


この記事では、Python クローラーの http プロトコルと https プロトコルについて詳しく説明 (写真とテキスト) しています。一定の参考価値があります。困っている友人は参考にしてください。お役に立てれば幸いです。
1.HTTP プロトコル
1.公式概念:
HTTP プロトコルは、Hyper Text Transfer Protocol (ハイパー テキスト トランスファー プロトコル) の略称であり、からデータを転送するワールド ワイド ウェブ (WWW: World Wide Web) サーバーがハイパーテキストをローカル ブラウザに送信するために使用するトランスポート プロトコル。 (子供靴にはこの概念が見えませんが、どうすることもできません。結局のところ、これは HTTP の権威ある公式の概念説明です。完全に理解したい場合は、目を下側に移動してください。 ..)
2. 言語概念:
HTTP プロトコルは、サーバー (Server) とクライアント (Client) 間のデータ対話 (データの相互送信) の形式です。サーバーとクライアントを擬人化すると、このプロトコルは、2 つの兄弟サーバーとクライアント間の指定された対話型通信方法になります。
3. HTTP の動作原理:
HTTP プロトコルはクライアント/サーバー アーキテクチャで動作します。ブラウザは HTTP クライアントとして、URL を介してすべてのリクエストを HTTP サーバー、つまり WEB サーバーに送信します。 Webサーバーは、受信したリクエストに基づいて応答情報をクライアントに送信します。 #####################################
##4. HTTP に関する 4 つの注意点:##- HTTP では、あらゆる種類のデータ オブジェクトの送信が可能です。転送されるタイプは Content-Type によってマークされます。 #-- HTTP はコネクションレスです: コネクションレスとは、各接続が 1 つのリクエストのみを処理するように制限することを意味します。サーバーはクライアントの要求を処理し、クライアントの応答を受信した後、接続を切断します。この方法により、送信時間が節約されます。 #-- HTTP はメディアに依存しません。これは、クライアントとサーバーがデータ コンテンツの処理方法を知っている限り、あらゆるタイプのデータを HTTP 経由で送信できることを意味します。クライアントとサーバーは、使用する適切な MIME タイプのコンテンツ タイプを指定します。 #-- HTTP はステートレスです: HTTP プロトコルはステートレス プロトコルです。ステートレスとは、プロトコルにトランザクション処理のためのメモリ機能がないことを意味します。ステータスがないということは、後続の処理で以前の情報が必要な場合にその情報を再送信する必要があることを意味し、その結果、接続ごとに転送されるデータ量が増加する可能性があります。一方、事前の情報が必要ない場合、サーバーはより速く応答します。 5. HTTP URL: 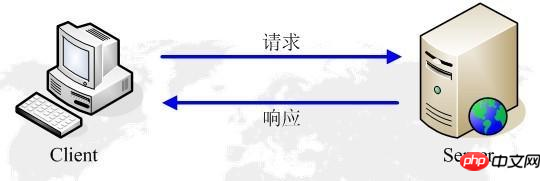 HTTP は、Uniform Resource Identifier (URI) を使用してデータを送信し、接続を確立します。 URL は、リソースを見つけるのに十分な情報が含まれる特別なタイプの URI です。URL、正式名は、UniformResourceLocator で、中国語ではユニフォーム リソース ロケーターと呼ばれ、インターネット上の特定のリソースを識別するために使用されます。の住所。通常の URL のコンポーネントを紹介する例として、次の URL を取り上げます。 http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name 上記からわかるように、 URL 、完全な URL には次の部分が含まれます。 -プロトコル部分: URL のプロトコル部分は「http:」です。これは、Web ページが HTTP プロトコルを使用することを意味します。インターネットでは、HTTP、FTP などのさまざまなプロトコルが使用されます。この例では、HTTP プロトコルが使用されます。 「HTTP」の後の「//」は区切り文字です。 - ドメイン名部分: URL のドメイン名部分は「www.aspxfans.com」です。 URL では、
