

mysql クエリは、select コマンドを limit パラメータと offset パラメータと組み合わせて使用し、指定された範囲内のレコードを読み取ります。この記事では、MySQL クエリ中にパフォーマンスに影響を与える過剰なオフセットの理由と最適化方法を紹介します。
1. テーブルを作成します
2. 1000000レコードを挿入します
3.
CREATE TABLE `member` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL COMMENT '姓名', `gender` tinyint(3) unsigned NOT NULL COMMENT '性别', PRIMARY KEY (`id`), KEY `gender` (`gender`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
<?php
$pdo = new PDO("mysql:host=localhost;dbname=user","root",'');for($i=0; $i<1000000; $i++){ $name = substr(md5(time().mt_rand(000,999)),0,10); $gender = mt_rand(1,2); $sqlstr = "insert into member(name,gender) values('".$name."','".$gender."')"; $stmt = $pdo->prepare($sqlstr); $stmt->execute();}
?>mysql> select count(*) from member;
+----------+| count(*) |
+----------+| 1000000 |
+----------+1 row in set (0.23 sec)mysql> select version(); +-----------+| version() | +-----------+| 5.6.24 | +-----------+1 row in set (0.01 sec)
mysql> select * from member where gender=1 limit 10,1; +----+------------+--------+| id | name | gender | +----+------------+--------+| 26 | 509e279687 | 1 | +----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 100,1; +-----+------------+--------+| id | name | gender | +-----+------------+--------+| 211 | 07c4cbca3a | 1 | +-----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 1000,1; +------+------------+--------+| id | name | gender | +------+------------+--------+| 1975 | e95b8b6ca1 | 1 | +------+------------+--------+1 row in set (0.00 sec)
セカンダリ インデックス (すべての性別 =1 ID を検索)。
主キーのみをクエリする場合は、違いを確認してください
mysql> select * from member where gender=1 limit 100000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 199798 | 540db8c5bc | 1 | +--------+------------+--------+1 row in set (0.12 sec)mysql> select * from member where gender=1 limit 200000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 399649 | 0b21fec4c6 | 1 | +--------+------------+--------+1 row in set (0.23 sec)mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.31 sec)
明らかに、主キーのみをクエリすると、すべてのフィールドをクエリする場合に比べて、実行効率が大幅に向上します。
すべてのフィールドをクエリする必要があります セカンダリインデックスは主キー値のみを検索しますが、他のフィールドの値を取得するにはデータブロックで読み取る必要があるためです。したがって、mysql は最初にデータ ブロックの内容を読み取り、次にオフセット操作を実行し、最後にスキップする必要がある前のデータを破棄して、後続のデータを返します。
確認済み
select * from member where gender=1 limit 300000,1;
再起動後、データ ページにアクセスしていないことがわかります。
すべてのフィールドをクエリし、バッファプールの内容を確認します
mysql> select id from member where gender=1 limit 300000,1; +--------+| id | +--------+| 599465 | +--------+1 row in set (0.09 sec)
この時点でバッファプール内のメンバーテーブルに1385データページと261インデックスページがあることがわかります時間。
mysqlを再起動してバッファプールをクリアし、主キーのみをクエリするテストを続行します
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; Empty set (0.04 sec)
したがって、mysql クエリの際に、過剰なオフセットがパフォーマンスに影響を与える理由は、主キー インデックスを介してデータ ブロックにアクセスする複数の I/O 操作によるものであることが確認できます。 (この問題があるのは InnoDB だけであり、MYISAM インデックス構造は InnoDB とは異なることに注意してください。セカンダリ インデックスはデータ ブロックを直接ポイントしているため、そのような問題はありません)。
InnoDB エンジンと MyISAM エンジンのインデックス構造の比較表
最適化方法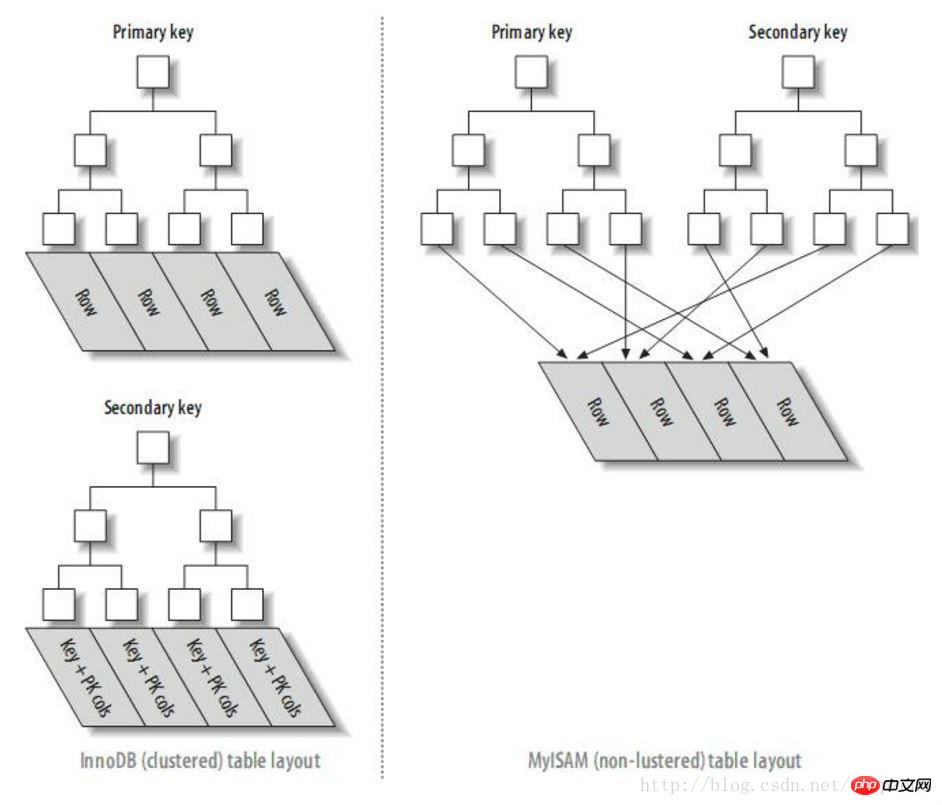
mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.38 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; +------------+----------+| index_name | count(*) | +------------+----------+| gender | 261 || PRIMARY | 1385 | +------------+----------+2 rows in set (0.06 sec)
この記事では、MySQL のクエリ時にパフォーマンスに影響を与える過度のオフセットの理由と最適化方法について説明します。関連コンテンツについては、PHP 中国語 Web サイトを参照してください。
関連するおすすめ:
以上がmysqlクエリ中にパフォーマンスに影響を与える過剰なオフセットの理由と最適化方法の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



