


近隣アルゴリズム、または K 最近傍 (kNN、k-NearestNeighbor) 分類アルゴリズムは、データ マイニング分類テクノロジの最も単純な方法の 1 つです。いわゆる K 最近傍とは、k 個の最近傍を意味します。これは、各サンプルがその k 個の最近傍によって表現できることを意味します。
kNN アルゴリズムの中心的な考え方は、特徴空間内のサンプルの k 個の最近接サンプルのほとんどが特定のカテゴリに属している場合、サンプルもこのカテゴリに属し、このカテゴリ内のサンプルの特性を持つということです。この方法では、分類の決定を行う際に、最も近い 1 つまたは複数のサンプルのカテゴリに基づいて、分類されるサンプルのカテゴリのみが決定されます。 kNN 法は、カテゴリの決定を行う際に、非常に少数の隣接するサンプルにのみ関連します。 kNN 法は、クラス領域を識別してカテゴリを決定する方法ではなく、主に限られた周囲のサンプルに依存するため、サンプルセットが多数の交差または重複で分割される場合、他の方法よりも効率的です。フィットのクラスドメイン。
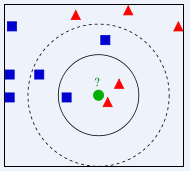
上の図で、緑の丸はどのクラスに割り当てられるべきですか? 赤い三角形ですか?それとも青い四角ですか? K=3 の場合、赤い三角形の割合は 2/3 であるため、緑の円には赤い三角形のクラスが割り当てられます。 K=5 の場合、青い正方形の割合は 3/5 であるため、緑の円が割り当てられます。青い正方形タイプのクラスが割り当てられます。
K 最近傍 (KNN) 分類アルゴリズムは理論的に成熟した手法であり、最も単純な機械学習アルゴリズムの 1 つです。この方法の考え方は、サンプルが特徴空間内の k 個の最も類似した (つまり、特徴空間内で最も近い) サンプルの中の特定のカテゴリに属する場合、サンプルもこのカテゴリに属するということです。 KNN アルゴリズムでは、選択された近傍オブジェクトはすべて正しく分類されたオブジェクトです。この方法は、分類の意思決定において、最も近い 1 つまたは複数のサンプルのカテゴリに基づいて、分類されるサンプルのカテゴリを決定するだけです。 KNN 法も原理的には極限定理に依存しますが、カテゴリーの決定を行う際に関係するのは、非常に少数の隣接するサンプルのみです。 KNN 法は、クラス領域を識別してカテゴリを決定する方法ではなく、主に周囲の限られたサンプルに依存するため、多数の交差または重複でサンプルセットを分割する場合、KNN 方法は他の方法よりも効率的です。フィットのクラスドメイン。
KNN アルゴリズムは分類だけでなく回帰にも使用できます。サンプルの k 個の最近傍を見つけて、これらの近傍の属性の平均をサンプルに割り当てることによって、サンプルの属性を取得できます。より有用な方法は、サンプル上の異なる距離にある近隣の影響に異なる重みを与えることです。たとえば、重みは距離に反比例します。
kNN アルゴリズムを使用して Douban 映画ユーザーの性別を予測します
概要
この記事では、性別が異なれば好む映画の種類も異なると考え、この実験を実施しました。 274 人のアクティブな Douban ユーザーが最近視聴した 100 本の映画を使用して、そのタイプに関する統計を作成しました。得られた 37 種類の映画を属性特徴として使用し、ユーザーの性別をサンプル セットを構築するためのラベルとして使用しました。 kNN アルゴリズムを使用して、サンプルの 90% をトレーニング サンプルとして、10% をテスト サンプルとして使用して Douban ムービー ユーザーの性別分類器を構築すると、精度は 81.48% に達します。
実験データ
この実験で使用されたデータは、Douban ユーザーがマークした映画であり、274 人の Douban ユーザーが最近視聴した 100 本の映画が選択されました。ユーザーごとの映画タイプの統計。今回の実験で使用したデータには映画の種類が合計 37 種類あるので、この 37 種類をユーザーの属性特徴量とし、各特徴量の値がユーザーの映画 100 本のうちその種類の映画の数となります。ユーザーは性別によってラベル付けされます。Douban にはユーザーの性別情報がないため、すべて手動でラベル付けされます。
データ形式は次のとおりです:
X1,1,X1,2,X1,3,X1,4……X1,36,X1,37,Y1 X2,1,X2,2,X2,3,X2,4……X2,36,X2,37,Y2 ………… X274,1,X274,2,X274,3,X274,4……X274,36,X274,37,Y274
例:
0,0,0,3,1,34,5,0,0,0,11,31,0,0,38,40,0,0,15,8,3,9,14,2,3,0,4,1,1,15,0,0,1,13,0,0,1,1 0,1,0,2,2,24,8,0,0,0,10,37,0,0,44,34,0,0,3,0,4,10,15,5,3,0,0,7,2,13,0,0,2,12,0,0,0,0
像这样的数据一共有274行,表示274个样本。每一个的前37个数据是该样本的37个特征值,最后一个数据为标签,即性别:0表示男性,1表示女性。
在此次试验中取样本的前10%作为测试样本,其余作为训练样本。
首先对所有数据归一化。对矩阵中的每一列求取最大值(max_j)、最小值(min_j),对矩阵中的数据X_j,
X_j=(X_j-min_j)/(max_j-min_j) 。
然后对于每一条测试样本,计算其与所有训练样本的欧氏距离。测试样本i与训练样本j之间的距离为:
distance_i_j=sqrt((Xi,1-Xj,1)^2+(Xi,2-Xj,2)^2+……+(Xi,37-Xj,37)^2) ,
对样本i的所有距离从小到大排序,在前k个中选择出现次数最多的标签,即为样本i的预测值。
实验结果
首先选择一个合适的k值。 对于k=1,3,5,7,均使用同一个测试样本和训练样本,测试其正确率,结果如下表所示。
选取不同k值的正确率表
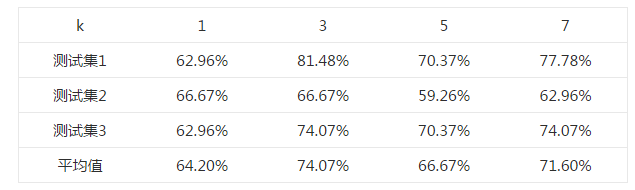
由上述结果可知,在k=3时,测试的平均正确率最高,为74.07%,最高可以达到81.48%。
上述不同的测试集均来自同一样本集中,为随机选取所得。
Python代码
这段代码并非原创,来自《机器学习实战》(Peter Harrington,2013),并有所改动。
#coding:utf-8
from numpy import *
import operator
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,37)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split(',')
returnMat[index,:] = listFromLine[0:37]
classLabelVector.append(int(listFromLine[-1]))
index += 1
fr.close()
return returnMat,classLabelVector
def genderClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('doubanMovieDataSet.txt') #load data setfrom file
normMat,ranges,minVals=autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
testMat=normMat[0:numTestVecs,:]
trainMat=normMat[numTestVecs:m,:]
trainLabels=datingLabels[numTestVecs:m]
k=3
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(testMat[i,:],trainMat,trainLabels,k)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print "Total errors:%d" %errorCount
print "The total accuracy rate is %f" %(1.0-errorCount/float(numTestVecs))
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



