


この記事は主に Redis の面接の質問と分散クラスターを紹介します。必要な友達に参考にしてもらいます。1. Redis を使用するメリットは何ですか?
(1) HashMap と同様にデータがメモリに保存されるため高速です。 HashMap の利点は、検索と操作の計算量が O(1) であることです。  (2) 豊富なデータ型をサポートし、文字列をサポートします。 、list、set、sorted set、hash
(2) 豊富なデータ型をサポートし、文字列をサポートします。 、list、set、sorted set、hash
特別な推奨事項:
2020 Redis の面接の質問 (最新)
(3) redis はデータを永続化できます。問題と解決策: (1) マスターは、RDB メモリ スナップショットや AOF ログ ファイルなどの永続化作業を行わないことが最善です2 memcached と比較した Redis の利点は何ですか。 ? (1) memcached のすべての値は単純な文字列です。その代わりに、redis はより豊富なデータ型をサポートします。
(2) redis は memcached よりもはるかに高速です。
(2) データが重要な場合、スレーブは AOF バックアップを有効にする必要があります データとポリシーが設定されている1 秒に 1 回同期します
(3) マスターとスレーブのレプリケーションの速度と接続の安定性を考慮すると、マスターとスレーブが同じ LAN 内にあることが最適です
(4) 追加のデータを LAN に追加しないようにしてください。非常にストレスのかかるマスター データベース スレーブ ライブラリ
4. MySQL には 2,000 万のデータがありますが、redis には 200,000 のデータしか保存されません
関連知識: Redis メモリ データ セットのサイズが一定まで増加した場合。サイズ、データの削除戦略が実装されます。 Redis は 6 つのデータ削除戦略を提供します:
voltile-lru: データセット (server.db[i].expires) から最も最近使用されていないデータを選択し、有効期限を設定して削除します
volatile-random: 有効期限を設定して、データ セット (server.db[i].expires) から削除するデータをランダムに選択します。
allkeys-lru: データ セット (server.db[i) から最新のデータを選択します。 ].dict) 最も使用頻度の低いデータの削除
allkeys-random: データセット (server.db[i].dict) からデータを任意に選択して削除します
no-enviction (エビクション): データのエビクションを禁止します
1). 保存方法
Memecache はすべてのデータをメモリに保存します。停電後はデータがメモリ サイズを超えることはありません。
Redis は部分的にハードディスクに保存されるため、データの永続性が保証されます。
2)、データサポートタイプ
Memcache のデータタイプのサポートは比較的単純です。
Redis には複雑なデータ型があります。
3) 使用される基礎となるモデルが異なります。
クライアントと通信するための基礎となる実装メソッドとアプリケーション プロトコルが異なります。
一般的なシステムがシステム関数を呼び出すと、移動やリクエストに一定の時間がかかるため、Redis は VM メカニズムを自身で直接構築します。
4)、値のサイズ
Redis は最大 1GB に達しますが、memcache はわずか 1MB です
1) マスターはメモリ スナップショットを書き込み、save コマンドは rdbSave 関数をスケジュールします。これにより、スナップショットが比較的大きい場合、パフォーマンスへの影響が非常に大きくなり、サービスが一時停止されます。したがって、 Master のメモリ スナップショットを書き込まないことをお勧めします。
2) マスター AOF の永続化。AOF ファイルが書き換えられない場合、この永続化方法はパフォーマンスに最小限の影響を与えますが、AOF ファイルが過剰になるとマスターの再起動の回復速度に影響を与えます。マスターでは、メモリ スナップショットや AOF ログ ファイルなどの永続化作業を行わないことが最善です。特に、データが重要な場合は、スレーブで AOF バックアップ データを有効にする必要があります。 1 秒に 1 回同期します。
3).マスターは BGREWRITEAOF を呼び出して AOF ファイルを書き換えます。AOF は書き換え中に大量の CPU リソースとメモリ リソースを占有するため、過剰なサービス負荷が発生し、サービスが短期間停止されます。
4). Redis マスター/スレーブ レプリケーションのパフォーマンスの問題。マスター/スレーブ レプリケーションの速度と接続の安定性を考慮すると、スレーブとマスターが同じ LAN にあることが最適です
Redis はすべての用途に最適です。メモリ内のデータのシナリオでは、Redis は永続化機能も提供しますが、実際にはディスクベースの機能に近く、従来の意味での永続化とはまったく異なります。 Redis は Memcached の拡張版のようなものだと思われますが、どのような場合に Memcached を使用し、どのような場合に Redis を使用するのでしょうか?
