definition、HD は高解像度を表します。対応するリンクをブラウザでもう一度開き、右クリックして保存してビデオをダウンロードします。 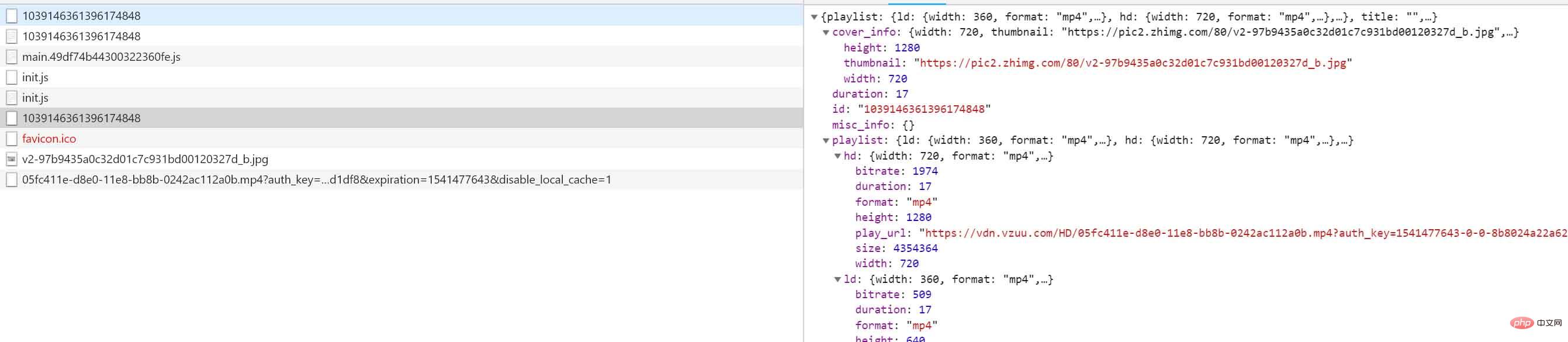
コード
全体のプロセスがどのようなものかを知っていれば、次のコーディングのプロセスは簡単になります。ここではあまり説明しません。コード:# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())関連する学習に関する推奨事項:
Python ビデオ チュートリアル以上がPython を使用して、Zhihu で指定された回答を含むビデオをキャプチャする方法を学びますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



