


この記事では、主に PHP でのハフマン エンコーディング/デコーディングの実装について紹介します。必要な友人はそれを参照してください。
ハフマン エンコーディングはデータ圧縮アルゴリズムです。一般的に使用される zip 圧縮の中核はハフマン エンコーディングであり、HTTP/2 では、ハフマン エンコーディングは HTTP ヘッダーの圧縮に使用されます。
この記事では、PHP を使用してハフマン エンコードとデコードを練習します。
ハフマン エンコーディングの最初のステップは、PHP の組み込み関数 count_chars() を使用してこれを行うことです。 count_chars() 就可以做到:
$input = file_get_contents('input.txt');$stat = count_chars($input, 1);
接下来根据统计结果构造Huffman树,构造方法在 Wikipedia 有详细的描述。这里用PHP写了一个简易版的:
$huffmanTree = [];foreach ($stat as $char => $count) { $huffmanTree[] = [ 'k' => chr($char), 'v' => $count, 'left' => null, 'right' => null,
];
}// 构造树的层级关系,思想见wiki:https://zh.wikipedia.org/wiki/%E9%9C%8D%E5%A4%AB%E6%9B%BC%E7%BC%96%E7%A0%81$size = count($huffmanTree);for ($i = 0; $i !== $size - 1; $i++) {
uasort($huffmanTree, function ($a, $b) {
if ($a['v'] === $b['v']) { return 0;
} return $a['v'] < $b['v'] ? -1 : 1;
}); $a = array_shift($huffmanTree); $b = array_shift($huffmanTree); $huffmanTree[] = [ 'v' => $a['v'] + $b['v'], 'left' => $b, 'right' => $a,
];
}$root = current($huffmanTree);经过计算之后,$root 就会指向 Huffman 树的根节点
有了 Huffman 树,就可以生成用于编码的字典:
function buildDict($elem, $code = '', &$dict) {
if (isset($elem['k'])) { $dict[$elem['k']] = $code;
} else {
buildDict($elem['left'], $code.'0', $dict);
buildDict($elem['right'], $code.'1', $dict);
}
}$dict = [];
buildDict($root, '', $dict);运用字典将文件内容进行编码,并写入文件。将Huffman编码写入文件的有几个注意的地方:
将编码字典和编码内容一起写入文件后,就没法区分他们的边界了,因此需要在文件开始写入他们各自占用的字节数
PHP提供的 fwrite()
$dictString = serialize($dict);// 写入字典和编码各自占用的字节数$header = pack('VV', strlen($dictString), strlen($input));
fwrite($outFile, $header);// 写入字典本身fwrite($outFile, $dictString);// 写入编码的内容$buffer = '';$i = 0;while (isset($input[$i])) { $buffer .= $dict[$input[$i]]; while (isset($buffer[7])) { $char = bindec(substr($buffer, 0, 8));
fwrite($outFile, chr($char)); $buffer = substr($buffer, 8);
} $i++;
}// 末尾的内容如果没有凑齐 8-bit,需要自行补齐if (!empty($buffer)) { $char = bindec(str_pad($buffer, 8, '0'));
fwrite($outFile, chr($char));
}
fclose($outFile);<?php$content = file_get_contents('a.out');// 读出字典长度和编码内容长度$header = unpack('VdictLen/VcontentLen', $content);$dict = unserialize(substr($content, 8, $header['dictLen']));$dict = array_flip($dict);$bin = substr($content, 8 + $header['dictLen']);$output = '';$key = '';$decodedLen = 0;$i = 0;while (isset($bin[$i]) && $decodedLen !== $header['contentLen']) { $bits = decbin(ord($bin[$i])); $bits = str_pad($bits, 8, '0', STR_PAD_LEFT); for ($j = 0; $j !== 8; $j++) { // 每拼接上 1-bit,就去与字典比对是否能解码出字符
$key .= $bits[$j]; if (isset($dict[$key])) { $output .= $dict[$key]; $key = ''; $decodedLen++; if ($decodedLen === $header['contentLen']) { break;
}
}
} $i++;
}echo $output;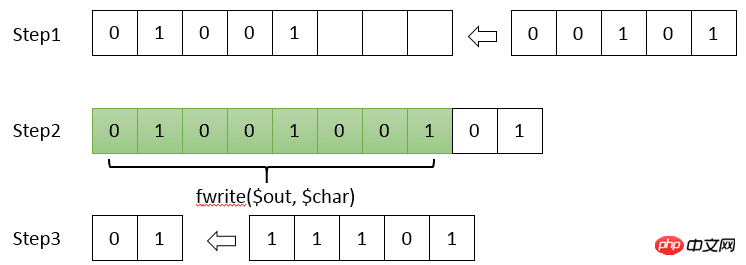 計算後、
計算後、$root はハフマン ツリーのルート ノードを指しますハフマンを使用ツリー、エンコード用の辞書を生成できます:
rrreeeエンコーディング辞書とエンコーディングコンテンツを一緒にファイルに書き込んだ後は、それらの境界を区別することができないため、それらをファイルの先頭のバイト数
fwrite() 関数は、一度に 8 ビット (1 バイト) または 8 ビットの整数倍を書き込むことができます。ただし、ハフマン エンコーディングでは、文字は 1 ビットのみで表現される可能性があり、PHP はファイルに 1 ビットのみを書き込む操作をサポートしていません。したがって、エンコーディングを自分で結合し、8 ビットが取得されるたびにのみファイルを書き込む必要があります。 2 番目の項目と同様に、最終的なファイル サイズは 8 ビットの整数倍でなければなりません。したがって、エンコード全体のサイズが 8001 ビットの場合、7 0
rrreee
デコードそのため、デコード処理中に、デコードされた文字数がドキュメントの長さに達すると、デコードは停止します。ハフマン エンコードは比較的単純です。最初にエンコード辞書を読み取り、次に辞書に従って元の文字をデコードします。
デコードプロセスで注意する必要がある問題があります。エンコードプロセス中にファイルの最後にいくつかの 0 ビットを追加したため、これらの 0 ビットがたまたま特定のファイルのエンコードであった場合、辞書に文字が含まれていない場合、デコードエラーが発生します。
rrreee
テスト
ハフマンエンコードWikiページのHTMLコードをローカルに保存し、ハフマンエンコードテストを実行しました。テスト結果:
以上がPHP はハフマン エンコーディング/デコーディングを実装しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