Redis と Memcached の違いを単純に比較すると、ほとんどの人は次のような意見を抱くでしょう。 Redis は、単純な k/v 型データをサポートするだけでなく、リスト、セット、zset、ハッシュなどのデータ構造のストレージも提供します。
2. Redis はデータ バックアップ、つまりマスター/スレーブ モードでのデータ バックアップをサポートします。
3. Redis はデータの永続化をサポートしており、データをディスク上のメモリに保持し、再起動時に再度ロードして使用できます。
(1)、セッション キャッシュ
(2)、フル ページ キャッシュ (FPC)
基本的なセッション トークンに加えて、Redis は非常にシンプルな FPC プラットフォームも提供します。一貫性の問題に戻りますが、Redis インスタンスが再起動されても、ディスクの永続性により、ユーザーはページの読み込み速度が低下することはありません。これは、PHP ローカル FPC と同様に、大きな改善です。
再び Magento を例に挙げると、Magento は Redis をフルページ キャッシュ バックエンドとして使用するためのプラグインを提供します。
さらに、WordPress ユーザー向けに、Pantheon には非常に優れたプラグイン wp-redis があり、閲覧したページをできるだけ早く読み込むのに役立ちます。
(3)、キュー
メモリ ストレージ エンジンの分野における Redis の大きな利点の 1 つは、Redis がリストおよびセット操作を提供することです。これにより、Redis を優れたメッセージ キュー プラットフォームとして使用できるようになります。 Redis によってキューとして使用される操作は、ローカル プログラミング言語 (Python など) のリストのプッシュ/ポップ操作に似ています。
Google で「Redis キュー」をすぐに検索すると、すぐに多数のオープンソース プロジェクトが見つかります。これらのプロジェクトの目的は、Redis を使用して、さまざまなキューのニーズを満たす非常に優れたバックエンド ツールを作成することです。たとえば、Celery には Redis をブローカーとして使用するバックエンドがあります。ここから確認できます。
(4)、Leaderboard/Counter
Redis は、メモリ内の数値を増減する操作を非常に適切に実装しています。 Set と Sorted Set を使用すると、これらの操作を非常に簡単に実行できます。Redis はこれら 2 つのデータ構造を提供するだけです。したがって、ソートされたセットから上位 10 人のユーザーを取得したいとします。それらを「user_scores」と呼びます。次のようにするだけです:
もちろん、これはユーザーに基づいていることを前提としています。スコアはソートされています。昇順。ユーザーとユーザーのスコアを返したい場合は、次のように実行する必要があります:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games は Ruby で実装されており、そのランキングは Redis を使用してデータを保存します。ここで見ることができます。
(5)、パブリッシュ/サブスクライブ
最後 (そしてもちろん重要なこと) は、Redis のパブリッシュ/サブスクライブ機能です。パブリッシュ/サブスクライブには実際に多くの使用例があります。人々がこれをソーシャル ネットワーク接続で使用したり、パブリッシュ/サブスクライブ ベースのスクリプトのトリガーとして使用したり、Redis のパブリッシュ/サブスクライブ機能を使用してチャット システムを構築したりしているのを見てきました。 (いいえ、これは本当です。ぜひチェックしてみてください。)
Redis が提供するすべての機能の中で、これはユーザーに複数の機能を提供しますが、最も人々に好まれない機能であると感じます。