HTTP は、Uniform Resource Identifier (URI) を使用してデータを送信し、接続を確立します。 URL は、リソースを見つけるのに十分な情報が含まれる特別なタイプの URI です。URL、正式名は、UniformResourceLocator で、中国語ではユニフォーム リソース ロケーターと呼ばれ、インターネット上の特定のリソースを識別するために使用されます。の住所。通常の URL のコンポーネントを紹介する例として、次の URL を取り上げます。 http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name 上記からわかるように、 URL 、完全な URL には次の部分が含まれます。 -プロトコル部分: URL のプロトコル部分は「http:」です。これは、Web ページが HTTP プロトコルを使用することを意味します。インターネットでは、HTTP、FTP などのさまざまなプロトコルが使用されます。この例では、HTTP プロトコルが使用されます。 「HTTP」の後の「//」は区切り文字です。 - ドメイン名部分: URL のドメイン名部分は「www.aspxfans.com」です。 URL では、
- ポート部分を使用して IP アドレスをドメイン名として使用することもできます。ドメイン名の後にはポートがあり、ドメイン名とポートの間の区切り文字として「:」が使用されます。 。ポートは URL の必須部分ではありません。ポート部分が省略された場合、デフォルトのポートが使用されます。
#- 仮想ディレクトリ部分: ドメイン名の後の最初の「/」から最後の「」まで/"、仮想ディレクトリ部分です。仮想ディレクトリも URL の必須部分ではありません。この例の仮想ディレクトリは「/news/」です。 ファイル名部分:ドメイン名の後の最後の「/」から「?」で終わる部分がファイル名部分です。 「?」がない場合は、ドメイン名の後の最後の「/」から始まり、ファイル部分である「#」で終わります。「?」と「#」がない場合は、最後のドメイン名から始まります。ドメイン名の後ろに「/」が付き、ファイル名で終わります。この例のファイル名は「index.asp」です。ファイル名部分は URL の必須部分ではありませんが、この部分を省略した場合はデフォルトのファイル名になります - アンカー部分:「#」から最後までがアンカー部分です。この場合のアンカー部分は「名前」です。アンカー部分は URL の必須部分でもありません。-パラメータ部分: 「?」から「#」までの部分はパラメータ部分であり、検索部分およびクエリ部分とも呼ばれます。この例のパラメータ部分は「boardID=5&ID=24618&page=1」です。パラメータには複数のパラメータを使用でき、パラメータ間の区切り文字として「&」が使用されます。 6. HTTP リクエスト: クライアントからサーバーに送信されるリクエスト メッセージには、次のコンポーネントが含まれます:メッセージ ヘッダー: リクエスト ヘッダーと呼ばれることが多く、リクエスト ヘッダーにはリクエストの主な説明 (自己紹介) が格納されます。サーバーはそれに応じてクライアントの情報を取得します。
一般的なリクエスト ヘッダー:
accept: ブラウザは、このヘッダーを通じてサーバーに、サポートするデータ型を伝えます。
Accept-Charset: ブラウザは、このヘッダーを通じてサーバーに伝えます。サポートする文字セット
Accept-Encoding: ブラウザは、このヘッダーを通じてサーバーに、サポートされている圧縮形式を伝えます。
Accept-Language: ブラウザは、このヘッダーを通じてサーバーに、そのロケールを伝えます。
Host: ブラウザーこのヘッダーを通じて、どのホストにアクセスしたいかをサーバーに伝えます。
If-Modified-Since: ブラウザーは、このヘッダーを通じてサーバーにデータをキャッシュする時間を伝えます。
Referer: ブラウザーは、このヘッダーを通じてサーバーに、クライアントはどのページから来たのか? アンチリーチング
接続: ブラウザーは、このヘッダーを通じて、リクエストの完了後にリンクを切断するか維持するかをサーバーに伝えます
X-Requested-With: XMLHttpRequest は、ajax を介したアクセスを表します
User-Agent: リクエストキャリアの ID
#メッセージボディ: 多くの場合リクエストボディと呼ばれ、リクエストボディには送信されるデータ情報が格納されます。 /サーバーに送信されます。
7.HTTP 応答:
サーバーは HTTP 応答をクライアントに返します。応答メッセージには次のコンポーネントが含まれます:

ステータス コード: このリクエストの処理結果を「明確かつ明確な」言語でクライアントに伝えます。
HTTP 応答ステータス コードは 5 つのセグメントで構成されます:
1xx メッセージ。通常、リクエストが受信され処理中であることをクライアントに伝えます。心配しないでください...
