


この記事ではNodeJSを使ってクローラーを学ぶ方法を中心に、「恥ずかしいこと大百科」をクロールすることで使い方や効果を解説していますので、皆さんのお役に立てれば幸いです。
1. 序文分析
私たちは通常、クローラーを実装するために Python/.NET 言語を使用しますが、フロントエンド開発者として、当然 NodeJS に習熟する必要があります。 NodeJS 言語を使用して、恥ずかしいもの百科のクローラーを実装してみましょう。また、この記事で使用されているコードの一部は es6 構文です。
このクローラの実装に必要な依存ライブラリは以下の通りです。
リクエスト: get メソッドまたは post メソッドを使用して、Web ページのソース コードを取得します。 Cheerio: Web ページのソース コードを解析し、必要なデータを取得します。
この記事では、まずクローラーに必要な依存関係ライブラリとその使用法を紹介し、次にこれらの依存関係ライブラリを使用して、恥ずかしいこと百科事典の Web クローラーを実装します。
2. リクエスト ライブラリ
request は、非常に強力で使いやすい軽量の http ライブラリです。これを使用して HTTP リクエストを実装でき、HTTP 認証、カスタム リクエスト ヘッダーなどをサポートします。以下に、リクエスト ライブラリの関数の一部を紹介します。
次のように request モジュールをインストールします。
npm install request
request がインストールされたら、request を使用して Baidu Web ページをリクエストできるようになります。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})options パラメーターが設定されていない場合、リクエスト メソッドはデフォルトで get リクエストになります。 request オブジェクトを使用する具体的な方法は次のとおりです:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});しかし、URL から取得した HTML ソース コードを直接リクエストしても、必要な情報が得られないことがよくあります。一般に、リクエスト ヘッダーと Web ページのエンコードを考慮する必要があります。
Web ページのリクエスト ヘッダーと Web ページのエンコーディング
以下では、Web ページのリクエスト ヘッダーを追加し、リクエスト時に正しいエンコーディングを設定する方法について説明します。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})options パラメータを設定し、headers 属性を追加してリクエスト ヘッダーを設定します。encoding 属性を追加して Web ページのエンコードを設定します。エンコーディング: null の場合、get リクエストによって取得されるコンテンツは Buffer オブジェクト、つまりボディは Buffer オブジェクトであることに注意してください。
上記で紹介した機能は、以下のニーズを満たすのに十分です
3. Cheerioライブラリ
cheerioは、軽くて速く、学習しやすいという特徴で開発者に愛されているサーバーサイドのJQueryです。 Jquery の基礎知識があれば、cheerio ライブラリを学ぶのは非常に簡単です。 Web ページ内の要素をすばやく見つけることができ、そのルールは Jquery の要素を見つける方法と同じです。また、HTML 内の要素の内容を変更して、非常に便利な形式でデータを取得することもできます。以下では主に、Web ページ内の要素を素早く見つけてその内容を取得する Cherio を紹介します。
まずcheerioライブラリをインストールします
npm install cheerio
以下はコードの一部であり、その後cheerioライブラリの使い方を説明します。ブログパークのトップページを解析し、各ページの記事タイトルを抽出します。
まず、ブログパークのホームページを分析します。以下に示すように:
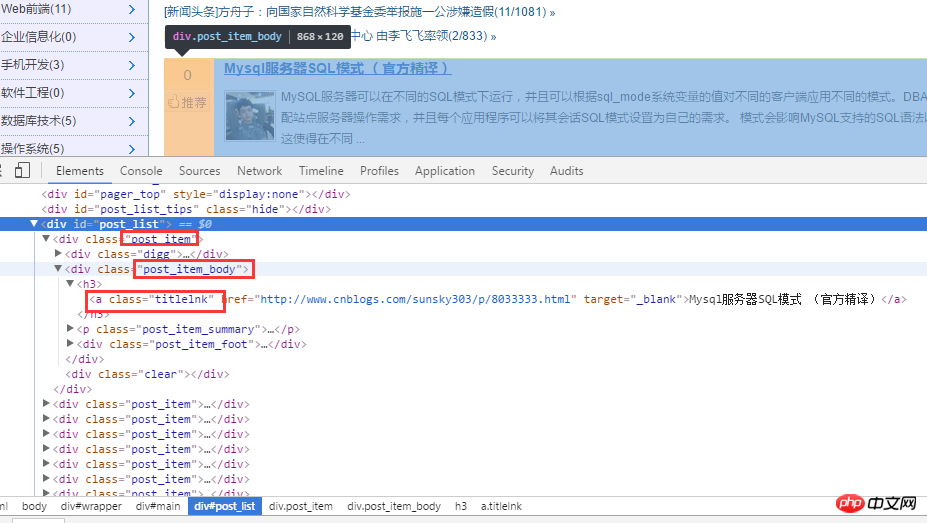