高可用性(高可用性)とは、サーバーがサービスを停止してもビジネスやユーザーに影響を与えないことを意味します。 サービスが停止する理由としては、ネットワークカード、ルーター、コンピュータ室、CPU負荷の過剰、メモリオーバーフロー、自然災害などの予期せぬ理由が考えられます。多くの場合、単一点問題とも呼ばれます。
(1) 単一点の問題を解決するには、主に 2 つの方法があります:
アクティブ方法とバックアップ方法
通常、これは 1 つのホストと 1 つ以上のバックアップ マシンです。通常の状況では、ホストは外部にサービスを提供し、データを同期します。スタンバイ マシンに対しては、メイン マシンがダウンすると、スタンバイ マシンがすぐにサービスを開始します。
Keepalived は Redis HA で一般的に使用され、ホストとバックアップ マシンが同じ仮想 IP を外部に提供できるようにし、通常の期間、ホストは仮想 IP を介してデータ操作を実行します。停止後、VIP は自動的にバックアップ マシンに移動します。
利点は、クライアントに影響を与えず、引き続きVIPを通じて操作できることです。
欠点も明らかで、ほとんどの場合、バックアップ マシンは使用されずに無駄になります。
マスタースレーブ方式
このアプローチは、1 つのマスターと複数のスレーブを採用し、マスターとスレーブの間でデータを同期します。 マスターがダウンすると、選挙アルゴリズム (Paxos、Raft) を通じてスレーブから新しいマスターが選出され、外部へのサービスの提供を継続します。マスターが回復すると、スレーブとして再接続されます。
マスター/スレーブのもう 1 つの目的は、読み取りと書き込みを分離することです。これは、単一マシンの読み取りと書き込みの負荷が高すぎる場合の一般的な解決策です。 そのホストの役割は、書き込み操作または少量の読み取りのみを提供し、負荷分散アルゴリズムを通じて冗長な読み取り要求を単一または複数のスレーブ サーバーにオフロードします。
欠点は、ホストがダウンした後、スレーブが新しいマスターとして選出されるものの、外部に提供される IP サービス アドレスが変更されるため、クライアントに影響が及ぶことです。 この状況を解決するには、追加の作業が必要になります。ホスト アドレスが変更されると、クライアントは新しいアドレスを受信した後、新しいアドレスを使用して新しいリクエストを送信し続けます。
(2) データの同期
マスター/スレーブであってもマスター/スレーブであっても、データの同期の問題は次の 2 つの状況に分けられます。
同期方法: ホストがクライアントから書き込み操作を受信したとき。スレーブ マシンも書き込みに成功すると、マスターはクライアントに成功を返します。これは、強力なデータ整合性とも呼ばれます。 明らかに、この方法のパフォーマンスは大幅に低下します。スレーブ マシンが多数ある場合、マスターが特定のスレーブ マシンを同期した後、スレーブ マシンは他のスレーブへのデータ配信を同期する必要はありません。これにより、ホスト マシンのパフォーマンス共有が向上します。 この構成は Redis でサポートされており、1 つのマスターと 1 つのスレーブが同時に、このスレーブは他のスレーブのマスターとして機能します。
非同期モード: 書き込み操作を受信した後、ホストは直接成功を返し、バックグラウンドで非同期方法でデータをスレーブに同期します。 この種の同期パフォーマンスは比較的良好ですが、たとえば、非同期同期プロセス中にホストが突然クラッシュした場合、この方法は弱いデータ整合性とも呼ばれます。
Redis のマスターとスレーブの同期は非同期方式を使用するため、少量のデータが失われるリスクがあります。結果整合性と呼ばれる弱い整合性の特殊なケースもあります。詳細については、CAP 原則と整合性モデルを参照してください。
(3) ソリューションの選択
keepalived ソリューションは設定が簡単で人件費が低く、データ量が少なく、負荷が低い場合に推奨されます。 データ量が比較的多く、あまり多くのマシンを無駄にしたくない場合、また、ダウンタイム後にアラーム、ロギング、データ移行などのカスタマイズされた措置を講じたい場合は、使用することをお勧めします。マスタースレーブ方式と一致するため、通常は管理および監視センターもあります。
