


この記事では主に tensorflow にデータを読み込む 3 つの方法を詳しく紹介しますので、参考にしてください。一緒に見てみましょう
Tensorflow データを読み取るには 3 つの方法があります:
プリロードされたデータ: プリロードされたデータ
フィード: Python がデータを生成し、そのデータをバックエンドにフィードします。
ファイルから読み取る: ファイルから直接読み取る
これら 3 つの読み取り方法の違いは何ですか? まず、TensorFlow (TF) がどのように機能するかを知る必要があります。
TF のコアは C++ で書かれており、その利点は高速に実行されることですが、欠点は呼び出しが柔軟性に欠けることです。 Python はその逆であるため、両方の言語の利点を組み合わせています。計算に関与するコア演算子と操作フレームワークは C++ で記述され、API は Python 用に提供されます。 Python はこれらの API を呼び出し、トレーニング モデル (グラフ) を設計し、設計されたグラフを実行のためにバックエンドに送信します。つまり、Python の役割は設計であり、C++ の役割は実行です。
1. データのプリロード:
import tensorflow as tf # 设计Graph x1 = tf.constant([2, 3, 4]) x2 = tf.constant([4, 0, 1]) y = tf.add(x1, x2) # 打开一个session --> 计算y with tf.Session() as sess: print sess.run(y)
2. Python がデータを生成し、そのデータをバックエンドにフィードします
import tensorflow as tf
# 设计Graph
x1 = tf.placeholder(tf.int16)
x2 = tf.placeholder(tf.int16)
y = tf.add(x1, x2)
# 用Python产生数据
li1 = [2, 3, 4]
li2 = [4, 0, 1]
# 打开一个session --> 喂数据 --> 计算y
with tf.Session() as sess:
print sess.run(y, feed_dict={x1: li1, x2: li2}) 説明: ここに x 1、x2は単なるプレースホルダーであり、特定の値はありません。では、実行時に値をどこで取得するのでしょうか?このとき、sess.run() の feed_dict パラメータを使用して、Python によって生成されたデータをバックエンドにフィードし、y を計算する必要があります。
これら 2 つのソリューションの欠点:
1. プリロード: データをグラフに直接埋め込み、グラフをセッションに渡して実行します。データ量が比較的大きい場合、グラフ送信では効率の問題が発生します。
2. プレースホルダーを使用してデータを置き換え、実行時にデータを入力します。
最初の 2 つの方法は非常に便利ですが、フィーディングの場合でも、データ型の変換など、中間リンクの増加は小さなオーバーヘッドではありません。最善の解決策は、Graph でファイル読み取りメソッドを定義し、TF にファイルからデータを読み取り、使用可能なサンプル セットにデコードさせることです。
3. ファイルからの読み込みとは、簡単に言えば、データ読み込みモジュールの図を設定することです
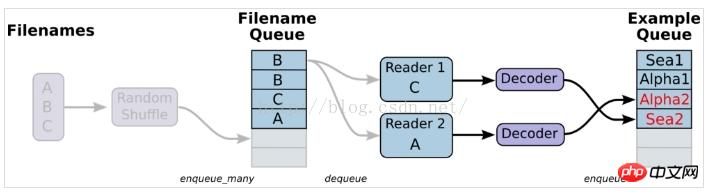
$ echo -e "Alpha1,A1\nAlpha2,A2\nAlpha3,A3" > A.csv $ echo -e "Bee1,B1\nBee2,B2\nBee3,B3" > B.csv $ echo -e "Sea1,C1\nSea2,C2\nSea3,C3" > C.csv
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
#example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
print example.eval(),label.eval()
coord.request_stop()
coord.join(threads)Alpha1 A2解決策: tf.train を使用します。 shuffle_batch を実行すると、生成された結果が対応することができます。Alpha3 B1
Bee2 B3
Sea1 C2
Sea3 A1
Alpha2 A3
Bee1 B2
Bee3 C1
Sea2 C3
Alpha1 A2
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。
#Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。
#Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
print example_batch.eval(), label_batch.eval()
coord.request_stop()
coord.join(threads)['Alpha1' 'Alpha2' 'Alpha3' 'Bee1 ' 'Bee2 '] ['B3' 'C1' 'C2' 'C3' 'A1']4. 複数のリーダー、複数のサンプル['Alpha2' 'Alpha3' 'Bee1' 'Bee2' 'Bee3'] ['C1' 'C2' 'C3' 'A1' 'A2']
['Alpha3' 'Bee1' 'Bee2' 'Bee3' 'Sea1'] ['C2' 'C3' 'A1' 'A2' 'A3']
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定义了多种解码器,每个解码器跟一个reader相连
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
#num_epoch: 设置迭代数
filename_queue = tf.train.string_input_producer(filenames, shuffle=False,num_epochs=3)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定义了多种解码器,每个解码器跟一个reader相连
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=1)
#初始化本地变量
init_local_op = tf.initialize_local_variables()
with tf.Session() as sess:
sess.run(init_local_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop():
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
except tf.errors.OutOfRangeError:
print('Epochs Complete!')
finally:
coord.request_stop()
coord.join(threads)
coord.request_stop()
coord.join(threads)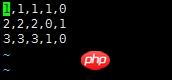
说明:对于该数据,前三列代表的是feature,因为是分类问题,后两列就是经过one-hot编码之后得到的label
使用队列读取该csv文件的代码如下:
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(value,record_defaults=record_defaults)
features = tf.pack([col1, col2, col3])
label = tf.pack([col4,col5])
example_batch, label_batch = tf.train.shuffle_batch([features,label], batch_size=2, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)输出结果如下:
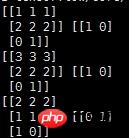
说明:
record_defaults = [[1], [1], [1], [1], [1]]
代表解析的模板,每个样本有5列,在数据中是默认用‘,'隔开的,然后解析的标准是[1],也即每一列的数值都解析为整型。[1.0]就是解析为浮点,['null']解析为string类型
相关推荐:
TensorFlow入门使用 tf.train.Saver()保存模型
关于Tensorflow中的tf.train.batch函数
以上がtensorflow にデータをロードする 3 つの方法の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



