


この記事の主な内容は、PHP の複数のプロセスを使用して、順序付けされた Redis のコレクションと連携して、大きなファイルの重複排除を実現することです。興味のある友人は、それについて学ぶことができます。
1.たとえば、大きなファイルの場合、私のファイルは
-rw-r--r-- 1 ubuntu ubuntu 9.1G Mar 1 17:53 2018-12 -awk -uniq.txt
2. 分割コマンドを使用して 10 個の小さなファイルに分割します
split -b 1000m 2018-12-awk-uniq.txt -b バイトに従って切り取ります。サポートされているユニット m と k
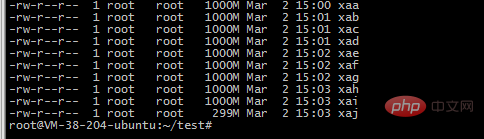
3. 10 個の php プロセスを使用してファイルを読み取り、redis の順序付きセット構造に挿入します。繰り返しのものは挿入できません。重複排除の役割を果たすことができます
<?php
$file=$argv[1];
//守护进程
umask(0); //把文件掩码清0
if (pcntl_fork() != 0){ //是父进程,父进程退出
exit();
}
posix_setsid();//设置新会话组长,脱离终端
if (pcntl_fork() != 0){ //是第一子进程,结束第一子进程
exit();
}
$start=memory_get_usage();
$redis=new Redis();
$redis->connect('127.0.0.1', 6379);
$handle = fopen("./{$file}", 'rb');
while (feof($handle)===false) {
$line=fgets($handle);
$email=str_replace("\n","",$line);
$redis->zAdd('emails', 1, $email);
}
4.取得したデータを redis で表示します
zcard email 要素の数を取得します
 100000 から始まり 100100 で終わるなど、特定の範囲の要素を取得します
100000 から始まり 100100 で終わるなど、特定の範囲の要素を取得します
zrange email 100000 100100 WITHSCORES
PHP をより効率的に学習したい場合は、PHP 中国語 Web サイトの
PHP ビデオ チュートリアル以上がPHP と Redis を組み合わせて大規模ファイルの重複排除を実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