ダウンタイム通知は、クライアント コンポーネントに統合することも、個別に抽出することもできます。 Redis 公式 Sentinel は自動フェイルオーバーや通知などをサポートしています。詳細については、低コストで高可用性のソリューション設計 (4) を参照してください。
論理図: 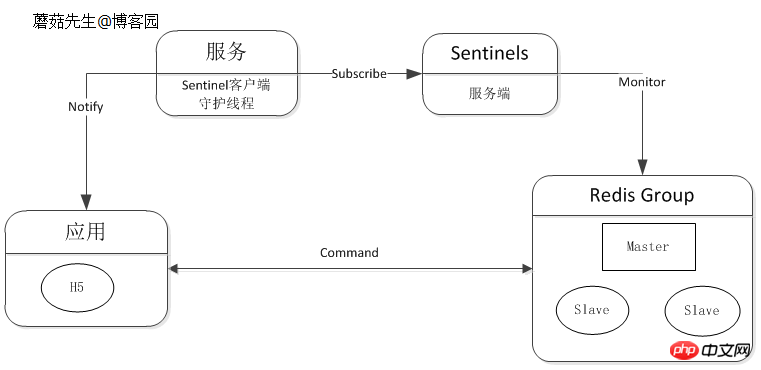
分散(分散)とは、業務量やデータ量が増加した場合に、サーバーの数を任意に増減することで問題を解決できることを意味します。
クラスター時代
少なくとも 2 つの Redis サーバーをデプロイして小規模クラスターを形成します。これには 2 つの主な目的があります:
高可用性: ホストがハングアップした後の自動フェイルオーバー。フロントエンド サービスがユーザーに影響を与えないようにします。
読み取りと書き込みの分離: 読み取りプレッシャーをホストからスレーブにオフロードします。
クライアント コンポーネントで負荷分散を実現でき、さまざまなサーバーの動作条件に応じて、さまざまな割合の読み取りリクエストのプレッシャーを共有できます。
ロジック図: 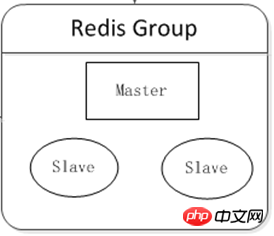
キャッシュされたデータの量が増加し続けると、単一マシンのメモリでは十分ではなくなり、データを複数の部分に分割して複数のマシンに分散する必要がありますサーバー。
データはクライアント上で断片化できます。データ断片化アルゴリズムの詳細については、「C# Consistent Hash の詳細な説明」と「C# Virtual Bucket Fragmentation」を参照してください。
ロジック図: 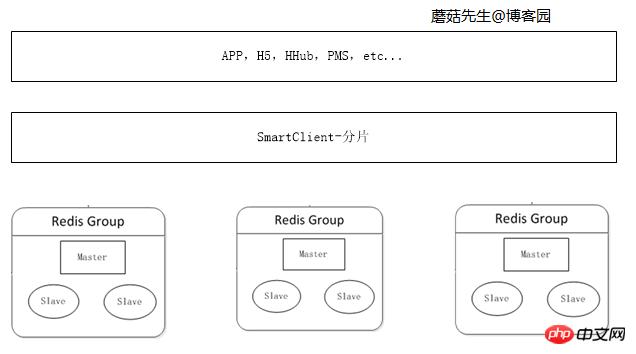
大規模分散クラスターの時代
データ量が増加し続けると、アプリケーションはさまざまなシナリオでのビジネスに基づいて、対応する分散クラスターを申請できます。 この中で最も重要な部分はキャッシュ管理であり、最も重要な部分はプロキシ サービスの追加です。 アプリケーションは読み取りと書き込みのためにプロキシを介して実際の Redis サーバーにアクセスします。これには次の利点があります。
管理が難しくリスクを引き起こす、ますます多くのクライアントが Redis サーバーに直接アクセスすることを回避します。
電流制限、認可、シャーディングなど、対応するセキュリティ対策をプロキシ層で実装できます。
クライアント側でますます多くのロジック コードを回避します。これは肥大化するだけでなく、アップグレードが面倒になります。
プロキシ層はステートレスであり、クライアントにとってプロキシへのアクセスはスタンドアロン Redis へのアクセスと同じです。
現在、ホスト企業はクライアント コンポーネントとプロキシの 2 つのソリューションを使用しています。これは、プロキシを使用すると特定のパフォーマンスに影響するためです。 プロキシ実装に対応するソリューションには、Twitter の Twemproxy や Wandoujia の codis などがあります。
ロジック図: 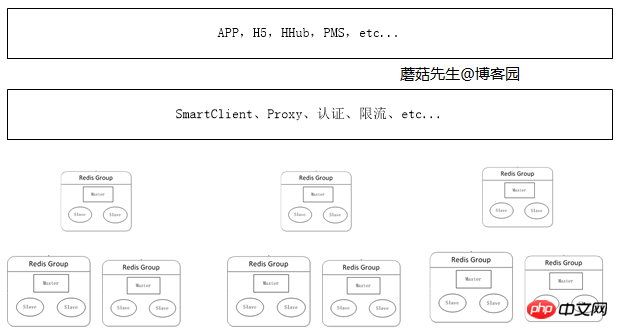
分散キャッシュの後にクラウド サービス キャッシュが続きます。これにより、各アプリケーションは、淘宝網 OCS クラウド サービス キャッシュなど、独自のサイズとトラフィック プランを適用できます。
分散キャッシュに必要な実装コンポーネントは次のとおりです:
キャッシュの監視、移行、および管理センター。
カスタム クライアント コンポーネント、上の図の SmartClient。
ステートレスなプロキシ サービス。
N サーバー。
関連する学習の推奨事項: redis ビデオ チュートリアル
関連する学習の推奨事項: mysql ビデオ チュートリアル
以上がRedis の面接の質問と分散クラスターの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