2xx 処理が成功しました。これは通常、リクエストが受信され、要求が理解されました、リクエストが受け入れられ、処理が完了したことを意味します。
3xx 他の場所にリダイレクトします。これにより、クライアントはプロセス全体を完了するために別のリクエストを行うことができます。
4xx 存在しないリソースを要求した場合、クライアントに権限がない場合、アクセスが禁止されている場合など、処理中にエラーが発生した場合の責任はクライアントにあります。
5xx サーバーが例外をスローした場合、ルーティングエラーが発生した場合、HTTP バージョンがサポートされていない場合など、処理中にエラーが発生した場合はサーバーの責任となります。
対応するヘッダー: 応答の詳細表示
共通の対応するヘッダー情報:
場所: サーバーはこのヘッダーを使用してブラウザーにジャンプ先を指示します
サーバー: サーバーこのヘッダーを使用してブラウザにサーバー モデルを伝えます
Content-Encoding: サーバーはこのヘッダーを使用してブラウザにデータの圧縮形式を伝えます
Content-Length: サーバーはこのヘッダーを使用してブラウザに長さを伝えます送り返されるデータの内容
Content-Language: サーバーはこのヘッダーを使用してブラウザに言語環境を伝えます
Content-Type: サーバーはこのヘッダーを使用してブラウザに送り返されるデータのタイプを伝えます
Refresh : サーバーはこのヘッダーを使用してブラウザーにリフレッシュのタイミングを伝えます
Content-Disposition: サーバーはこのヘッダーを使用してブラウザーにデータをダウンロードするように伝えます
Transfer-Encoding: サーバーはこのヘッダーを使用してブラウザーに次のことを伝えますデータはチャンクで返送されます
有効期限: - 1 ブラウザをキャッシュしないように制御します
Cache-Control: no-cache
Pragma: no-cache
対応する本体: 指定されたデータクライアントが指定した要求情報に従ってクライアントに送信されます。
2.HTTPS プロトコル
1.公式概念:
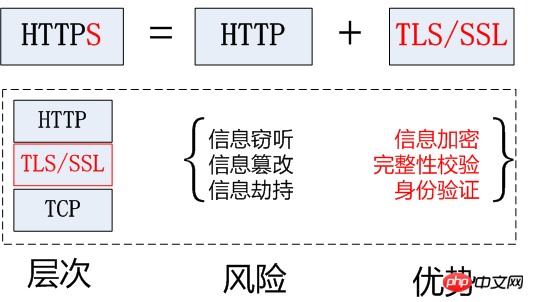
HTTPS (Secure Hypertext Transfer Protocol) 安全なハイパーテキスト転送HTTPS は HTTP 上に SSL 暗号化層を確立し、データは暗号化され、HTTP プロトコルの安全なバージョンです。
2. 各言語の概念:
HTTP プロトコルの暗号化された安全なバージョン。
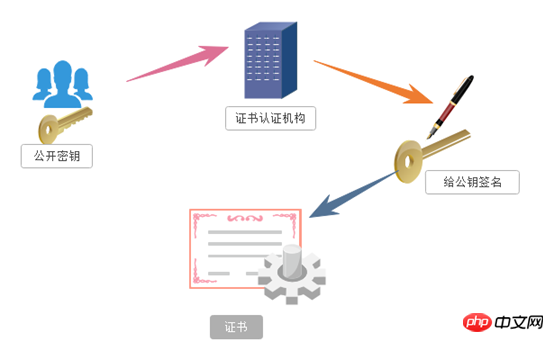
「非対称暗号化」を使用する場合、2 つのロックがあり、1 つは「秘密キー」と呼ばれ、もう 1 つは「公開キー」と呼ばれます。非オブジェクト暗号化暗号化方式を使用する場合、サーバーは最初に次に従ってクライアントに通知します。提供された公開鍵は暗号化されます。クライアントが公開鍵に従って暗号化した後、サーバーは情報を受信し、独自の秘密鍵を使用して復号化します。この利点は、復号化された鍵がまったく送信されないことです。これにより、人質に取られるリスクも回避できます。たとえ盗聴者によって公開鍵が入手されたとしても、復号処理には離散対数の評価が含まれるため、簡単に復号できるものではありません。以下は、非対称暗号化の概略図です。

以上がPython クローラーの http および https プロトコルの詳細な説明 (画像とテキスト)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