HTML ソース コードを分析した後、まず .post_item を通じてすべてのタイトルを取得し、次に各 .post_item を分析し、a.titlelnk を使用して各タイトルの a タグを照合します。以下はコードを通じて実装されます。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});もちろん、cheerio ライブラリはチェーン呼び出しもサポートしており、上記のコードは次のように書き換えることもできます。
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);上記のコードは非常に単純なので、言葉で詳しく説明しません。以下に、より重要だと思われる点をいくつかまとめます。
find() メソッドを使用して、ノード セット A を取得します。 A セット内の要素をルート ノードとして再度使用して、その子ノードを見つけ、子要素のコンテンツと属性を取得する場合は、 $ を実行する必要があります。 (A セット [i] の子要素の A) ラッパー。上記の $(ele) と同様です。上記のコードでは$(ele)を使用していますが、実際には$(this)も使用できます。es6のarrow関数を使用しているため、各メソッド内のコールバック関数のthisポインタが変更されています。したがって、私は $(ele) を使用します。cheerio ライブラリは、上記の $('.post_item').find('a.titlelnk') などのチェーン呼び出しもサポートしています。cheerio オブジェクト A がメソッド find を呼び出すことに注意してください。 ()。A がコレクションの場合、A コレクション内の子要素ごとに find() メソッドが呼び出され、結果の共用体が戻されます。 A が text() を呼び出すと、A のコレクション内の各子要素が text() を呼び出し、すべての子要素の内容の結合である文字列を返します (直接結合、区切り文字なし)。
最後に、私がよく使用する方法をいくつかまとめます。
first() last() Children([selector]): このメソッドは find と似ていますが、このメソッドは子ノードのみを検索するのに対し、find は子孫ノード全体を検索する点が異なります。
4. 恥ずかしい百科事典のクローラー
上記の request クラス ライブラリと Cheerio クラス ライブラリの紹介を通して、これら 2 つのライブラリを使って恥ずかしい百科事典のページをクロールしてみましょう。
1. プロジェクト ディレクトリに新しい httpHelper.js ファイルを作成し、URL から Encyclopedia of Embarrasssing Things の Web ページのソース コードを取得します。コードは次のとおりです。新しい Splider.js ファイルを作成し、Encyclopedia of Embarrasssing Things の Web コードを分析し、必要な情報を抽出し、URL の ID を変更してさまざまなページからデータをクロールするロジックを構築します。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('p');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:

源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
5. 总结
通过实现一个完整的爬虫功能,加深自己对 Node 的理解,且实现的部分语言都是使用 es6 的语法,让自己加快对 es6 语法的学习进度。另外,在这次实现中,遇到了 Node 的异步控制的知识,本文是采用的是 async 和 await 关键字,也是我最喜欢的一种,然而在 Node 中,实现异步控制有好几种方式。关于具体的方式以及原理,有时间再进行总结。
相关推荐:
以上がNodeJS Encyclopedia クローラーのサンプル チュートリアルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



